
– Tato, dlaczego tak się uśmiechasz do komputera? – zapytała Jagódka, zakradając się z Otylką do sypialni, gdzie znajduje się moje biurko.
– Ponieważ znalazłem szklaną kulę, dzięki której mogę poznać przyszłość. Zatem nie będę musiał już czekać na poznanie odpowiedzi, których potrzebuję – uśmiechnąłem się.
– A zapytasz tej kuli, co będziemy z Oti robić, jak będziemy takie duże jak tata i mama?
– Wasze zawody prawdopodobnie nie zostały jeszcze wymyślone, Skarbie 🙂.
Zbudowaliśmy model, z którego jesteśmy naprawdę dumni! Metryki są dopieszczone i spełniają wymagania postawione przez biznes. Mamy pewność, że dobraliśmy optymalną liczbę charakterystyk, wybraliśmy najlepszy rodzaj modelu i zoptymalizowaliśmy hiperparametry. Dodatkowo przygotowaliśmy dashboard (tutaj pokazane jak), który wyjaśnia, dlaczego model podjął taką, a nie inną decyzję.
Jedyną niepewną jest to, jak model działa w aktualnym miesiącu na najnowszych danych, ponieważ model przewiduje status klienta, który poznamy dopiero za kilka miesięcy… a szefowie chcą poznać odpowiedź na pytanie:
Szef:
„Jak działa Wasz model po wdrożeniu?”
Z pomocą w uzyskaniu odpowiedzi na to pytanie przychodzi nam NannyML z opracowanym algorytmem szacowania wydajności opartym na zaufaniu. Dodatkowo NannyML pomoże nam odpowiedzieć na kilka jeszcze innych pytań, które możemy sobie zadać.
Uwaga! Przed dalszą lekturą warto poznać pojęcia związane z data drift z poprzedniego artykułu!
Czym jest NannyML?
NannyML to tak naprawdę firma stojąca za implementacją biblioteki open source napisaną w Python.
To, co moim zdaniem wyróżnia ten pakiet od innych rozwiązań to, że patrzy on na problem z lotu ptaka. Twórcy NannyML wyszli z założenia, że najważniejsza jest predykcja modelu.
Dopiero, jeżeli z predykcją są problemy, to warto zagłębić się w szczegóły i sprawdzić, chociażby, czy spadek mocy spowodowany jest dryftem danych. Jeśli tak, to można przeanalizować, które cechy na to wpłynęły.
Największe wrażenie wywarł na mnie ich autorski algorytm (zwany CBPE) do estymacji, jak będzie zachowywał się model, nawet jeśli nie mamy w tym momencie zmiennej celu (groud truth).
Do tego sprawdzenia wystarczą same predykcje! Wobec tego można również przetestować modele napisane w innych językach niż Python (np. R).

Gdzie jest problem?
Załóżmy, że firma poprosiła Cię o przewidzenie, który klient nie spłaci kredytu gotówkowego w ciągu najbliższych 12 miesięcy. Budujesz model i go wdrażasz. Po wdrożeniu na produkcję otrzymujesz prawdopodobieństwa zwracane przez model.
Dla przykładu mamy 4 klientów:

Po roku od dnia wzięcia kredytu dowiemy się, które z powyższych osób spłaciły kredyt, a które nie:

Wówczas na podstawie zaobserwowanych danych (ground truth) jesteśmy w stanie wyliczyć metryki takie jak accuracy, precision, ROC AUC czy inne.
I właśnie problemem tutaj jest CZAS, który musi minąć, aby dowiedzieć się, jak działa model. Oczywiście jest wiele sposobów na skrócenie go, jak chociażby estymacja na podstawie krótszej historii.
Jednak przyjrzyjmy się bliżej algorytmowi opracowanemu przez NannyML, który pozwala uzyskać wiarygodne oszacowanie wydajności modelu bez konieczności czekania.

Jak działa algorytm Confidence-Based Performance Estimation (CBPE)?
Jest to algorytm, który pozwala oszacować wydajność modelu w przypadku braku rzeczywistych danych (groud truth).
Idea stojąca za tym algorytmem jest prosta. Wykorzystujemy oszacowanie macierzy pomyłek (confusion matrix) na podstawie oczekiwanych poziomów błędów, które znamy przy założeniu, że model jest dobrze skalibrowany. Mając macierz pomyłek, możemy oszacować dowolną metrykę wydajności, która jest na niej zbudowana (np. presicion, recall, AUC itp). Zaraz wszystko wyjaśnię w szczegółach.
Najpierw warto wiedzieć, że mamy dwa „ALE”.
Założenia dla CBPE!
Aby algorytm dawał wiarygodne wyniki, muszą zostać spełnione dwa warunki wstępne:
a) Nie może być dryfu koncepcji.
Kiedy nastąpi dryf koncepcji, to granica decyzyjna wyuczona przez model nie ma już zastosowania do nowego wspaniałego świata.
Na szczęście sam dryf danych nie stanowi problemu. Jeśli chcesz dowiedzieć się więcej, czym jest dryf danych, jakie są jego rodzaje itp., to zapraszam do poprzedniego artykułu.
b) Prawdopodobieństwa generowane przez model muszą być odpowiednio skalibrowane.
Model odpowiednio skalibrowany to taki model, którego prawdopodobieństwa dają rzeczywiste częstotliwości występowania.
Kalibracja prawdopodobieństwa jest intuicyjną koncepcją – jeśli masz grupę osób, których przewidywane prawdopodobieństwo wynosi np. 90%, to około 90% z nich powinno faktycznie okazać się pozytywne.
Uwaga! Większość klasyfikatorów binarnych tworzy wyniki, które są zwykle interpretowane i nazywane jako prawdopodobieństwa modelu… ale w rzeczywistości nie są prawdopodobieństwami. Wyższa liczba rzeczywiście oznacza wyższe prawdopodobieństwo pozytywnej klasy, ale nie zwraca dokładnej informacji, ile wyniesie.
Jednym z wyjątków od powyższej zasady jest regresja logistyczna. Z założenia modeluje prawdopodobieństwa i generuje skalibrowane wyniki. Dlatego jednym ze sposobów kalibracji źle skalibrowanego modelu jest przekazanie jego prognoz do klasyfikatora regresji logistycznej, który powinien je odpowiednio przesunąć! Proste a skuteczne 😀.
Let’s go deeper
Aby lepiej zrozumieć działanie algorytmu, zagłębmy się w przykład z 4 klientami 🙂. Nasz model zadziałał 4-krotnie i zwrócił prawdopodobieństwa dla Mirka, Elwiry, Jagody i Otylki.
Jednak w rzeczywistości nie interesują nas prawdopodobieństwa, ale jesteśmy zainteresowani ustaleniem, które osoby będą pozytywne, a które negatywne.
Uwaga! W przypadku szacowania ryzyka klasa pozytywna oznacza, że klient nie spłacił kredytu. No cóż🙂.
Na początku musimy ustawić próg odcięcia (cut off lub treshold) – obserwacje powyżej tego progu zostaną sklasyfikowane jako pozytywne, a te poniżej progu zostaną sklasyfikowane jako negatywne.
Załóżmy treshold modelu na 50%. Zatem wszystkim osobom z prawdopodobieństwem powyżej 50% przypiszemy flagę 1 (nie spłaci kredytu) a poniżej przypiszemy flagę 0, czyli spłaci kredyt.
Przeanalizujmy prawdopodobieństwo Mirka równe 90%. Ponieważ nie da się ukryć, że 90%>=50%, to przypisujemy Mirkowi klasę pozytywną (jeśli tak można mówić o tym, że nie spłaci kredytu😅).
Ponieważ mamy model skalibrowany, to możemy oczekiwać, że model będzie poprawny w 90% podobnych przypadków. Zatem zostaje nam 10% szans, że prognoza będzie fałszywie pozytywna.

Dla Elwiry sprawa wygląda inaczej. Model mówi, że ma 11% szans na klasę pozytywną, zatem zakładamy, że jest z klasy negatywnej (11% < 50% – nasz cut off). Zatem Elwira ma 89% na zakwalifikowanie jako True Negative i 11% jako False Negative.

To samo powtarzamy dla Jagódki i Otylki.

Na końcu obliczamy sumę wartości dla wszystkich obserwacji i otrzymujemy w ten sposób macierz pomyłek na podstawie oczekiwanych błędów.

Teraz możemy obliczyć interesujące nas metryki. Na przykład oczekiwaną dokładność metryki accuracy liczymy dzieląc sumę TP i TN przez liczbę przypadków testowych:

I to wszystko 👍.
A jak wyliczyć ROC AUC?
Krzywą ROC rysujemy, umieszczając na jednej osi metrykę True Positive Rate (TPR) a na drugiej False Posite Rate (FPR).

Dla powyższego przypadku wygląda to tak:

Pamiętajmy jednak, że wybór progu jest arbitralny. Zatem, aby uzyskać ogólne pojęcie o wydajności modelu, krzywa ROC jest zdefiniowana jako zbiór wszystkich TPR/FPR dla wszystkich możliwych progów. Mając 4 różne wartości, istnieje 5 możliwych progów:

Zatem krzywa ROC wyglądałaby tak:

Pole pod wykresem to nasza metryka ROC AUC!

Jak działa sprawdzenie data drift?
Sprawdzenie, czy mamy problem z data drift, również odbywa się w duchu zasady od ogółu do szczegółu.
Na naszej próbce referencyjnej, gdzie mamy wszystkie charakterystyki, dla których zbudowaliśmy model, zmniejszamy ilość wymiarów korzystając z PCA (jeśli chcesz wiedzieć, jak dokładnie działa PCA, to zapraszam do artykułu). Następnie odwracamy proces i patrzymy, jaki otrzymujemy błąd rekonstrukcji (odtwarzania) danych.
Mając taki model PCA, możemy go przeliczyć na naszych najnowszych danych. Jeśli jest istotny dryf danych, wówczas błąd rekonstrukcji dla najnowszych danych powinien być większy niż na próbce referencyjnej. Prosta i genialna idea.

Przykład NannyML w Python
Dość teorii. Przejdźmy teraz do praktyki. Na szybko stworzyłem nowe środowisko w Python (kliknij tu, jeśli nie wiesz jak) i zainstalowałem wszystkie najnowsze biblioteki, byście mogli także powtórzyć to doświadczenie.
Uwaga! Poniżej przygotowałem bardzo prosty preprocessing i model, aby skupić się na pokazaniu, jak wykorzystać NannyML. Nie linczujcie mnie za to, że nie przygotowałem profesjonalnie oczyszczania danych, wyboru cech, modelu i hiperparametrów 😇.
Wczytajmy potrzebne biblioteki:
import pandas as pd
import numpy as np
import nannyml as nml
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import plotly.graph_objects as go
import datetime
import random
import math
Wiem, że z czasem biblioteki będą miały nowsze wersje, dlatego poniżej dokładne wersje, jakie miałem na moment tworzenia tego przykładu:
# information about python package versions for this project
from sklearn import __version__ as sklearn_ver
from plotly import __version__ as plotly_ver
print(f'pandas: {pd.__version__}')
print(f'numpy: {np.__version__}')
print(f'nannyml: {nml.__version__}')
print(f'sklearn: {sklearn_ver}')
print(f'plotly: {plotly_ver}')

Skoro teoretyczny przykład był dla ryzyka kredytowego, to pozostańmy w tym duchu. Wykorzystałem dane z konkursu Kaggle „Home Credit Default Risk„. Dla tego eksperymentu pobrałem jedynie tabelę z danymi aplikacyjnymi: application_train.csv. Dane możesz pobrać TUTAJ.

Wczytajmy dane:
df_app = pd.read_csv('../data/application_train.csv')
print(f'rows: {df_app.shape[0]}, columns: {df_app.shape[1]}')
df_app.head(3)

Szybki preprocessing
Dla uproszczenia zbudujemy na szybko random forest. Dlatego zróbmy prosty preprocessing danych i zamieńmy dane tekstowe na numeryczne.
df_app.info()

Wiemy już, co i jak zmienić. Zmieńmy wartości tekstowe binarne na kolumnę z wartościami 0/1, dane tekstowe do 10 unikalnych kolumn zmieńmy na one-hot encoding, a kolumny z większą ilością wartości usuńmy.
# Remove 4 applications with XNA CODE_GENDER
df_app = df_app[df_app['CODE_GENDER'] != 'XNA']
# NaN values for DAYS_EMPLOYED: 365.243 -> nan
df_app['DAYS_EMPLOYED'] = df_app['DAYS_EMPLOYED'].replace(365243, np.nan)
# Categorical features with One-Hot encode
for col in df_app.select_dtypes(include=['object']).columns:
print(f'{col}: {df_app[col].nunique()}')
if df_app[col].nunique() <= 2:
df_app[col], columns = pd.factorize(df_app[col])
elif df_app[col].nunique() <= 10:
df_app = pd.get_dummies(df_app, columns= [col], dummy_na=False)
elif df_app[col].nunique() > 10:
df_app = df_app.drop(columns=[col])
print(f'rows: {df_app.shape[0]}, columns: {df_app.shape[1]}')

Aby w pełni pokazać Wam, jak działa NannyML na podstawie klucza na klientach, przypiszę losowy okres z zakresu 2 lat:
df_app['DATE'] = [random.choice(pd.date_range('2020-01-01','2022-12-01', freq='MS'))
for i in range(df_app.shape[0])]
df_tmp = df_app.groupby('DATE')['TARGET'].agg(['count','sum']).reset_index()
df_tmp['%default'] = (df_tmp['sum']/df_tmp['count']).round(4)
df_tmp.head(3)

Sprawdźmy, czy poziom klientów, którzy nie spłacają kredytów, jest mniej więcej ten sam:
trace1 = go.Scatter(x=df_tmp['DATE'],
y=df_tmp['%default'],
mode='lines+markers')
data = [trace1]
layout = go.Layout(title='<b>Monthly historical %default</b>',
title_x=0.5, title_y=0.9,
plot_bgcolor='#f7f7f7',
yaxis=dict(range=[0,0.1])
)
fig = go.Figure(data=data, layout=layout)
fig.show()

Budowa przykładowego modelu
NannyML wymaga kolumny z podziałem na zbiór do nauki i do predykcji. Dlatego dla uproszczenia potraktujmy te dwa zbiory odpowiednio jako zbiór treningowy i zbiór testowy, na którym przetestujemy czy NannyML prawidłowo działa.
df_app = df_app.fillna(0)
df_app['partition'] = df_app['DATE'].apply(lambda x:
'reference' if x < datetime.datetime(2022,1,1) else
'analysis')
I przygotujmy zbiory:
reference = df_app.loc[df_app.partition=='reference'].iloc[:,1:].copy()
analysis = df_app.loc[df_app.partition=='analysis'].iloc[:,1:].copy()
Teraz wyłączmy jedynie ze zbioru treningowego zmienne, których nie chcemy używać:
feats_exclude = ['SK_ID_CURR', 'TARGET', 'DATE', 'partition']
feats = [feat for feat in df_app.columns if feat not in feats_exclude]
X_train = reference[feats]
y_train = reference['TARGET']
X_test = analysis[feats]
y_test = analysis['TARGET']
i zbudujmy model:
rf_user_param ={
"max_depth": 5,
"n_estimators": 100,
"n_jobs":-1
}
model_rf = RandomForestClassifier(**rf_user_param)
model_rf.fit(X_train ,y_train)
print(f'train: {roc_auc_score(y_train,model_rf.predict_proba(X_train)[:,1])}')
Zapiszmy jeszcze wartości predykcji:
reference['y_pred_proba'] = model_rf.predict_proba(X_train)[:,1]
analysis['y_pred_proba'] = model_rf.predict_proba(X_test)[:,1]
reference['y_pred'] = model_rf.predict(X_train)
analysis['y_pred'] = model_rf.predict(X_test)
Kalibracja
We wcześniejszym kroku zbudowaliśmy las losowy. Sprawdźmy teraz, jak wyglądają wyniki predykcji z modelu do rzeczywistych wartości, kto nie spłacił kredytu.
def calib_chart(df, target_col='TARGET', proba_col='y_pred_proba', ox_title='Model probability'):
df_ = df[[target_col,proba_col]].copy()
df_[proba_col] = df_[proba_col].round(2)
df_ = df_.groupby(proba_col)[target_col].agg(['count','sum']).reset_index()
df_['%default']=df_['sum']/df_['count']
trace1 = go.Scatter(x=df_[proba_col],
y=df_['%default'],
mode='lines+markers',
marker_color='rgb(190,0,0)',
name=f'{ox_title}')
df_line = np.linspace(0,df_[proba_col].max(),11)
trace2 = go.Scatter(x=df_line,
y=df_line,
mode='lines',
line=dict(width=2,dash='dot',color='rgb(75,75,75)'),
name='f(x)=x',
showlegend=True)
data = [trace1, trace2]
layout = go.Layout(title=f'<b>{ox_title} vs Observed Default Rate(ODR)</b>',
title_x=0.5, title_y=0.9,
plot_bgcolor='#f7f7f7',
yaxis=dict(title='Observed Default Rate(ODR)'),
xaxis=dict(title=ox_title)
)
fig = go.Figure(data=data, layout=layout)
return fig.show()
calib_chart(reference, 'TARGET', 'y_pred_proba')
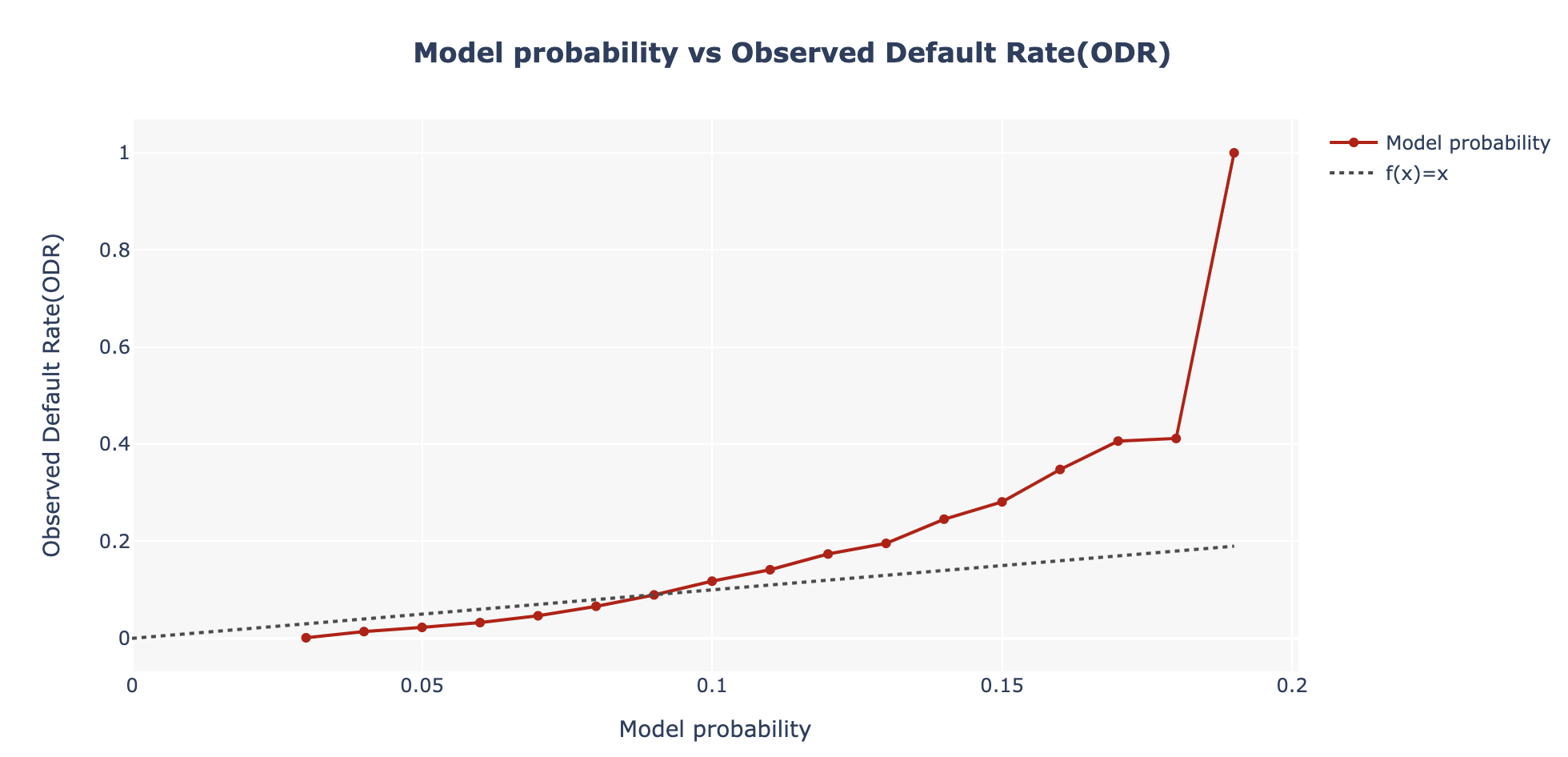
Jak widać na powyższym rysunku, maksymalna wartość predykcji z modelu wychodzi około 0,18. Dla tej wartości widać, że poziom defaultów wynosi 100%! Z wykresu możemy łatwo wywnioskować, że od wartości z modelu powyżej 0,10 liczba defaultów w populacji jest wyższa.
Tak jak wcześniej opisałem, przygotowałem kalibrację, korzystając z regresji logistycznej. Jako zmienne do modelu podajemy tylko wartości z predykcji z modelu:
lr = LogisticRegression()
lr.fit(X=reference[['y_pred_proba']], y=reference['TARGET'])
Po zbudowaniu modelu przypiszmy nowe prawdopodobieństwa do zbioru treningowego i testowego z przypisanym progiem odcięcia na poziomie 20%. Dlaczego 20%? Ponieważ przy aktualnym średnim oprocentowaniu, prowizji i % odzyskania w przypadku niespłacenia kredytu to nam się opłaca:
reference['y_pred_proba_calib']=lr.predict_proba(reference[['y_pred_proba']])[:,1]
analysis['y_pred_proba_calib']=lr.predict_proba(analysis[['y_pred_proba']])[:,1]
reference['y_pred_calib']=reference['y_pred_proba_calib'].apply(lambda x: 1 if x > 0.2 else 0)
analysis['y_pred_calib']=analysis['y_pred_proba_calib'].apply(lambda x: 1 if x > 0.2 else 0)
Sprawdźmy wcześniejszy wykres, czy wygląda lepiej:
calib_chart(reference, 'TARGET', 'y_pred_proba_calib')

Widać z wykresu, że teraz kalibracja działa poprawnie. Wartości predykcji pokazują rzeczywiste wartości niespłaconych kredytów. Dla wyższych wartości są większe wahania, natomiast wynikają z mniejszych liczności.
Mając wyliczoną regresję, sami możemy prosto wyprowadzić funkcję kalibrującą na zmianę predykcji z modelu lasu losowego na rzeczywistą wartość predykcji. Można to zrobić tak:
alpha = lr.coef_[0][0]
beta = lr.intercept_[0]
def calibration(score, alpha, beta):
return 1/(1+math.e**(-alpha*score - beta))
Sprawdźmy teraz jeszcze, jaka jest różnica pomiędzy predykcją z modelu a predykcją z naszej kalibracji:
df_score = pd.DataFrame(np.linspace(0,1,100),
columns=['model_probability'])
df_score['calibration'] = df_score.apply(lambda x: calibration(x, alpha, beta))
trace1 = go.Scatter(x=df_score['model_probability'],
y=df_score['model_probability'],
mode='lines+markers',
marker_color='rgb(190,0,0)',
name='model probability')
trace2 = go.Scatter(x=df_score['model_probability'],
y=df_score['calibration'],
mode='lines+markers',
marker_color='rgb(0,190,0)',
name='calibration probability')
data = [trace1, trace2]
layout = go.Layout(title=f'<b>Model probability vs calibration</b>',
title_x=0.5, title_y=0.9,
plot_bgcolor='#f7f7f7',
yaxis=dict(title='Calibration probability'),
xaxis=dict(title='Model probability'),
hovermode='x'
)
fig = go.Figure(data=data, layout=layout)
fig.show()

NannyML w akcji!
Czas skorzystać z algorytmu CBPE i zobaczyć, jak będą się kształtować metryki modelu w 2022 roku!
# initialize, specify required data columns, fit estimator and estimate
estimator = nml.CBPE(
y_pred_proba='y_pred_proba_calib',
y_pred='y_pred_calib',
y_true='TARGET',
metrics=['roc_auc','accuracy'],
timestamp_column_name='DATE',
chunk_period='M',
problem_type='classification_binary'
)
estimator = estimator.fit(reference)
estimated_performance = estimator.estimate(analysis)

Jak widać na podstawie wyliczeń, w ciągu najbliższego roku sytuacja będzie stabilna według algorytmu. Warto zwrócić uwagę, że niepewność jest na poziomie +/-2% AUC. Czasami to nie jest dużo. Jednak dla wielomilionowego banku z doświadczenia powiem, że 1% AUC w perspektywie roku może odpowiadać za 1 mln dodatkowego przychodu.
Teraz bardzo prosto jest również sprawdzić inne metryki, na przykład accuracy (przy naszym progu odcięcia):
figure = estimated_performance.plot(kind='performance', metric='accuracy', plot_reference=True)
figure.show()

Nie wygląda to źle. Pamiętajmy, że użyliśmy tylko danych aplikacyjnych (bez najważniejszych informacji, czyli jak klient historycznie obsługiwał produkty kredytowe), bez optymalizacji wyboru cech, modelu i hiperparametrów!
Porównanie różnic
Sprawdźmy, jak wygląda ostateczne porównanie estymacji algorytmu CBPE z NannyML i rzeczywistych danych.
trace1 = go.Scatter(x=estimated_performance.data['start_date'],
y=estimated_performance.data['realized_accuracy'],
mode='lines+markers',
marker_color='rgb(190,0,0)',
name='realized accuracy',
showlegend=True)
trace2 = go.Scatter(x=estimated_performance.data['start_date'],
y=estimated_performance.data['estimated_accuracy'],
mode='lines+markers',
marker_color='rgb(0,150,0)',
name='estimated accuracy',
showlegend=True)
trace3 = go.Scatter(x=estimated_performance.data['start_date'],
y=estimated_performance.data['upper_confidence_accuracy'],
mode='lines',
line=dict(width=1,dash='dot',color='rgb(150,150,150)'),
name='confidence level',
showlegend=True)
trace4 = go.Scatter(x=estimated_performance.data['start_date'],
y=estimated_performance.data['lower_confidence_accuracy'],
mode='lines',
line=dict(width=1,dash='dot',color='rgb(150,150,150)'),
name='confidence level',
showlegend=False)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(title='<b>Model propability vs Observed Default Rate(ODR)</b>',
title_x=0.5, title_y=0.9,
plot_bgcolor='#f7f7f7',
yaxis=dict(title='<b>accuracy</b>'),
xaxis=dict(title='<b>date</b>'),
hovermode='x',
)
fig = go.Figure(data=data, layout=layout)
fig.show()

Wow! Naprawdę zaskakująca skuteczność!
Data Drift
Sprawdźmy jeszcze, jak wygląda wynik algorytmu wyliczającego data drift na podstawie rekonstrukcji błędu z PCA:
# Let's initialize the object that will detect Multivariate Drift
rcerror_calculator = nml.DataReconstructionDriftCalculator(
feature_column_names=X_train.columns,
timestamp_column_name='DATE',
chunk_period='M')
rcerror_calculator.fit(reference_data=reference)
# let's see Reconstruction error statistics for all available data
rcerror_results = rcerror_calculator.calculate(analysis)
figure = rcerror_results.plot(kind='drift', plot_reference=True)
figure.show()

Widać, że nie wykrywamy tutaj dryfu danych.
… a co gdyby zepsuć dane (what if)?
W tym przypadku wszystko jest ok. A co gdybyśmy specjalnie troszkę zepsuli dane i zobaczyli, jak wówczas radzą sobie algorytmy z NannyML?
Sprawdźmy, która cecha z ponad 160 jest najmocniejsza w modelu:
forest_importances = pd.DataFrame(pd.Series(model_rf.feature_importances_,
index=X_train.columns),
columns=['importance'])
forest_importances.sort_values(by='importance', ascending=False).head(5)

Mamy faworyta! To zmienna „EXT_SOURCE_2”. Mówi ona o szacowanym ryzyku klienta na podstawie biura kredytowego. W Polsce odpowiednikiem takiego biura byłaby punktacja scoringowa z Biura Informacji Kredytowej (BIK).
Zbudujmy teraz próbkę, gdzie dla pierwszych 3 miesięcy z próbki testowej (2022) nic nie zmieniamy, a na pozostałym okresie zostawiamy tylko obserwacje z najwyższą wartością tej zmiennej:
analysis_bias = pd.concat([
analysis[analysis['DATE']<='2022-03-01'],
analysis[(analysis['DATE']>'2022-03-01') &
(analysis['EXT_SOURCE_2']>0.75)]
])
Zobaczmy, jak zachowa się moc modelu na takiej próbce:
estimated_performance = estimator.estimate(analysis_bias)
figure = estimated_performance.plot(kind='performance', metric='roc_auc', plot_reference=True)
figure.show()

Widzimy, że taka zmiana wpłynęła na moc modelu.
A czy byłoby to możliwe w prawdziwym środowisku bankowym? Oczywiście, że tak. Wystarczyłoby wprowadzić regułę decyzyjną, która odrzucałaby takich klientów.
A jak w takim przypadku wyglądałby dryf danych?
# let's see Reconstruction error statistics for all available data
rcerror_results = rcerror_calculator.calculate(analysis_bias)
figure = rcerror_results.plot(kind='drift', plot_reference=True)
figure.show()

Widać również przekroczenie zakładanych dopuszczalnych granic błędu.
Co dalej?
Ok, ale co moglibyśmy w takim przypadku zrobić? Tutaj wystarczyłoby sprawdzić zmiany rozkładów wszystkich zmiennych w czasie.
Poniżej zmiana rozkładu prawdopodobieństwa:
# Let's initialize the object that will perform the Univariate Drift calculations
univariate_calculator = nml.UnivariateStatisticalDriftCalculator(
feature_column_names=['EXT_SOURCE_2','y_pred_proba_calib'],
timestamp_column_name='DATE',
chunk_period='M')
univariate_calculator = univariate_calculator.fit(reference)
univariate_results = univariate_calculator.calculate(analysis_bias)
figure = univariate_results.plot(
kind='feature_distribution',
metric='statistic',
feature_column_name='y_pred_proba_calib',
plot_reference=True
)
figure.show()

Analizując zmienną po zmiennej, zobaczylibyśmy, że jedyna zmienna, na której zmienił się rozkład to „EXT_SOURCE_2”.
figure = univariate_results.plot(
kind='feature_distribution',
metric='statistic',
feature_column_name='EXT_SOURCE_2',
plot_reference=True
)
figure.show()

Polecam obserwować bibliotekę NannyML, ponieważ prace nad nią cały czas trwają i ciągle się rozwija.
Mam nadzieję, że również Tobie przyda się w monitorowaniu modeli na produkcji tak jak mi!
Pozdrawiam z całego serducha,

Bibliografia:
- https://www.nannyml.com/
- https://towardsdatascience.com/data-drift-explainability-interpretable-shift-detection-with-nannyml-83421319d05f
- https://pub.towardsai.net/estimating-model-performance-without-ground-truth-453b850dad9a
- https://towardsdatascience.com/predict-your-models-performance-without-waiting-for-the-control-group-3f5c9363a7da



Pingback: Newsletter #1 13.10.2022 – Adam G. Dobrakowski
Cześć,
Moim zdaniem brakuje komentarza/wniosków pod wykresem ukazującym różnice pomiędzy predykcją z modelu a predykcją z naszej kalibracji. Co z niego wynika? Co to znaczy, że dystrybuanta tak szybko „biegnie” do 1? To dobrze, czy źle? Jak to zinterpretować?
Super artykuł! Jedna mała uwaga – akurat w tym przypadku nie miało to większego wpływu, ale zbiór referencyjny dla NannyML to powinien być zbiór, którego model nie widział podczas trenowania (czy tunowania), czyli w najlepszym przypadku dane produkcyjne lub zbiór testowy.
Hej, dzięki za komentarz! Oczywiście masz rację. Na szczęście model nie widział podczas trenowania zbioru referencyjnego 😉