
– Tato, a mogę zabrać na wycieczkę pięć pluszaków?
– Kochanie, ustaliliśmy, że maksymalnie weźmiesz dwie maskotki , aby wszystkie Ci się zmieściły. Inaczej nie wejdzie do autka sto par butów i sukienek Twojej mamusi – powiedziałem z przekąsem spoglądając na żonę.
– Ale nie wiem, które wybrać…
– Hmm…zastanów się nad kilkoma cechami, które je opisują: wygląd, rodzaj, jak się nimi bawisz, które najbardziej lubisz. Potem wyobraź sobie, która gdzie jest i może weź te, które najbardziej się różnią.
– Może rzeczywiście nie potrzebuję całej rodziny Pand. Zostawię tylko najmłodszą. A z sióstr Anny i Elzy wezmę tylko Elzę, bo ma moc zamieniania wszystkiego w lód.
– Super! Gratuluję Kochanie, właśnie wyobrażając sobie to zobrazowałaś sobie w głowie, że te trzy pandy są koło siebie a siostry bliżej siebie i z każdej z tych grup wybrałaś po jednej zabawce.
Wyobraźmy sobie, że mamy przed sobą banki w Polsce opisane przez kilka cech: liczba klientów, liczba aktywnych klientów, liczba klientów z aktywnym kontem, liczba kart debetowych, liczba klientów mobilnych, liczba placówek. Jestem przekonany, że na podstawie intuicji każdy z nas jest w stanie przypuścić, że kategoria liczba klientów z aktywnym kontem będzie skorelowana z liczbą kart debetowych. Tak samo w wielu przypadkach liczba klientów będzie powiązana z liczbą placówek (choć czasami możemy się pozytywnie zdziwić). Po to aby nie powielać niektórych informacji i zyskać lepszą przejrzystość można zamienić dwie zmienne na jedną tak zwaną składową.
Czym jest analiza głównych składowych?
Analiza składowych głównych (PCA) to najbardziej popularny algorytm redukcji wymiarów. W ogólnym skrócie polega on na rzutowaniu danych do przestrzeni o mniejszej liczbie wymiarów tak, aby jak najlepiej zachować strukturę danych.
Służy głównie do redukcji zmiennych opisujących dane zjawisko oraz odkrycia ewentualnych prawidłowości między cechami. Dokładna analiza składowych głównych umożliwia wskazanie tych zmiennych początkowych, które mają duży wpływ na wygląd poszczególnych składowych głównych czyli tych, które tworzą grupę jednorodną.
Idea głównych składowych
Analiza PCA opiera się o wyznaczanie osi zachowującej największą wartość wariancji zbioru uczącego. Składowe wyznaczamy jako kombinacje liniową badanych zmiennych.
Idea tworzenia kolejnych składowych polega na tym, że:
- kolejne składowe nie są skorelowane ze sobą,
- mają na celu zmaksymalizować zmienność, która nie została wyjaśniona przez poprzednią składową.
W celu wyszukiwania głównych składowych zbioru korzysta się z techniki faktoryzacji macierzy, zwanej rozkładem według wartości osobliwych (ang. singular value decomposition, SVD). Technika ta rozkłada macierz danych na iloczyn skalarny.
Dobra, ale o co w tym chodzi?
Wyobraźmy sobie, że mamy dwie zmienne opisujące jakieś zjawisko. Weźmy sobie dla przykładu kilka banków i opiszmy je za pomocą dwóch charakterystyk:
- Liczba placówek, czyli ile dany Bank ma placówek w całej Polsce.
- Liczba etatów, czyli ile osób jest zatrudnionych w danym Banku na pełen etat.
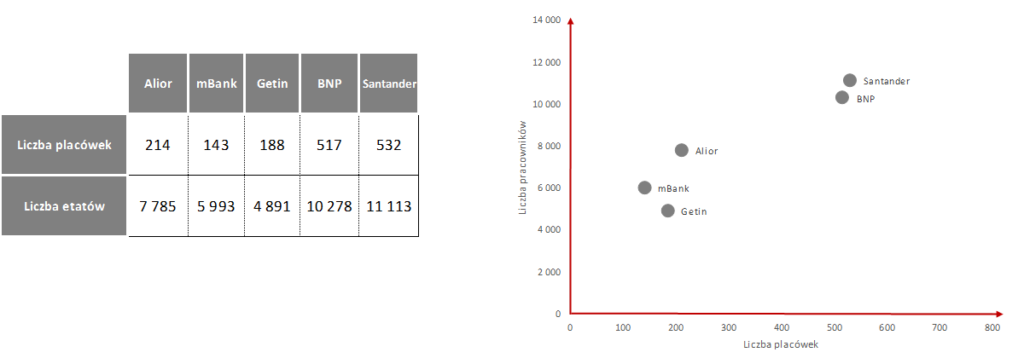
W pierwszym kroku wyliczamy średnie dla obu cech:


Teraz możemy przesunąć układ współrzędnych w „środek danych”, aby można było szukać najlepszej płaszczyzny do zrzutowania danych.

Teraz szukamy najlepszego rzutu na płaszczyznę.

Zagadnienie może wydawać się skomplikowane. Jednak warto zauważyć jedną ciekawą zależność.

Poniżej możecie zauważyć trójkąt prostokątny, zatem można skorzystać z mojego ulubionego twierdzenia z podstawówki-twierdzenia Pitagorasa.

Zatem trzeba znaleźć krzywą, która maksymalizuje sumę wszystkich kwadratów odległości punktów od początku układu współrzędnych.
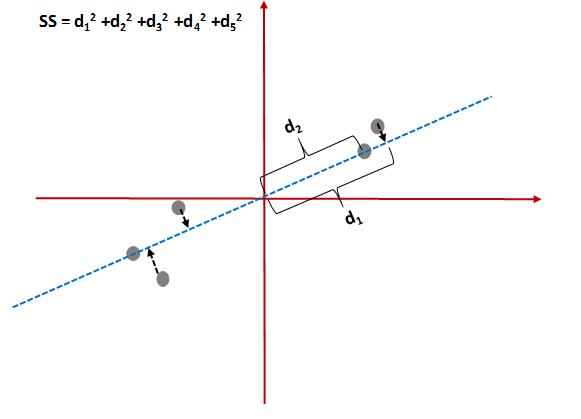
A teraz mając wybraną najlepszą krzywą można wyliczyć odpowiednie składowe.

Uff… 🙂
O czym warto pamiętać przed analizą PCA?
- Dokonać standaryzacji zbioru danych (średnia = 0, wariancja 1), ponieważ jest ważne, aby zmienne występujące w zbiorze danych były tej samej skali.
- Usunąć wartości odstające z próby, ponieważ mogą one zaburzyć wyniki.
- Obsłużyć puste wartości, ponieważ algorytm nie przyjmuje ich.
Przykład w Python
Zbiór danych przygotowałem na podstawie raportów o bankach na stronie www.prnews.pl. Możecie pobrać dane i kod z GIT’a
Zaczynamy jak zawsze od wczytania bibliotek:
import pandas as pd
import os
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder
from sklearn.decomposition import PCA
seed = 2019
Pobieramy dane wcześniej przygotowane:
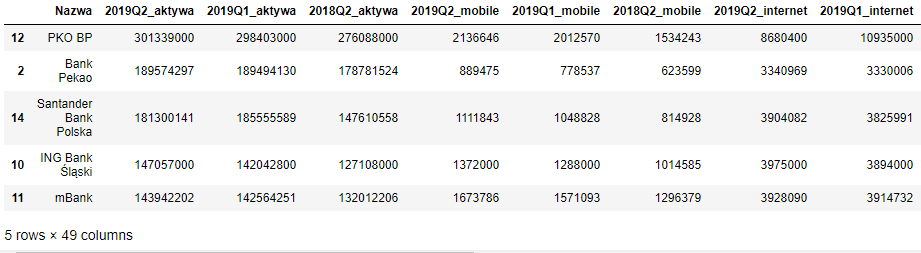
df = pd.read_excel('../data/data.xlsx', sheet_name='dataframe')
df.sort_values(by='2019Q2_aktywa', ascending=False).head()
Preprocessing zbioru: standaryzacja i obsłużenie pustych wartości.
Przed wykonaniem PCA należy dokonać standaryzacji zbioru danych (średnia = 0, wariancja = 1) ze względu na różną skalę jaka może występować w zmiennych – np. waga i dochody. Dane są następnie normalizowane (skalowane do przedziału [0,1]).
Dodatkowo implementacja PCA w pakiecie scikit-learn nie obsługuje pustych wartości, dlatego też należy odpowiednio je obsłużyć.
Uwaga: W tym przypadku zapominamy, że mamy jakikolwiek zbiór do walidacji\testowania modelu (jak ma to miejsce dla uczenia nadzorowanego) i wykonujemy funkcję fit_transform() na całym zbiorze (który może być traktowany jako zbiór treningowy). Dla uczenia nadzorowanego wykonywalibyśmy też krok następny, czyli funkcję transform() na zbiorze walidacyjnym\testowym.
def apply_scalers(df, columns_to_exclude=None):
if columns_to_exclude:
exclude_filter = ~df.columns.isin(columns_to_exclude)
else:
exclude_filter = ~df.columns.isin([])
for column in df.iloc[:, exclude_filter].columns:
df[column] = df[column].astype(float)
df.loc[:, exclude_filter] = StandardScaler().fit_transform(df.loc[:, exclude_filter])
return df
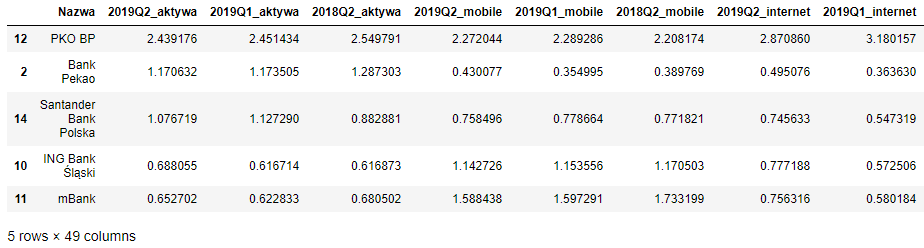
df = apply_scalers(df, columns_to_exclude=['Nazwa'])
df.sort_values(by='2019Q2_aktywa', ascending=False).head()
W celu wykonania analizy głównych składowych można wykorzystać funkcję PCA z pakietu sklearn.decomposition. Najważniejsze parametry funkcji:
- n_components – liczba n czynników w nowej przestrzeni
- svd_solver – typ dekompozycji macierzy. Dostępne wartości: auto, full, arpack, randomized
Więcej o parametrach:
https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
# kolumny do wykluczenia (te na których nie chcemy PCA)
exclude_filter = ~df.columns.isin(['Nazwa'])
# liczba głównych składowych
pca = PCA(n_components = 3)
# przeliczenie
principal_components = pca.fit_transform(df.loc[:, exclude_filter])
Sprawdźmy wynik:
principal_df = pd.DataFrame(data = principal_components,
columns = ['principal component 1', 'principal component 2', 'principal component 3'])
principal_df['Nazwa'] = df['Nazwa']
principal_df

Wizualizacja w plotly
import pandas as pd
import seaborn as sns
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
trace0 = go.Scatter(
x = principal_df['principal component 1'],
y = principal_df['principal component 2'],
text=principal_df['Nazwa'],
textposition="top center",
name = 'Piony',
mode = 'markers+text',
marker = dict(
size = 10,
color = 'rgb(228,26,28)',
line = dict(
width = 1,
color = 'rgb(0, 0, 0)'
)
)
)
data = [trace0]
layout = dict(title = 'Podobieństwo Banków na podstawie PCA',
yaxis = dict(zeroline = False, title ='PC2 (principal component 2)'),
xaxis = dict(zeroline = False, title ='PC1 (principal component 1)')
)
fig = dict(data=data, layout=layout)
iplot(fig, filename='styled-scatter')

Możecie zauważyć, że dane zawarte w tabeli są bardzo mało czytelne i nie dają nam na szybko informacji na temat podobieństw między bankami. Dopiero wizualizacja danych pokazuje grupy, jakie tworzą banki:
- PKO które odstaje od innych ( jeszcze 🙂 ) i jest liderem w Polsce pod względem wolumenu aktywów, klientów czy placówek
- druga grupa to Santander, mBank oraz ING – Banki, które walczą o bycie na podium
- pomiędzy nimi widać jeszcze Bank Pekao
- podobne do siebie są jeszcze BNP, Alior oraz Millenium
- reszta banków wg analizy PCA jest zgrupowane koło siebie.
Jak można dobrać liczbę komponentów?
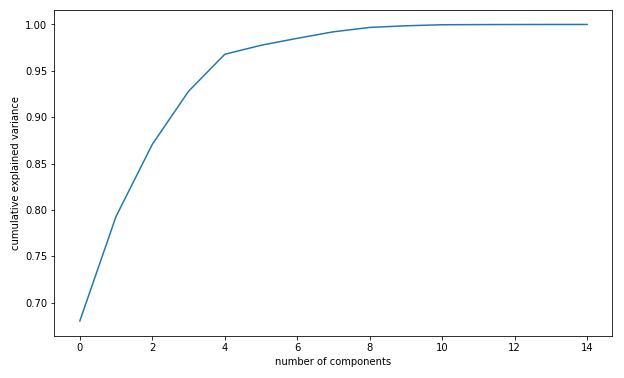
Pierwszym ze sposób jest wizualizacja skumulowanej wartości wariancji w zależności od liczby komponentów. Z wykresu można odczytać, że 4 pierwszych czynników może wyjaśnić ponad 95% całkowitej wariancji.
import numpy as np
pca = PCA().fit(df.loc[:, exclude_filter])
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance')
plt.gcf().set_size_inches(7, 5)
Wykorzystanie parametru svd_solver
Jeżeli 0 < n_components < 1 oraz svd_solver = 'full’ to funkcja PCA wybiera liczbę komponentów tak, aby wielkość wariancji, którą należy wyjaśnić, była większa niż procent określony przez n_components.
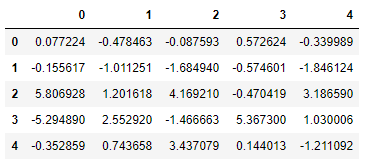
pca = PCA(svd_solver='full', n_components=0.95)
principal_components = pca.fit_transform(df.loc[:, exclude_filter])
principal_df = pd.DataFrame(data=principal_components)
principal_df.head()
Podsumowanie
Mam nadzieję, że analiza składowych (PCA) stała się dla Was bardziej zrozumiała. W powyższym przykładzie za pomocą tej metody pokazałem na przykładzie jak w ciekawy sposób możecie zobrazować najróżniejsze dane. Tutaj okazało się, że wyodrębniły się ciekawe grupy banków. Pamiętajcie tylko, że PCA to nie jest klasteryzacją. Często nie ma tam wprost widocznych podgrup – i to nie jest nic złego :).
Pozdrawiam serdecznie,




Dwa zapytania formalne (brak w tekście koniecznych objaśnień), a mianowicie:
„A teraz mając wybraną najlepszą krzywą można wyliczyć odpowiednie składowe.”
Składowe czego?
Na rysunku: „aby otrzymać składową PC1”
1. Co to jest za punkt ów PC1, dlaczego nie widnieje wyraźnie opisany na rysunku?
2. Mowa w zdaniu o „skladowej” (jednej), więc jak wykonam te dwa mnożenia, o których mowa, dostaję dwie liczby (domyślnie dwie składowe, a nie składową)
Przyglądam się przykładowi w Pythonie, ale z niego nie wynika które kolumny z oryginalnego zbioru i w jakiej proporcji wchodzą w skład PC1 i PC2, czyli tych które są na wykresie. Czy wynika, a ja czegoś nie dostrzegam w kodzie? Bo z Pythonem to tak nie za bardzo sobie radzę.
Pingback: NannyML - walidacja modelu bez danych rzeczywistych (ground truth)! - Mirosław Mamczur
Pingback: Las izolacji (isolation forest) - jak to działa? - Mirosław Mamczur
Fantastyczny artykuł, zostanę stałym czytelnikiem. Pozdrawiam 🙂
dzięki za info 🙂 bardzo się cieszę 😀
Pingback: Niezbalansowane dane klasyfikacyjne? Na ratunek SMOTE! - Mirosław Mamczur
Dzięki Panu zrozumiałem PCA. Dziękuję bardzo 🙂
Bardzo się cieszę, że mogłem pomóc 🙂
Pingback: Jak wykryć oszusta (fraud) za pomocą autoenkodera? - Mirosław Mamczur
Pingback: Jak zwizualizować word embedding? - Mirosław Mamczur