
Ostatnio przygotowałem dla Was wprowadzenie czym są dane niezbalansowane i jakie wiążą się z nimi zagrożenia. W tym wpisie opiszę metodę zwaną SMOTE, którą ostatnio wykorzystałem podczas projektu w pracy.
Co to jest SMOTE?
Metoda SMOTE została po raz pierwszy opisana w 2002 w pracy autorstwa Nitesh Chawla zatytułowanej “SMOTE: Synthetic Minority Over-sampling Technique“. Jak sama nazwa wskazuje jest to technika generująca syntetyczne dane dla klasy mniejszości.

A co znaczy syntetyczne? Oznacza to, że SMOTE działa poprzez łączenie punktów klasy mniejszości odcinkami linii, a następnie umieszcza na tych liniach sztuczne punkty.

Ta technika tworzy nowe instancje danych grup mniejszościowych, kopiując istniejące dane i wprowadzając do nich niewielkie zmiany. To sprawia, że SMOTE świetnie wzmacnia sygnały, które już istnieją w grupach mniejszościowych, ale nie stworzy nowych sygnałów dla tych grup.
Działanie SMOTE
Sposób działania algorytmu SMOTE możemy krótko opisać w 4 prostych krokach:
- Wybieramy losowo przykładową obserwację dla klasy mniejszościowej.
- Znajdujemy k najbliższych sąsiadów dla wybranej obserwacji (z punktu 1).
- Wybieramy jednego z tych sąsiadów i umieszczamy syntetyczny punkt w dowolnym miejscu na linii łączącej rozpatrywany punkt z sąsiadem. Linię tą możemy porównać do przestrzeni cech. Starając sobie to zwizualizować pomyślałem o redukcji wymiarów. Na przykład mając 100 zmiennych opisujących dane zjawisko można wykorzystać PCA (opisałem TUTAJ) i zredukować przestrzeń do 2 wymiarów. W ten sposób łączymy punkty.
- Powtarzamy kroki 1-3, aż dane zostaną zbalansowane.
Biblioteka Imbalanced-Learn
SMOTE jest zaimplementowany w Pythonie przy użyciu biblioteki imblearn.
Bibliotekę instalujemy w ten sposób:
pip install imbalanced-learn
A tak można sprawdzić jej wersję:
import imblearn
print(imblearn.__version__)
Zapraszam również do zerknięcia do samej dokumentacji – najnowszy link znajdziecie w repozytorium na GitHub: https://github.com/scikit-learn-contrib/imbalanced-learn
Prosty syntetyczny przykład
Aby zobaczyć prosty przykład działania SMOTE, wygenerujmy próbkę danych. Niech to będą dwa zbiory z odrobinę różnym rozkładem. Możemy użyć funkcji make_classification() z biblioteki scikit-learn, aby utworzyć zestaw danych syntetycznej klasyfikacji binarnej z rozkładem klas 1:1000.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=12345, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.999], flip_y=0,
random_state=12345)
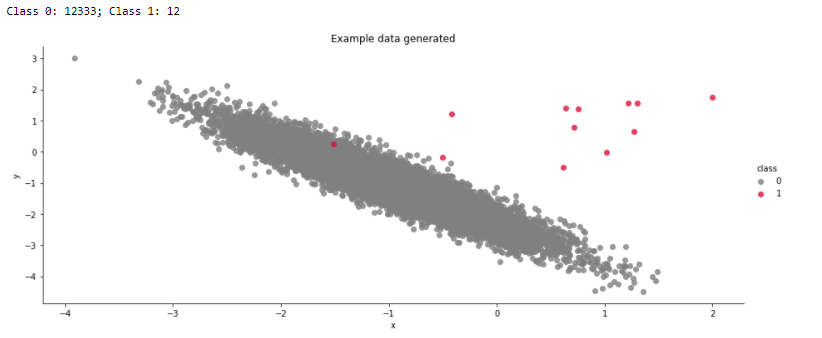
print(f'Class 0: {Counter(y)[0]}; Class 1: {Counter(y)[1]}')
df = pd.concat([pd.DataFrame(X, columns=['x','y']),
pd.DataFrame(y, columns=['class'])],axis=1)
palette = ['Gray', 'Crimson']
sns.lmplot(x="x", y="y", data=df, fit_reg=False,
legend=True, height=5, aspect=2.5,
hue='class', palette=palette)
plt.title('Example data generated');
Teraz napiszmy krótką funkcję, aby wykorzystać SMOTE do wygenerowania takiej liczby punktów, ile jest w klasie mniejszościowej. Czyli, aby było tyle „1” co „0”.
def example(X, y, oversample, title):
X_smote, y_smote = oversample.fit_resample(X, y)
df_smote = pd.concat([pd.DataFrame(X_smote, columns=['x','y']),
pd.DataFrame(y_smote, columns=['class'])],axis=1)
sns.lmplot(x="x", y="y", data=df_smote, fit_reg=False,
legend=True, height=5, aspect=2.5,
hue='class', palette=palette)
plt.title(f'{title} example');
example(X, y, SMOTE(), 'SMOTE')

Jak widać na przykładzie SMOTE po prostu połączył wcześniej występujące punkty ze sobą, a następnie tworzył syntetyczne dane na ich połączeniach. Super, że tyle tego mamy, ale warto pamiętać, że to też może być czasami wada tego rozwiązania. Większość problemów modelarskich ciężko opisać prostymi liniowymi zależnościami i czasami w ten sposób dogenerowywane dane mogą wpływać na to, jak model potraktuje dane, których jeszcze nie widział.
Inne warianty SMOTE
W bibliotece imblearn jest wiele różnych wariantów SMOTE. Odrobinę się różnią implementacją. Główne z nich to:
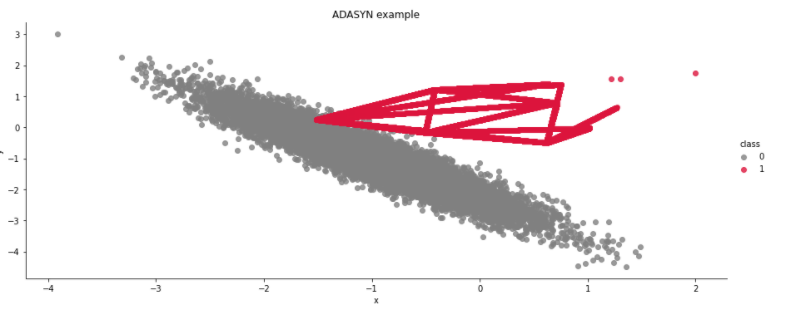
- ADASYN – ta metoda jest podobna do SMOTE, ale generuje różną liczbę próbek w zależności od oszacowania lokalnego rozkładu klasy miejszościowej;
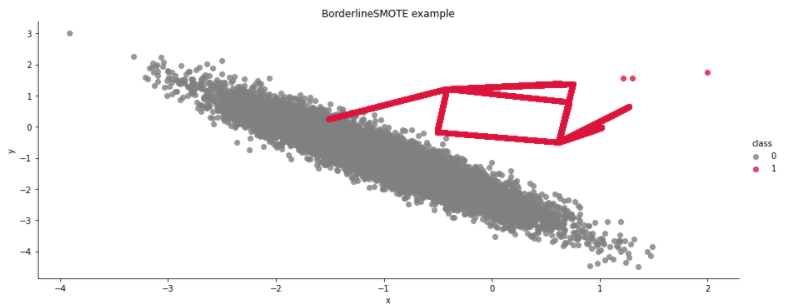
- BorderlineSMOTE – inna implementacja SMOTE zgodna z pracą z 2005 “Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning” https://ousar.lib.okayama-u.ac.jp/en/19617;
- SVMSMOTE – inny wariant SMOTE wykorzystujący algorytm SVM do wykrywania próbki syntetycznych danych;
- KMeansSMOTE – modyfikacja algorytmu poprzez dodanie klastrowania przed samym algorytmem SMOTE.
from imblearn.over_sampling import ADASYN
example(X, y, ADASYN(), 'ADASYN')
from imblearn.over_sampling import BorderlineSMOTE
example(X, y, BorderlineSMOTE(), 'BorderlineSMOTE')
from imblearn.over_sampling import KMeansSMOTE
example(X, y, KMeansSMOTE(cluster_balance_threshold=0.001), 'KMeansSMOTE')

Polecam poeksperymentować na własnych przykładach i zobaczyć co u Was najlepiej zadziała!
Przykład w Python na danych z fraudami kartowymi
Wykorzystamy w tym celu udostępnione w konkursie Kaggle dane transakcyjne dokonane kartami kredytowymi we wrześniu 2013 przez europejskich posiadaczy kart.
Zestaw zawiera transakcje z dwóch dni, w których mamy 492 oszustw (fraud) na 284 807 transakcji. Na pierwszy rzut oka widać, że zbiór jest wysoce niezrównoważony – klasa dodatnia oszustwa (fraud) stanowi 0,172% wszystkich transakcji.
Zbiór danych można pobrać: TUTAJ.
Dane są tylko numeryczne i większość cech (od V1 do V28) jest wynikiem transformacji PCA (kiedyś o tym pisałem), która została wykonana w celu zapewnienia poufności danych.
Jedynie dwie cechy nie zostały zmienione. Są to:
- Kwota – kwota transakcji w dolarach $$$,
- Czas – w sekundach, które upłynęły między każdą transakcją a pierwszą transakcją w zbiorze danych.
Wczytanie i przygotowanie danych
Skoro mamy dane, to je wczytajmy!
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pd.options.display.max_columns = 13
df = pd.read_csv('../data/creditcard.csv')
df.head()

Przygotujmy podział na zbiór do trenowania i zbiór do ostatecznego przetestowania modelu.
from sklearn.model_selection import train_test_split
X = df.loc[:, 'V1':'Amount']
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2021)
print('Train data shape: {}, frauds: {}'.format(X_train.shape, y_train.sum()))
print('Test data shape: {}, frauds: {}'.format(X_test.shape, y_test.sum()))

pd.Series(y_train).value_counts().plot.bar();

Jak widzicie, ostatecznie zbiór treningowy składa się z 366 fraudów i ponad 213 tysięcy obserwacji normalnych! To są dopiero dane niezbalansowane.
Trenowanie modelu i optymalizacja
W pierwszym kroku zbudujmy prosty model. Niech to będzie mój ulubiony XGBoost!
Dodatkowo fajnie będzie zadbać, by nie był to model na domyślnych parametrach. Wobec tego wykorzystam zamiast optymalizacji baysowskiej (której najczęściej używam w pracy) tym razem metodę losowania (ang. Random Search). Jeśli chcesz poczytać więcej o metodach zapraszam TUTAJ.
Wykorzystamy funkcję RandomizedSearchCV, która wykorzystuje walidację krzyżową (ang. cross-validation) domyślnie na 5 zbiorach. Pamiętajcie – zbioru testowego nie dotykamy! Tylko do ostatecznego testu. O zbiorze testowym myślcie jako o maturze – ostateczny egzamin sprawdzający jak się nauczyliśmy.
import xgboost as xgb
from sklearn.model_selection import RandomizedSearchCV
random_param = {
'max_depth': range(2,5),
'learning_rate': np.logspace(np.log10(0.005), np.log10(0.5), base = 10, num = 1000),
'n_estimators': range(25, 250, 25),
'subsample': np.linspace(0.5, 1, 101),
'colsample_bytree': np.linspace(0.6, 1, 5),
}
model = xgb.XGBClassifier()
random_search = RandomizedSearchCV(estimator=model
, param_distributions=random_param
, n_iter=20
, scoring='f1')
random_search.fit(X=X_train, y=y_train)
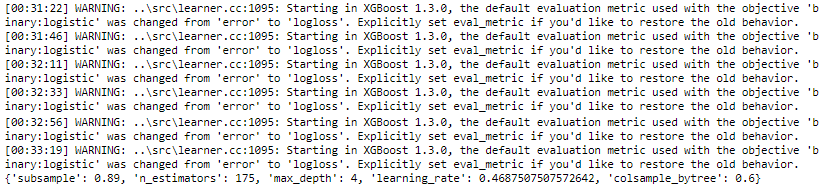
best_parameters = random_search.best_params_
print(best_parameters)
Przygotujmy jeszcze funkcję do podsumowania modelu i metryk:
from sklearn.metrics import roc_auc_score, accuracy_score, f1_score, accuracy_score, recall_score, precision_score, matthews_corrcoef, average_precision_score
def create_measures(y,y_pred):
# minimalna wartość dla cut offa dla takiej samej ilości badów jak występuje w próbce
cut_off = np.sort(y_pred)[-y.sum():].min()
y_pred_class = np.array([0 if x < cut_off else 1 for x in y_pred])
d = {'f1_score': [round(f1_score(y, y_pred_class),4)],
'P-R score': [round(average_precision_score(y, y_pred_class),4)],
'matthews': [round(matthews_corrcoef(y, y_pred_class),4)],
'accuracy': [round(accuracy_score(y, y_pred_class),4)],
'recall': [round(recall_score(y, y_pred_class),4)],
'precision': [round(precision_score(y, y_pred_class),4)],
}
return pd.DataFrame.from_dict(d)
def calculating_metrics(X_train, X_test, y_train, y_test, model):
train = create_measures(y_train, model.predict_proba(X_train)[:, 1])
test = create_measures(y_test, model.predict_proba(X_test)[:, 1])
return pd.concat([train,test]).set_index([pd.Index(['TRAIN', 'TEST'])])
Dla mnie główną metryką będzie F1, która szuka kompromisu pomiędzy precision a recall. Chcę dobrze rozpoznawać fraudy, ale nie kosztem normalnych transakcji. Zakładam, że takie transakcje albo będą automatyczne blokowane, albo jeszcze przeglądane przez kogoś. A nasi szefowie nie będą chcieli zatrudniać sztabu osób do przeglądania błędnie wskazanych przez model decyzji.
No to budujemy i sprawdzamy:
model = xgb.XGBClassifier(**best_parameters)
model.fit(X_train, y_train)
calculating_metrics(X_train, X_test, y_train, y_test, model)

Widać na próbce treningowej, że model został przetrenowany. Trafił wszystko idealnie. Można byłoby pobawić się regularyzacją, jednak w związku z tym, że nie koncentruję się tutaj, aby nie przetrenować modelu, a pokazać jak działa SMOTE, zostawię parametry zwrócone przez random search.
Trenowanie modelu z wykorzystaniem SMOTE
To wykorzystajmy teraz SMOTE do rozmnożenia liczby fraudów:
smote = SMOTE(random_state=2021)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
pd.Series(y_train_smote).value_counts().plot.bar();

Jak widać liczba obserwacji jest identyczna. O to nam tutaj chodziło. Jeśli chcesz inne proporcje np. 1:4, to możesz prosto ustawić to parametrem.
Uwaga! Nigdy, przenigdy nie wykorzystuj metod SMOTE do zmiany na próbce testowej! Chcemy zaimplementować nasz model na danych rzeczywistych, więc chcemy zobaczyć, jak nasz model będzie działał na danych rzeczywistych, a nie na danych syntetycznych, które stworzyliśmy.
To teraz szukanie optymalnmych parametrów:
model_smote = xgb.XGBClassifier()
random_search_smote = RandomizedSearchCV(estimator=model_smote
, param_distributions=random_param
, n_iter=20
, scoring='f1')
random_search_smote.fit(X=X_train_smote, y=y_train_smote)
best_parameters_smote = random_search_smote.best_params_
print(best_parameters_smote)

i ostateczne sprawdzenie wyniku:
model_smote = xgb.XGBClassifier(**best_parameters_smote)
model_smote.fit(X_train_smote, y_train_smote)
calculating_metrics(X_train_smote, X_test, y_train_smote, y_test, model_smote)

Tadam! W tym przypadku widzimy, że metoda mogła przyczynić się do polepszenia metryk. Dlaczego tylko „mogła„? Ponieważ, aby to potwierdzić, przydałoby się więcej prób. Lepszy wynik może być też dobraniem lepszych hiperparametów. Niemniej jednak drugi model wypada lepiej.
Podsumowanie
Mam nadzieję, że teraz poradzicie sobie w przypadku, gdybyście potrzebowali zbalansować próbkę przy wykorzystaniu syntetycznych danych. Pamiętajcie, że każdy problem, nad którym pracujecie jest inny i nie zawsze jak coś raz zadziała, to będzie można to powtórzyć.
Pozdrawiam z całego serducha,

Obraz Aamir Mohd Khan z Pixabay



Pingback: Newsletter Dane i Analizy, 2021-08-23 | Łukasz Prokulski
SMOKE SMOTE SMOK
z tych 3 słów najbardziej lubie Smok 😀
Pingback: How to handle imbalanced data in classification problems? Example in R.