
– Hej tatusiu, co dzisiaj robiłeś?– zapytała Jagódka.
– Dzisiaj wykorzystałem inną metodę do redukcji wymiarów niż ostatnio.
– A po co?
– Pamiętasz jak ostatnio rozmawialiśmy o wybieraniu zabawek? [LINK]
– Tak – uśmiechnęła się.
– To można byłoby to zrobić inaczej. Z tych pięciu zabawek – trzech pand i dwóch sióstr – naszym celem byłoby wybranie tylko dwóch. Tym razem, zamiast szukać najróżniejszych, można byłoby szukać najbardziej podobnych. Dzięki temu na wycieczkę można byłoby wziąć dwie siostry: Annę i Elsę, aby mogły się ze sobą bawić.
– Nie wiem po co Ci tatusiu tyle różnych metod – powiedziała Jagódka.
– Po to, by je poznać i zawsze móc dobierać najlepszą do danego problemu – odpowiedziałem i uśmiechnąłem się.
W poprzednim poście opisałem jak działa PCA, którego historia sięga według niektórych źródeł nawet 1901 roku. W tym wpisie omówię alternatywną metodę redukcji wymiarów t-SNE opracowaną przez Laurens van der Maatens i Geoffrey Hinton w 2008 roku.
Co to jest t-SNE?
Skrót t-SNE oznacza stochastyczną metodę porządkowania sąsiadów w oparciu o rozkład t (t-Distributed Stochastic Neighbor Embedding). Jest to nieliniowa i nienadzorowana technika stosowana przede wszystkim do eksploracji i wizualizacji danych wielowymiarowych.
Ogólna idea działania t-SNE
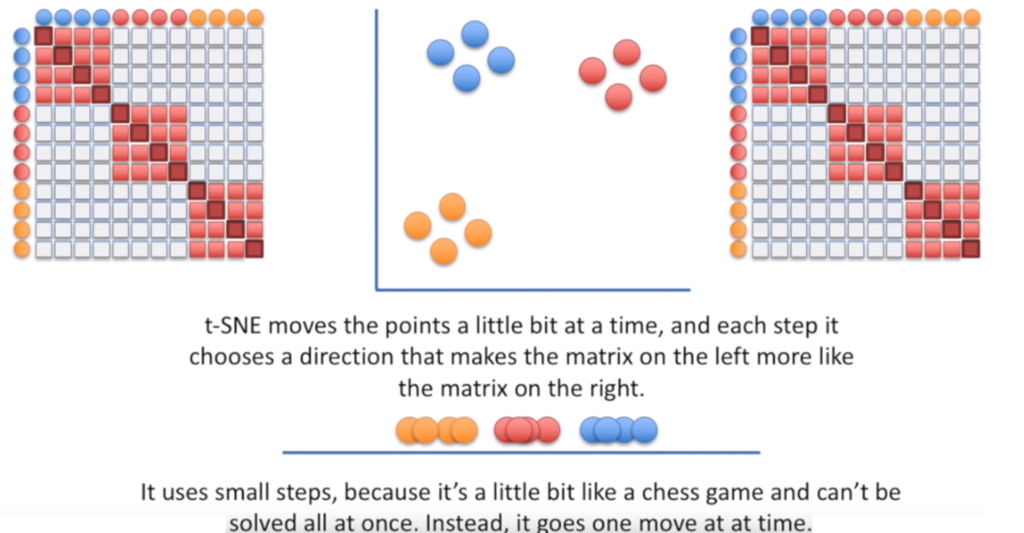
Algorytm t-SNE oblicza miarę podobieństwa między parami w przestrzeni o dużych wymiarach i przestrzeni o małych wymiarach. Następnie próbuje zoptymalizować te dwie miary podobieństwa. Mówiąc prościej, to t-SNE daje wyobrażenie, w jaki sposób dane są rozmieszczone w przestrzeni.
Również warto wspomnieć, że t-SNE można użyć do wybrania liczby klastrów w przypadku zagadnienia klasteryzacji. Jednak warto mieć na uwadze, że t-SNE nie jest podejściem grupującym i służy wyłącznie do eksploracji.
Ale jak t-SNE działa?
Super opowiedział o tym Josh Stramer na YouTube. W poniższym przykładzie wykorzystam jego wizualizacje, aby nie wymyślać koła na nowo :).
Weźmy jako przykład zbiór 12 punktów należących do trzech klas (niebieskie, czerwone i pomarańczowe).

Dla uproszczenia wyjaśniania metody podzielmy sposób działania algorytmu na mniejsze kroki.
Krok 1. Wyliczenie podobieństw wszystkich naszych danych
Na początku określamy zasięg, w ramach którego będziemy patrzeć na punkty. Zasięg ten (lub inaczej zakres kuli w wielowymiarowej przestrzeni) określić można za pomocą tzw. perplexity. Najczęściej zakres parametru wynosi od 5 do 50.
W naszym przykładzie jest na tyle mało danych, że możemy przyjąć wyliczania podobieństw między wszystkimi punktami.
Wybieramy pierwszy dowolny punkt (zaznaczony na szaro). Następnie wyliczamy odległość między nim a wybranym innym punktem. Dla tego szarego punktu rysujemy wyśrodkowany w tym punkcie rozkład normalny. A teraz nanosimy na niego wybrany wcześniej punkt zgodnie z wyliczoną odległością.

Dzięki użyciu rozkładu normalnego – jeśli punkty są daleko od siebie mają małe podobieństwo, a jeśli blisko to duże.
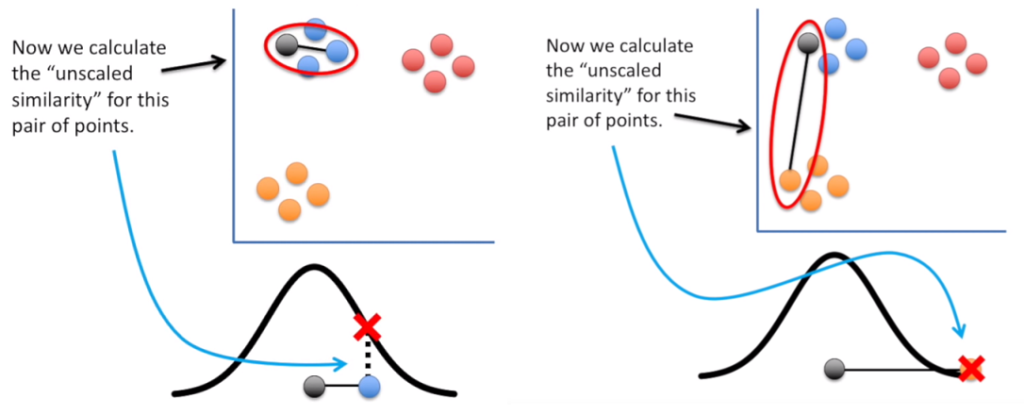
Tę operację powtarzamy dla wszystkich punktów we wcześniej określonym zasięgu.
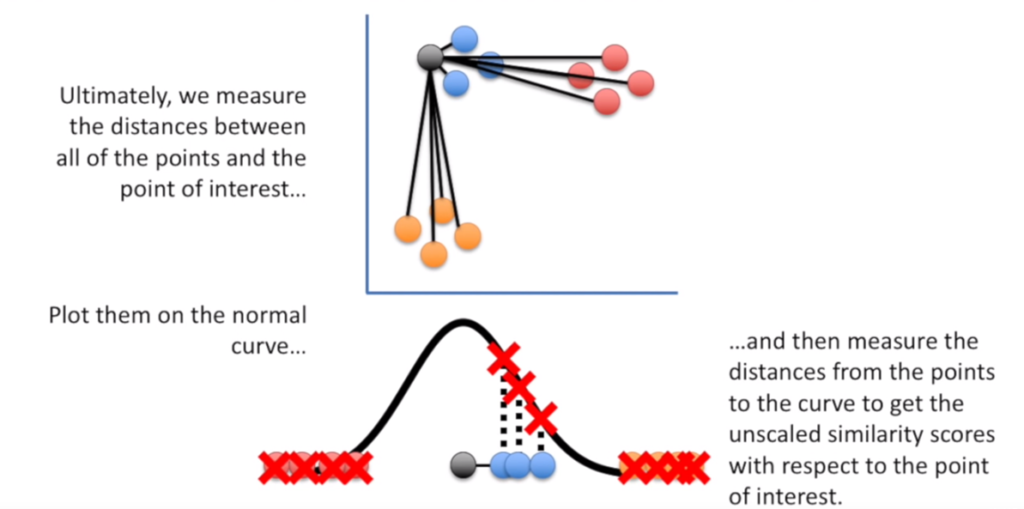
Mając wyliczone dystanse naniesione na rozkład normalny zamieniamy je na zestaw prawdopodobieństw wszystkich punktów (skalujemy, aby wszystkie wartości sumowały się do 1). Daje to tam zestaw prawdopodobieństw wszystkich punktów.
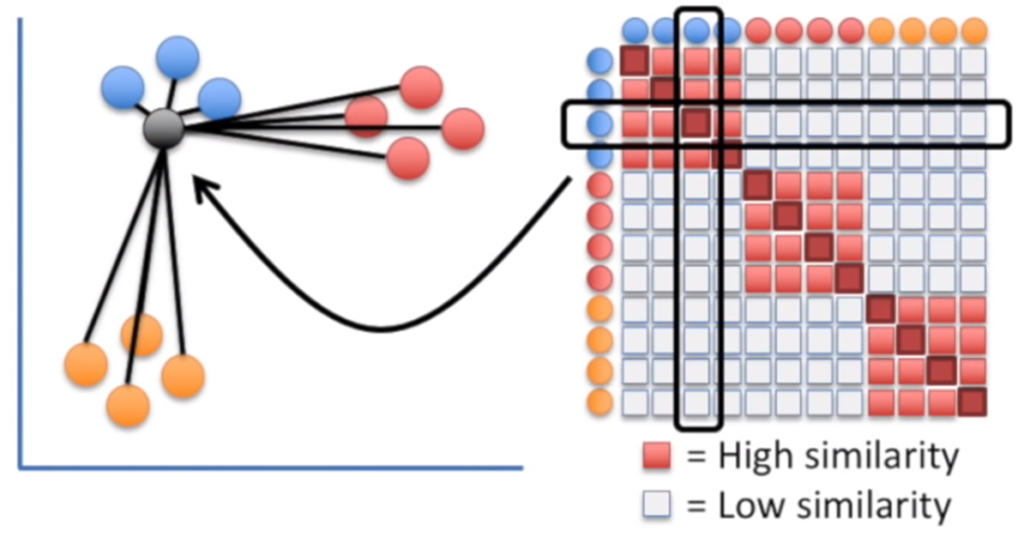
Oczywiście to ćwiczenie powtarzamy dla wszystkich punktów w naszym zbiorze.
Krok 2. Wyliczenie losowych podobieństw
Tutaj jest ten element, który sprawia, że nie można odtworzyć wyników t-SNE (moim zdaniem największa wada tej metody).
Dosłownie losowo rysujemy jak projekcja będzie wyglądać w mniejszym wymiarze (taki wymiar, jaki określimy). W tym przypadku zmieniamy przestrzeń dwuwymiarową (2D) na jednowymiarową (1D).

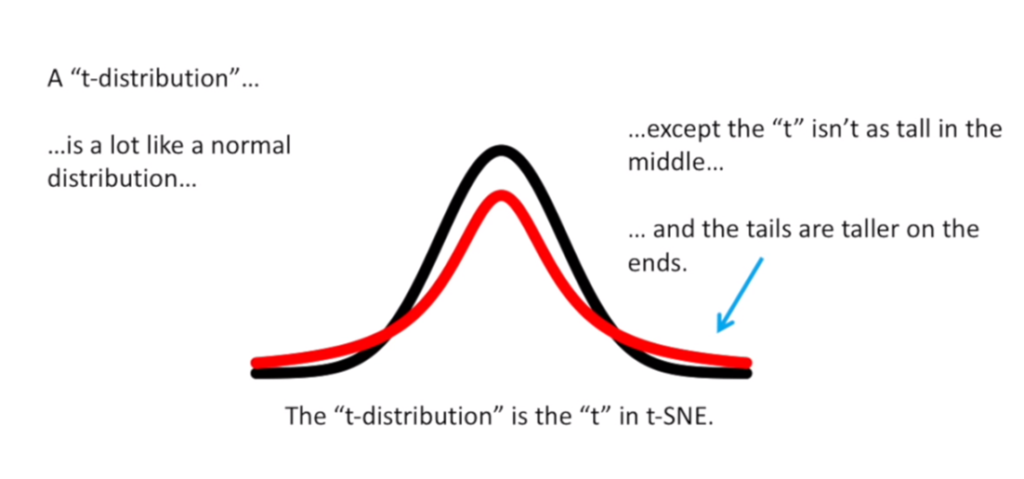
Krok 2 jest bardzo podobny do kroku 1, ale zamiast zastosowania rozkładu normalnego używamy rozkładu t Studenta o jednym stopniu swobody, który jest również znany jako rozkład Cauchy’ego. Czyli :
a) wyliczenie wszystkich odległości

b) wyliczenie podobieństw

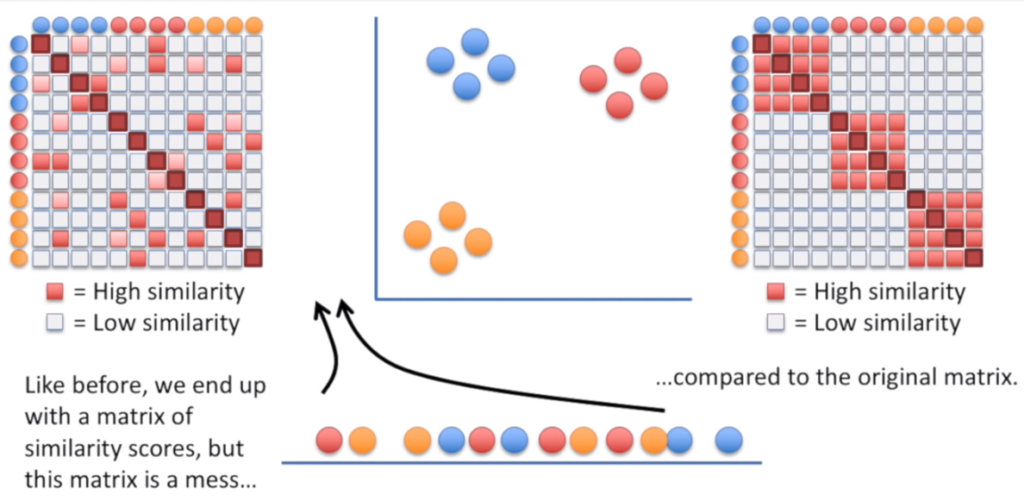
c) wyliczenie drugiego zestawu prawdopodobieństw w przestrzeni niskiego wymiaru (warto zwrócić uwagę, że ta macierz była losowa, dlatego nie będzie tak ładnie uporządkowana jak pierwotna).
Warto dodać, że autorzy metody zarekomendowali wybór rozkładu t-Studenta, ponieważ ma cięższe ogony niż rozkład normalny. Ciężkie ogony tak naprawdę pozwalają na lepsze modelowanie odległych od siebie punktów.
Krok 3. Odzwierciedlenie zestawów prawdopodobieństw.
Ostatnim krokiem jest to, aby zestaw prawdopodobieństw z przestrzeni niskiego wymiaru jak najlepiej odzwierciedlał te z przestrzeni wysokiego wymiaru. Tak naprawdę chcemy, aby te dwie struktury zestawów były podobne.

Różnicę między rozkładami prawdopodobieństwa przestrzeni mierzymy za pomocą dywergencji Kullbacka-Lieblera (KL). Daje ono podejście asymetryczne, które skutecznie porównuje wartości obu macierzy prawdopodobieństw. Dodatkowo metoda używa gradientu, aby zminimalizować naszą funkcję kosztu KL.
t-SNE vs PCA
Dla porównania zebrałem największe różnice pomiędzy dwoma metodami:
- PCA jest techniką matematyczną, ale t-SNE jest probabilistyczny. Czasami w t-SNE różne przebiegi z tymi samymi hiperparametrami mogą dawać różne wyniki, podczas gdy dla PCA zawsze będzie to ten sam wynik. Moim zdaniem to jest największa wada t-SNE.
- PCA jest techniką liniowej redukcji wymiarów, która dąży do maksymalizacji wariancji. Zatem polega głównie na tym, aby różne punkty umieszczać daleko od siebie w reprezentacji niższego wymiaru. Może to prowadzić do kiepskiej wizualizacji szczególnie w przypadku nieliniowych struktur, np. struktura naleśnika.
- t-SNE w przeciwieństwie do PCA zachowuje odległości pomiędzy parami odwzorowując nieliniowość i jest w stanie zinterpretować złożoną zależność wielomianową między cechami.
- t-SNE jest drogi obliczeniowo. W przypadku większych próbek (>100.000) i dużej ilości wymiarów (>100) wyliczenie t-SNE może potrwać nawet kilka godzin, gdzie PCA zakończy się w kilka sekund lub minut.
Przykłady
Znamy teorię, która stoi za t-SNE. Zatem przejdźmy do dwóch przykładów rozpoczynając od wczytania odpowiednich bibliotek:
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.manifold import TSNE
from sklearn import datasets
from mpl_toolkits.mplot3d import Axes3D
1) Swissroll
Są to dane w specyficzny sposób układające się w zwinięty naleśnik.
swissroll, color = datasets.make_swiss_roll(n_samples=5000, noise=0.1, random_state=42)
Sprawdźmy jeszcze jak te dane wyglądają w rzucie trójwymiarowym (3D).
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
print(f'Rozmiar danych (shape): {swissroll.shape}')
ax.scatter(swissroll[:,0], swissroll[:,1], swissroll[:,2], marker='x', c=color);

Teraz zobaczmy jak zwiększając perplexity zmienia się wygląd wizualizacji.
for perplexity in [5, 10, 30, 50]:
print(f'Perplexity = {perplexity}')
X_tsne = TSNE(learning_rate=100, perplexity=perplexity).fit_transform(swissroll)
fig = plt.figure(figsize=(10, 10))
ax = plt.axes(frameon=False)
plt.setp(ax, xticks=(), yticks=())
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=0.9, wspace=0.0, hspace=0.0)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=color, marker="x")
plt.show();


Na powyższym przykładzie w miarę łatwo dostrzec, że zwiększając zasięg sąsiadów coraz ładniej dane są „rozwałkowywane” w przestrzeni 2D.
2) Porównanie banków
Pamiętacie przykład z PCA? Wykorzystałem tutaj te same dane, aby porównać wyniki:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder
def apply_scalers(df, columns_to_exclude=None):
if columns_to_exclude:
exclude_filter = ~df.columns.isin(columns_to_exclude)
else:
exclude_filter = ~df.columns.isin([])
for column in df.iloc[:, exclude_filter].columns:
df[column] = df[column].astype(float)
df.loc[:, exclude_filter] = StandardScaler().fit_transform(df.loc[:, exclude_filter])
return df
df = apply_scalers(pd.read_excel('../data/data.xlsx', sheet_name='dataframe'), columns_to_exclude=['Nazwa'])
oraz zwizualizujmy sobie wyniki tak jak wcześniej:
import pandas as pd
import seaborn as sns
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
# kolumny do wykluczenia (te na których nie chcemy PCA)
exclude_filter = ~df.columns.isin(['Nazwa'])
X_tsne = TSNE(learning_rate=10, perplexity=5).fit_transform(df.loc[:, exclude_filter])
trace0 = go.Scatter(
x = X_tsne[:, 0],
y = X_tsne[:, 1],
text=df['Nazwa'],
textposition="top center",
name = 'Piony',
mode = 'markers+text',
marker = dict(
size = 10,
color = 'rgb(228,26,28)',
line = dict(
width = 1,
color = 'rgb(0, 0, 0)'
)
)
)
data = [trace0]
layout = dict(title = 'Podobieństwo Banków na podstawie t-SNE'
)
fig = dict(data=data, layout=layout)
iplot(fig, filename='styled-scatter')
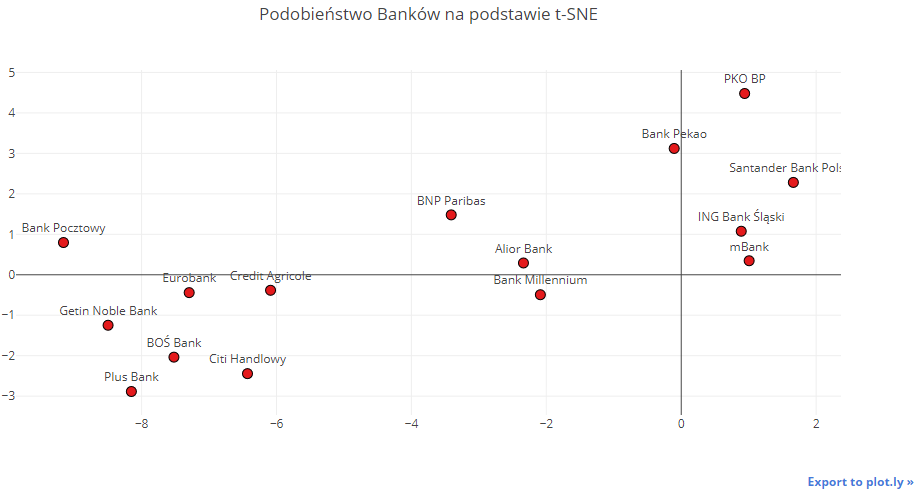
Wyszły bardzo ciekawe wyniki! Okazuje się, że te wyniki grup zbliżonych do siebie Banków są bardzo zbliżone do metody PCA.
Powodzenia w Waszych redukcjach wymiarów!
Pozdrawiam serdecznie




masz brzydką literówkę w tym zdaniu 😀
„PCA jest techniką liniowej redukcji wymiarów, która dąży do maksymalizacji wariancji. Zatem polega gównie wy różne punkty umieszczać daleko”
haha, powiedziałbym że piekna literówka 🙂 Aż się uśmiałem jak ją zobaczyłem. Dziękuje 😀
Pingback: Las izolacji (isolation forest) - jak to działa? - Mirosław Mamczur
Pingback: Jak wykryć oszusta (fraud) za pomocą autoenkodera? - Mirosław Mamczur
Pingback: Jak zwizualizować word embedding? - Mirosław Mamczur