
– Tato…. jak działa lodówka? – zapytała Jagódka stojąc z siostrą przed otwartą chłodziarką i szukając owoców.
– A co już wiesz o lodówce? – zapytałem Jagódkę.
– No, wiem, że chłodzi nasze jedzonko i picie. I jeszcze, że niska temperatura chroni nasze jedzenie, żeby się nie zepsuło.
– I glosno bucy! – dodała Otylka.
– Bardzo dobrze moje Księżniczki. Dzięki niskiej temperaturze lodówka opóźnia proces namnażania szkodliwych mikroorganizmów co powoduje, że jedzonko, warzywa i owoce dłużej są dobre! A buczy, bo jest podłączona do prądu i się grzeje.
– Ale jak to się grzeje? – zapytała ze zdziwieniem starsza córeczka.
– Grzeje się urządzenie zwane skraplaczem. To takie poskręcane rurki z tyłu lodówki. W tych rurkach jest taki specjalny gaz zwany czynnikiem chłodniczym. I ten gaz ciągle na przemian się skrapla i paruje i zmienia swoją temperaturę.
– Ciekawe. Tato, a czy to, co robisz w pracy też potrafisz tak wytłumaczyć?
Ostatnio w pracy budowałem bardzo ciekawy model do wyłapywania tzw. fraudów inwestycyjnych. Bardzo zależało nam, aby mieć pewność, że nasz partner biznesowy rozumie, dlaczego model podjął taką, a nie inną decyzję. Przecież model ma wspierać nasz zespół do wyłapywania przestępców! Zatem eksperci domenowi muszą rozumieć jak działa i w razie błędów dać nam znać byśmy go poprawili.
Do tej pory korzystałem głównie z biblioteki Shap w celu wyjaśnienia modelu. Jak z niej korzystać pisałem TUTAJ. I znalazłem ciekawą alternatywę, która nazywa się Explainer Dashboard!
W tym wpisie przeprowadzę Cię właśnie przez pakiet Explainer Dashboard napisany przez Oege Dijk i pokażę, jakie daje możliwości w celu lepszego zrozumienia działania modelu.

Co to Explainer Dashboard?
Jest to pakiet w Pythonie, który ułatwia szybkie wdrażanie dashboardu (aplikacji internetowej) pomagającego w wyjaśnieniu działania modelu uczenia maszynowego. Zapewnia interaktywne wykresy dotyczące wydajności modelu, mocy charakterystyk, udziału cechy w indywidualnych prognozach, analizy „co by było, gdyby” czy wizualizacje poszczególnych drzew!
Explainer Dashboard dostosowuje metryki i wykresy do problemu, jaki rozwiązuje model (klasyfikacja / regresja).
Co ważne – biblioteka jest ciągle rozwijana i dokładane są kolejne funkcjonalności:

Natomiast główną jej wadą jest to, że nie wspiera jeszcze sieci neuronowych.
GitHub: https://github.com/oegedijk/explainerdashboard
Przykład do poklikania na herokuapp: http://titanicexplainer.herokuapp.com/
Dobra, to przejdźmy przez konkretne metryki, cechy i wykresy, na przykładzie nieśmiertelnych danych Titanica.
Wczytanie biblioteki Explainer Dashboard
Nie musisz znać budowania dashboardów w dash i wykresów w plotly. Próg wejścia, aby postawić własny dashboard, jest minimalny. Wystarczy zainstalować bibliotekę:
conda install -c conda-forge explainerdashboard
i można się już cieszyć wczytaniem pakietów:
from explainerdashboard import ClassifierExplainer, ExplainerDashboard
from explainerdashboard.datasets import titanic_survive, titanic_names
import xgboost as xgb
Zbudujemy prosty model korzystając z jednego z moich ulubionych modeli XGBoost:
X_train, y_train, X_test, y_test = titanic_survive()
train_names, test_names = titanic_names()
model = xgb.XGBClassifier(n_estimators=50, max_depth=5)
model.fit(X_train, y_train)
Naszym celem nie jest budowa najlepszego modelu, tylko zrozumienie jak działa. Dlatego buduję bez zabawy w wybór optymalnych cech i optymalizację hiperparametrów.
Teraz dodajmy jeszcze ładniejszy opis charakterystyk:
feature_descriptions = {
"Sex": "Gender of passenger",
"Gender": "Gender of passenger",
"Deck": "The deck the passenger had their cabin on",
"PassengerClass": "The class of the ticket: 1st, 2nd or 3rd class",
"Fare": "The amount of money people paid",
"Embarked": "the port where the passenger boarded the Titanic. Either Southampton, Cherbourg or Queenstown",
"Age": "Age of the passenger",
"No_of_siblings_plus_spouses_on_board": "The sum of the number of siblings plus the number of spouses on board",
"No_of_parents_plus_children_on_board" : "The sum of the number of parents plus the number of children on board",
}
i możemy odpalać explainer dashboard:
explainer = ClassifierExplainer(
model, X_test, y_test,
cats=['Deck', 'Embarked',
{'Gender': ['Sex_male', 'Sex_female', 'Sex_nan']}],
cats_notencoded={'Embarked': 'Stowaway'}, # defaults to 'NOT_ENCODED'
descriptions=feature_descriptions, # adds a table and hover labels to dashboard
labels=['Not survived', 'Survived'], # defaults to ['0', '1', etc]
idxs = test_names, # defaults to X.index
index_name = "Passenger", # defaults to X.index.name
target = "Survival", # defaults to y.name
)
db = ExplainerDashboard(explainer,
title="Titanic Explainer", # defaults to "Model Explainer"
shap_interaction=True, # you can switch off tabs with bools
)
db.run(port=2021)

Gratulacje. Explainer Dashboard postawiony. Teraz możemy przejść do zrozumienia działania naszego modelu.

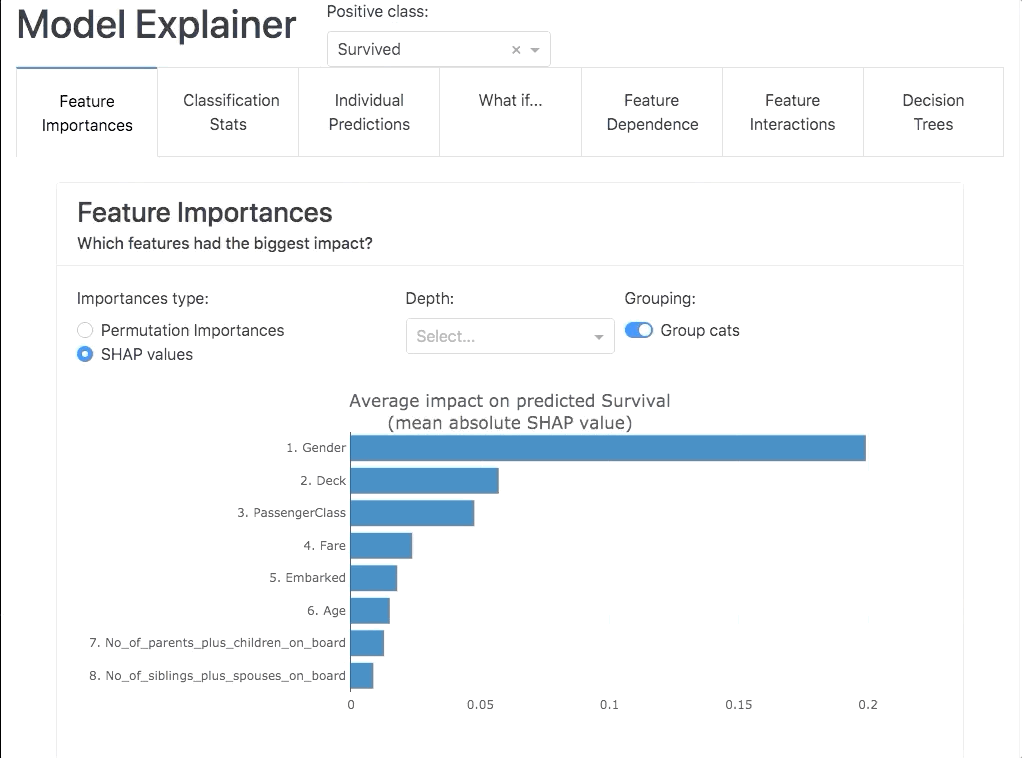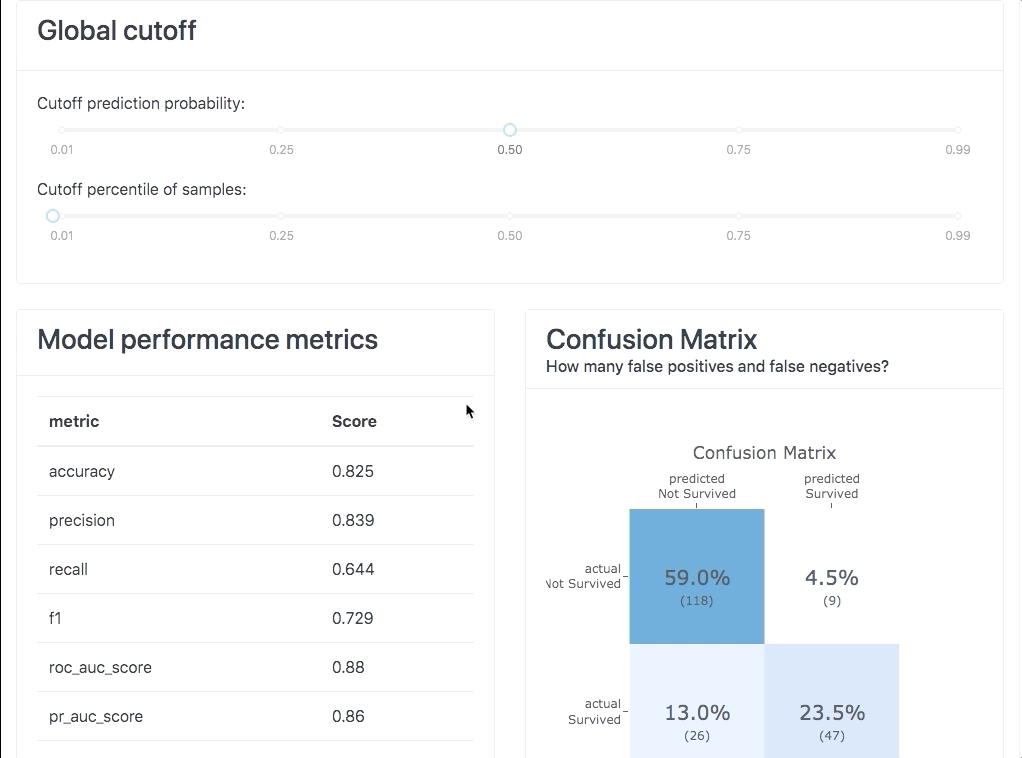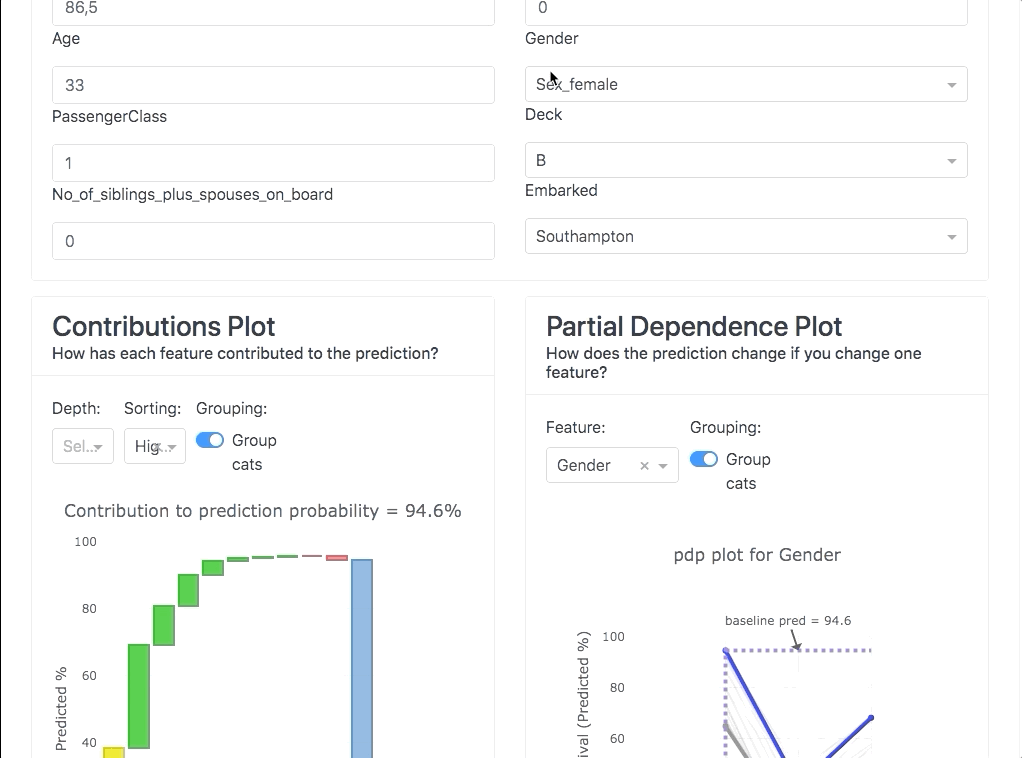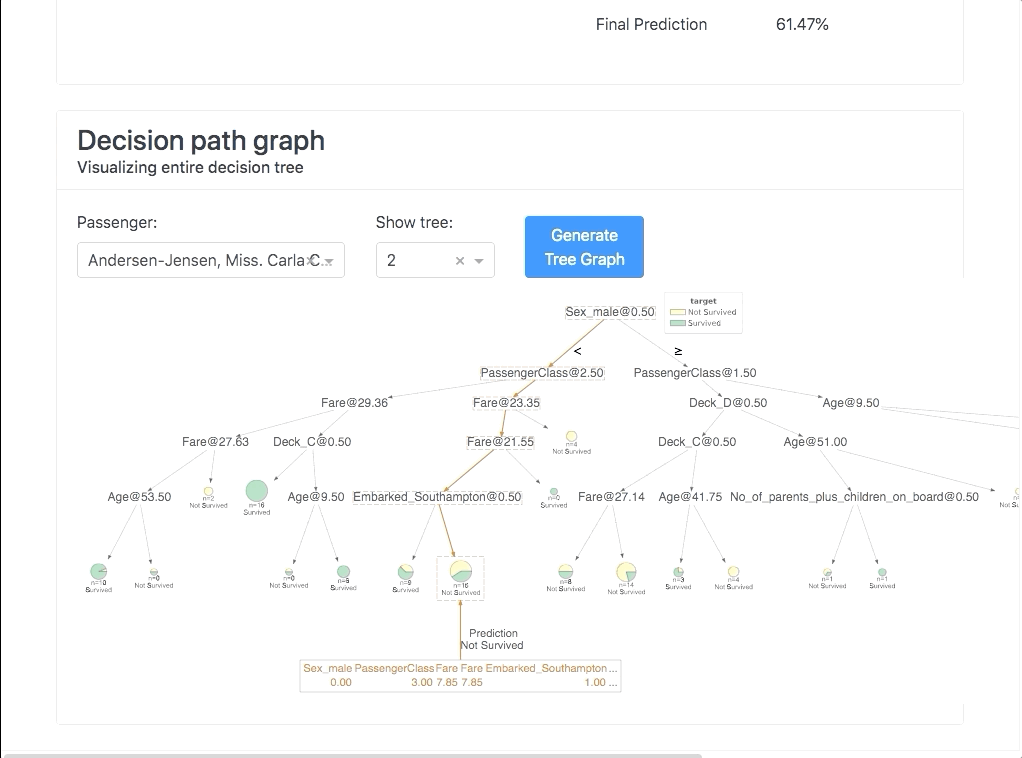
Ważność cech (ang. Feature importance)
W tym miejscu znajdziemy odpowiedź na pytanie: „które charakterystyki mają największy wpływ na moc modelu?”. W raporcie odnajdziemy informację na temat dwóch metryk: wartości Shapley’a i znaczenia permutacji!

Wartość Shapley’a (ang. Shap Values)
Wartość Shapley’a to metoda przypisywania zysku pomiędzy graczy w zależności od ich wkładu w całkowitą grę. Gracze współpracują ze sobą w koalicji i czerpią z niej pewien zysk. Intuicyjnie można powiedzieć, że wartość Shapley’a mówi ile dany gracz powinien spodziewać się zysku z całości biorąc pod uwagę jaki średnio ma wkład w grze w danej koalicji.
Jeśli interesuje Cię szczegółowy opis działania i wyliczania wartości Shapley’a, to zapraszam do artykułu na blogu: https://miroslawmamczur.pl/wartosc-shapleya-interpretacja-modeli-blackbox/
Ważność permutacji (ang. Permutation importance)
Pomysł jest następujący: ważność charakterystyki można zmierzyć, patrząc na to, jak bardzo zmniejsza się wynik metryki, która nas interesuje (np. F1), gdy pozbędziemy się konkretnej charakterystyki. Dla takiego sprawdzenia można usunąć cechę ze zbioru danych, ponownie przeszkolić estymator i sprawdzić wynik. Wymaga to jednak sporo czasu, gdyż wiąże się z ponownym przeliczeniem modelu po usunięciu każdej cechy. I jednak to będzie inny model niż ten, który aktualnie posiadamy, więc nie odpowie nam taki test w 100% czy tak samo będzie dla modelu wyjściowego.
Na szczęście ktoś mądry wymyślił, że zamiast usuwać cechę, możemy ją zastąpić szumem losowym – kolumna dalej istnieje, ale nie zawiera już przydatnych informacji. Ta metoda działa, jeśli szum jest pobierany z tego samego rozkładu, co oryginalne wartości cech. Najprostszym sposobem uzyskania takiego szumu jest przetasowanie charakterystyki.
Podsumowując, ważność permutacji jest techniką sprawdzenia charakterystyk, którą można zastosować dla dowolnego dopasowanego estymatora, jeśli dane są tabelaryczne. Jest to metoda szybka i przydatna w przypadku estymatorów nieliniowych i nieprzejrzystych.

Ważność cechy permutacji definiuje się jako spadek wyniku modelu, gdy wartość pojedynczej cechy jest losowo przetasowana. Ta procedura przerywa związek między cechą a celem, a zatem spadek wyniku modelu wskazuje, jak bardzo model zależy od tej konkretnej charakterystyki.
Ujemna wartość mówi, że po przelosowaniu cechy moc modelu dla danej metryki rośnie! Zatem wynik bliski zero lub ujemny oznacza, że cecha niewiele dodaje do modelu 😀.
Statystyki klasyfikacji (ang. Classification stats)
W tym miejscu znajdziemy ogólne informacje na temat modelu wraz z metrykami i wizualizacjami pokazującymi, czy model klasyfikacji działa rozsądnie.
Na samej górze zakładki możemy ustawić globalny dla całej zakładki próg odcięcia (ang. cut-off). Model klasyfikacji zwraca prawdopodobieństwo wystąpienia danego zdarzenia. Jeśli to prawdopodobieństwo będzie poniżej wartości cut-off, to przyjmiemy wartość 0, a powyżej 1. Dla tak ustawionego progu odcięcia będziemy mieli wyliczone w tej zakładce wykresy i metryki, które potrzebują przewidywaną konkretną klasę, a nie samo prawdopodobieństwo.

Oczywiście na każdym wykresie będziemy mogli ten próg zmieniać i wizualizować sobie jak wpłynęłoby to na politykę użycia danego modelu.
Metryki & Confusion Matrix
Na samym początku znajdziesz wszelkie znane metryki, które używane są przy modelach klasyfikacyjnych, takie jak:
- accurency,
- precision,
- recall,
- f1,
- roc auc,
- precision-recall,
- log loss.
W tym artykule nie będę się rozpisywał na temat każdej z metryk. Jeśli którejś nie kojarzysz proponuję zajrzeć do dokumentacji sklearn, gdzie jest to super opisane: TUTAJ.
Dodatkowo znajdziesz Confusion Matrix. W tym miejscu istnieje możliwość pobawienia się progami odcięcia, aby dobrać optymalny poziom. Oczywiście, jeśli dane były zbalansowane, to wartość 0.5 powinna być dobrym punktem startowym. Następnie możesz zmieniać próg odcięcia w górę i w dół, aby wspólnie z biznesem zobaczyć jak model działa i klasyfikuje klientów.

Wykres precyzji (ang. Precision plot)
Pomyśl w ten sposób: mamy wynik prawdopodobieństwa naszego modelu i sortujemy obserwacje od najmniejszego do największego. Następnie dzielimy obserwacje na 7 grup (ustawiłem parametr bin_size = 7, bo ładnie wykres wyglądał 😉).
A teraz rysujemy wykres, gdzie:
- niebieskim wykresem kolumnowym zaznaczamy liczność obserwacji w danej grupie,
- na pomarańczowo wykresem liniowym % osób z danej grupy z rzeczywistą pierwszą klasą (u nas osoby, które przeżyły ucieczkę z Titanica)
- zielonym wykresem liniowym % osób z drugiej klasy (pechowcy, którzy nie uratowali się z Titanica).
Tadam:

Na powyższym wykresie, osiągnąłem oczekiwany kształt linii pomarańczowej i zielonej. Czyli wraz ze wzrostem wartości prawdopodobieństwa zwracanego przez model (oś X) rośnie liczba osób co przeżyli (linia pomarańczowa) i maleje liczba osób co nie przeżyła (zielona linia). Gdyby linie na całej długości byłby płaskie (ciągle w okolicach 50%) lub co chwila się przecinały (raz wyżej pomarańczowa, a raz zielona), oznaczałoby to, że model nie potrafi prawidłowo różnicować klientów i nie działa poprawnie.
Uwaga! Wykres mocno zależy od metody podziału, którą wybierzesz i na ile części podzielisz. Zobacz jak dla tego samego modelu wygląda kształt wykresu w sytuacji znacznego zwiększenia ilości przedziałów:

Tutaj można prosto zaobserwować, że model bardzo dobrze odróżnia osoby, które przeżyły – pomarańczowa linia pokazuje 100%, co oznacza, że w tych grupach model się w ogóle nie pomylił. Natomiast widać, że na środku pomiędzy wartością 0.25 a 0.60 model działa jako tako.
Nie myśl, że z modelem coś jest nie ok, tylko wtedy rzuć okiem na niebieski słupek. W tym przypadku zobacz, że w grupie jest po 10 osób. Przy takiej liczbie osób 1 osoba stanowi 10%. Stąd nie ma co się dziwić takimi wahnięciami i po prostu bardziej zagregować dane 😅.

Wykres klasyfikacji (ang. Classification plot)
Tutaj znajdziesz podsumowanie jak wygląda populacja poniżej i powyżej cut off’a.
Jak złapiesz za suwaczek i będziesz nim sterował w lewo i w prawo, to zobaczysz fajną wizualizację jak przeskakują osoby pomiędzy klasami. Pomoże Ci to wytłumaczyć, jak poziom cut-off’a będzie wpływał na biznes, kiedy zacznie korzystać z modelu i pomoże w wybraniu parametru.

ROC AUC & PR AUC
Skrót AUC (Area Under Curve) oznacza obszar pod krzywą. Zatem, aby mówić o wyniku ROC AUC czy PR AUC musimy najpierw zdefiniować czym jest ROC i PR 😊.
W skrócie, krzywa ROC to wykres, który wizualizuje kompromis pomiędzy współczynnikiem prawdziwie dodatnim (True Positive Rate) i fałszywie dodatnim (False Positive Rate).
Można to zinterpretować w ten sposób, że ta metryka pokazuje, jak dobry jest ranking przewidywań modelu. Informuje, jakie jest prawdopodobieństwo, że losowo wybrana pozytywna instancja ma wyższą pozycję w rankingu niż losowo wybrana negatywna instancja.
PR natomiast (Precision-Recall) jest to krzywa, która łączy precyzję (precision / PPV) i przywołanie (recall /TPR) w jednej wizualizacji. Dla każdego progu obliczasz Precision i Recall i wykreślasz je. Im wyższa krzywa na osi Y, tym lepsza wydajność modelu. Oczywiście im wyższa wartość przywołania, tym niższa precyzja. Warto rozważyć punkt odcięcia (cut-off), gdy na wykresie na osi OY (czyli prezycja) zaczyna szybko spadać w kierunku wartości 0.
Z tego powodu, jeśli bardziej zależy ci na klasie pozytywnej, lepszym wyborem jest użycie PR AUC, która jest bardziej wrażliwa na poprawę w klasie pozytywnej.
Drugą ważną rzeczą jest to, że ROC AUC może zaburzyć obraz, jeśli dane są mocno niezbalansowane. Wynika to z tego, że odsetek fałszywie pozytywnych wyników wysoce niezbalansowanych zbiorów danych jest obniżony z powodu dużej liczby wyników prawdziwie negatywnych.

Krzywa podnoszenia (ang. Lift curve)
Jest to wykres, który odpowiada na pytanie ile razy jest lepiej niż byśmy losowali klientów. Była to podstawowa informacja dla naszych partnerów biznesowych kiedy tworzyłem modele CRM J
Na poniższym przykładzie widać, że dla progu cut off = 0.59 lift wynosi 2.55. Nasz model dla tego cut off’a wskazuje na pozytywną klasę dla 93.0%, a model losowy przy tym progu odcięcia wskazałby na 36.5% (93%/2.5).

Skumulowana precyzja (ang. Cumulative precision)
Na tym wykresie widzimy procentowy udział każdej klasy, jeśli wybierzemy top X % klientów. W poniższym przykładzie dla cut off równego 0.59 widać, że poniżej tej wartości jest 22.5% populacji, z czego osoby, które przeżyły stanowią nieco ponad 91%, a zginęło niecałe 9%.

Indywidualna predykcja (ang. Invidual prediction)
Tutaj dzieje się magia dla biznesowego odbiorcy. Ponieważ jak siadamy z ekspertami domenowymi możemy im odczarować każdy konkretny przypadek, dlaczego model podjął taką a nie inną decyzję i co na to wpłynęło i w jakim stopniu.
W górnej części zakładki możemy wybrać konkretną obserwację. W naszym przypadku zamiast losować wziąłem pierwszą osobę z góry.
Zobaczymy, jakie dla niej model zwrócił prawdopodobieństwo. W tym przypadku widać, że Pani Florence Briggs ma prawdopodobieństwo przeżycia 90.6%.
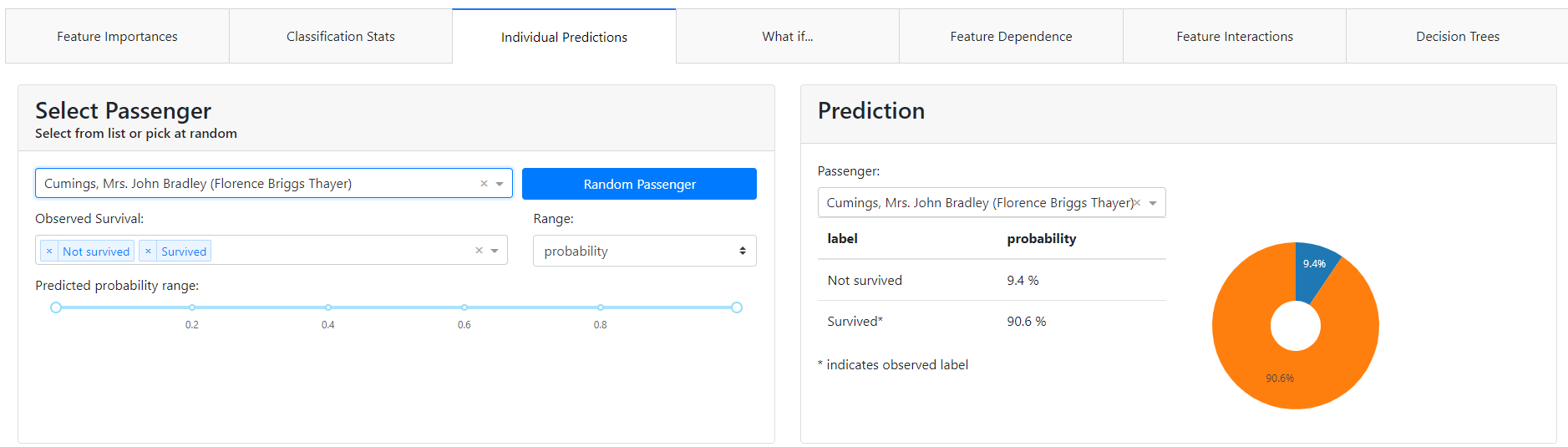
Zobaczmy, dlaczego 😎.
Wykres zależności częściowych (ang. Partial dependece plot)
Wykres zależności częściowych (PDP) pokazuje marginalny wpływ cechy na przewidywany wynik modelu uczenia maszynowego. Zależność częściowa działa na zasadzie marginalizacji wyników modelu uczenia maszynowego nad rozkładem cech ze zbioru, tak że funkcja pokazuje związek między interesującymi nas cechami ze zbioru, a przewidywanym wynikiem.
Jeśli cecha, dla której obliczyłeś PDP, nie jest skorelowana z innymi cechami, to PDP doskonale przedstawiają, w jaki sposób cecha wpływa na średnią prognozę. W przypadku nieskorelowanym interpretacja jest jasna: wykres zależności częściowych pokazuje, jak zmienia się średnia predykcja w twoim zbiorze danych, gdy j-ta cecha zostanie zmieniona.
Natomiast robi się to bardziej skomplikowane, gdy funkcje są skorelowane. Tworzymy nowe punkty danych w obszarach rozkładu cech, w których rzeczywiste prawdopodobieństwo jest bardzo niskie (na przykład jest mało prawdopodobne, aby ktoś miał 2 metry wzrostu, ale ważył mniej niż 50 kg) i to może troszkę zaburzyć obraz.
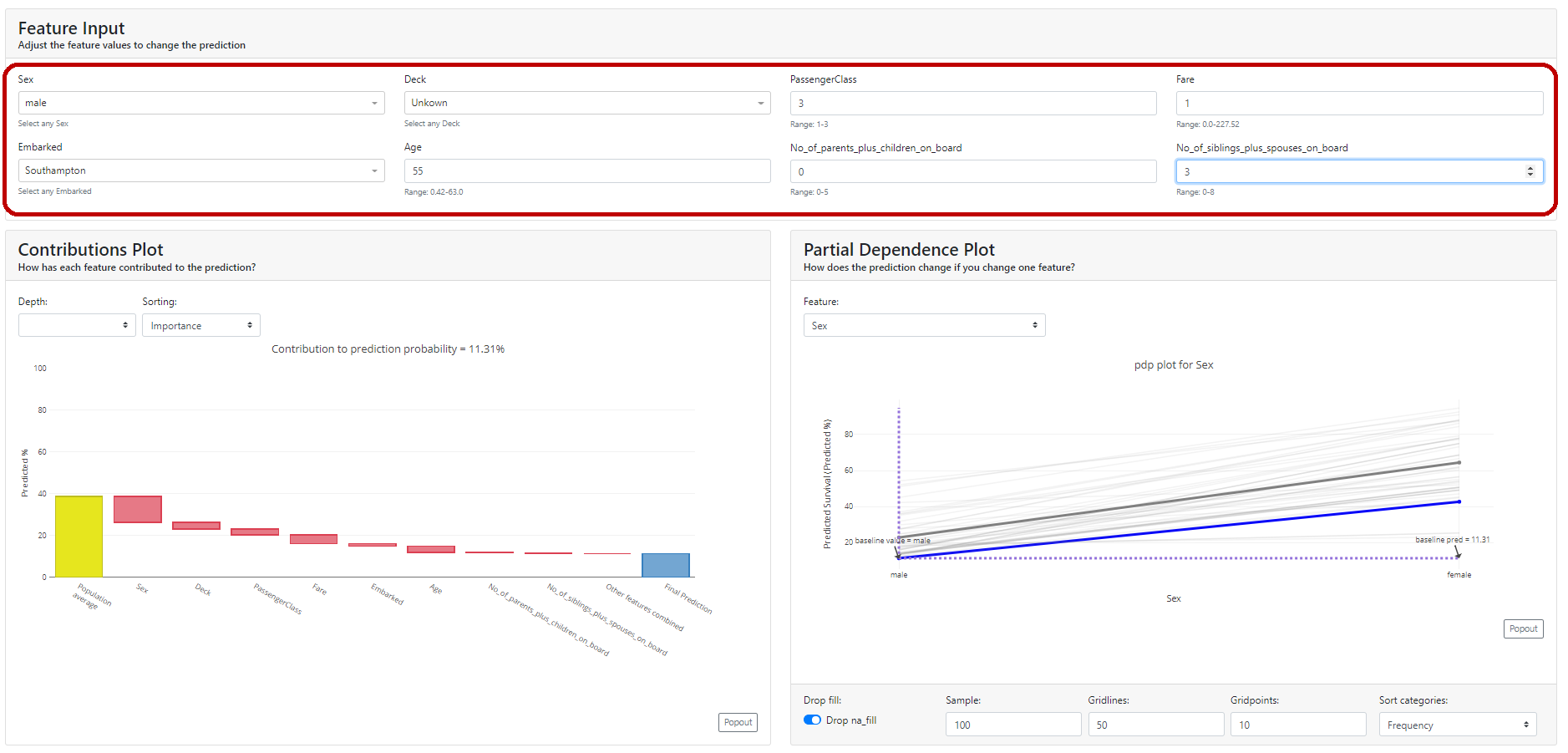
Spójrzmy na nasz przykład. Wybieramy cechę płeć i widzimy, że dla naszego przypadku (niebieska pogrubiona linia) gdyby zmienić płeć z kobiety na mężczyznę, to prawdopodobieństwo przeżycia spadłoby z 90.6% na … 40%. Również na wykresie mamy pokazaną wartość średnią dla próbki – pogrubiona szara linia.

Możesz przyglądnąć się każdej cesze i lepiej zrozumieć działanie modelu na całości. Poniżej wiek – z wykresu można odczytać, że nie miał on aż tak dużego znaczenia (w aktualnie sprawdzanym modelu!).

Wykres kontrybucji (ang. Contributions plot)
Wykres kontrybucji działa na podobnej zasadzie jak PDP z tą różnicą, że pokazuje kontrybucję każdej zmiennej indywidualnie jaki miała wpływ na ostateczną predykcję.
Widać, że w naszym przypadku cechą, która najwięcej wnosi na plus jest płeć, a drugą z kolei dla tej osoby jest cena, jaką zapłacili za bilet.
Dodatkowo kolory wskazują, co zadziałało na zwiększenie prawdopodobieństwa przeżycia, a na czerwono na zmniejszenie prawdopodobieństwa przeżycia.

Wszystkie wyniki masz zebrane poniżej w tabeli:

A co jeśli (ang. What if)
Moim zdaniem to najciekawsza sekcja. Pokazuje to samo, co widzieliśmy w zakładce z indywidualną oceną z tą różnicą, że …
… możemy modyfikować wszystkie cechy wg uznania i sprawdzić jaki to miało wpływ na model.
Jeśli przy tej zakładce usiądziesz z ekspertami domenowymi mogą oni zweryfikować czy model działa intuicyjnie i mogą dać ciekawy wsad odnośnie tego, gdzie ich zdaniem model nie do końca poprawnie się zachowuje.
Zależności pomiędzy cechami (ang. Feature dependence)
Tutaj mamy dwa wykresy, które pokażą nam jak wartości danych charakterystyk wpływa na zwiększenie lub zmniejszenie prawdopodobieństwa na podstawie wartości Shapley’a.
Więcej o samym Shap TUTAJ.
Shap Summary
W tym miejscu w podstawowej wersji otrzymujemy wykres shapa dla charakterystyk, który już znamy z pierwszej zakładki. Różni się natomiast tym, że możemy wyświetlić go w szczegółach i wówczas rysuje nam obserwacje. Możemy wybrać konkretną obserwację i zobaczyć gdzie na tle całości się znajduje.
Dodatkowo z wykresów możemy zauważyć, które cechy wpływają na wzrost prawdopodobieństwa przeżycia (te na prawo od 0 na osi OX). Kolorem mamy narysowaną skalę (niebieski mniejsze wartości dla danej charakterystyki, czerwony większe).

Shap Dependece
Tutaj możemy przyjrzeć się dokładniej konkretnej charakterystyce jak wygląda rozkład pod względem wartości shapley’a.
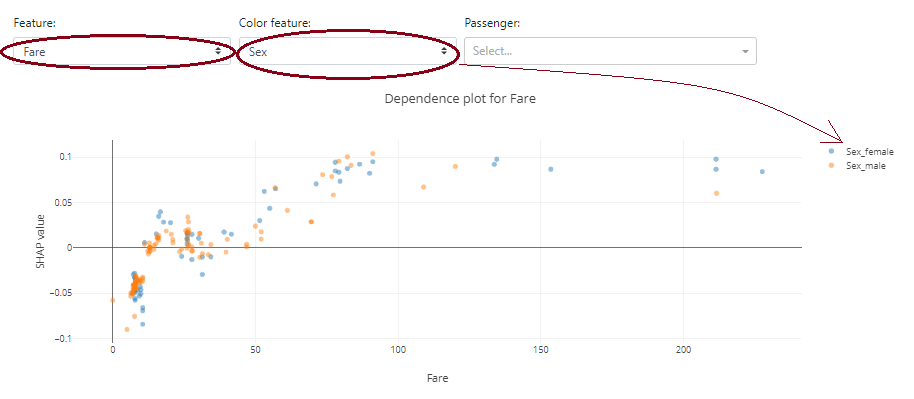
Poniżej możecie zobaczyć jak mocno płeć w przypadku danych Titanica wpływa na przeżywalność:

Ciekawą opcją jest to, że wykres dobierany jest do rodzajów danych. W przypadku danej ciągłej „Fare” zamiast wykresu wiolonczelowego prezentowany jest wykres punktowy.
Pamiętaj, że możesz dodać dodatkowy kolor na podstawie innej charakterystyki, aby zobaczyć drugą zmienną.
Poniżej na pierwszy rzut oka nie widać zależności ceny biletu („Fare”) od płci – kolory niebieskie i pomarańczowe są wymieszane. Natomiast od razu widać, że sama zmienna „Fare” ma wpływ na dodatnie prawdopodobieństwo przeżycia – im wyższa wartość „Fare”, tym więcej cech ma dodatnią wartość Shapleya.
Decision Trees
W tej zakładce mamy zwizualizowane jak kolejne drzewa się liczyły i możemy zwizualizować konkretne drzewo. Dzięki temu możemy zajrzeć w „bebechy”.
Warto podkreślić, że w zależności od modelu, jaki mamy, mogą to być odrobinę różne wykresy.
Poniżej pokazałem dwa przykłady:
a) dla Lasu losowego, gdzie mamy pokazane każde z 50 drzew, jakie dało prawdopodobieństwo dla danej osoby

b) dla XGBoosta, gdzie pokazane jest każde kolejne drzewo:

Oprócz tego dla algorytmów drzewiastych możemy wygenerować konkretne drzewo jak wyglądało:

Uwaga! W moim przypadku, abym mógł wyświetlić drzewo musiałem postępować zgodnie z informacją, aby zainstalować pakiet dtreeviz jak opisano w instrukcji instalacji: https://github.com/parrt/dtreeviz.
Statystyki regresji (ang. Regression stats)
W tym miejscu znajdziemy ogólne informacje na temat modelu regresji wraz z metrykami i wizualizacjami pokazującymi, czy model regresji działa rozsądnie. Zakładka ta występuje jeśli nasz model przewiduje wartość ciągłą, taką jak cena produktu, wzrost czy dochód.
Na samym początku znajdziesz wszelkie znane Ci metryki, które używane są przy modelach regresji, takie jak:
- RMSE,
- MAE,
- R2.
Również na pierwszy rzut oka zamiast Confiusion Matrix mamy wykres „Predicted vs Actual„. Od razu obrazuje jak mocno zmienna przewidywana przez model różni się od wartości rzeczywistej.

W naszym przypadku widzimy, że model przewidujący cenę biletu („Fare”) znacznie lepiej radził sobie z przewidywaniem niskich kwot. Niebieskie punkty obrazujące rzeczywiste wartości są bliższe wartości przewidywanej (pomarańczowej linii).
Dodatkowo na wykresie możesz prosto wybrać skalę logarytmiczną.
Wykres reszt (ang. Residuals)
Innym wykresem obrazującym jak i gdzie model się myli jest wykres reszt.
Reszty są to różnice pomiędzy wartością rzeczywistą, a wartością przewidywaną przez model. Od razu z wykresu zobaczysz, na których wartościach model niedoszacowuje przewidywanej ceny biletu, a na których przeszacowuje.

Wykres vs Cecha (ang. Plot vs feature)
Dzięki temu wykresowi można lepiej zrozumieć, jak dla wybranej charaktystyki wygląda rozkład:
- wartości rzeczywistych,
- wartości przewidywanych,
- reszt,
- stosunku reszt,
- logarytmu reszt.
Warto podkreślić, że w zależności od rozkładu wybranych cech wykres będzie przyjmował różne formy: wykres rozrzutu albo wykres skrzypcowy.

Podsumowanie Explainer Dashboard
To już wszystko, czym chciałem się z Tobą podzielić. Jeśli czegoś zabrakło to napisz do mnie lub zostaw proszę informację w komentarzu.
Ah! Jeszcze jedno. Explainer Dashboard możecie przystosować do siebie, tzn. odpalić tylko odpowiednie zakładki, wystawić aplikacje w nowym oknie lub odpalić w Jupiter Notebooku.
Mam nadzieję, że będziecie mogli skorzystać z tego pakietu do przedstawienia wyników swoich prac.
Pozdrawiam z całego serducha,




Pingback: NannyML - walidacja modelu bez danych rzeczywistych (ground truth)! - Mirosław Mamczur
Pingback: Newsletter Dane i Analizy, 2021-05-24 | Łukasz Prokulski