
– Oti, jaką chciałabyś mieć super moc? – zapytała Jagódka siostrzyczki.
– Latania – odpowiedziała od razu Otylka.
– A ja rozmawiania ze zwierzątkami, bo je bardzo kocham – odpowiedziała Jagoda. – A Ty tatusiu?
– Chyba leczenia. Mógłbym Was uleczyć od razu jak zachorujecie. Mógłbym także leczyć innych ludzi, aby nie było chorób na świecie.
Super byłoby mieć taką moc. Niestety to niemożliwe. Niemniej jednak głęboko wierzę, że dzięki sztucznej inteligencji i uczeniu maszynowemu można zmieniać świat na lepsze 💓.
Dzisiaj pokażę Ci przykład (tutorial) jak sieci konwolucyjne CNN mogą zostać wykorzystane do zbudowania naprawdę mocnego pod względem predykcji modelu do rozpoznawania zapalenia płuc na podstawie zdjęć RTG. Ale zacznijmy od początku i zobaczmy, w czym problem…

Czym jest zapalenie płuc?
Zapalenie płuc to choroba dolnej części układu oddechowego. W większości wypadków wywoływana jest przez bakterie (chociaż patrząc na to co się dzieje ostatnio na świecie mam wrażenie, że w dzisiejszych czasach wywołuje ją tylko koronawirus).
Objawy zapalenia płuc są tak charakterystyczne, że opisał je już „ojciec medycyny”, czyli Hipokrates. Pomimo długiej historii, aż do XX wieku większość osób chorująca umierała. Zmieniły to dopiero prace dwóch wybitnych naukowców – Ludwika Pasteura i Aleksandra Fleminga.
W 1880 Pasteurowi udało się wyhodować jedną z bakterii powodujących zapalenie płuc. Było to dużym sukcesem, ale niestety nie wystarczyło do wynalezienia skutecznej metody leczenia.
Do poprawy sytuacji doprowadził Aleksander Fleming i odkrycie przez niego antybiotyków! Umożliwiło to skuteczne leczenie chorób bakteryjnych, w tym także zapalenia płuc.

Zapalenie płuc to stan zapalny płuc obejmujący głównie małe worki powietrzne zwane pęcherzykami płucnymi. Objawy zazwyczaj obejmują kombinację produktywnego lub suchego kaszlu, bólu w klatce piersiowej, gorączki i trudności w oddychaniu. Nasilenie stanu chorobowego jest zmienne.
Chorobę można sklasyfikować według miejsca, gdzie doszło do zakażenia, np. zapalenie płuc nabyte w środowisku, szpital lub związane z opieką zdrowotną.
Rozpoznanie zapalenia płuc
Do postawienia diagnozy lekarzowi potrzebny jest dokładny wywiad, badanie pacjenta oraz zdjęcie RTG klatki piersiowej. Na zapalenie płuc w badaniu fizykalnym wskazują słyszalne trzeszczenia i rzężenia w płucach, a w badaniu rentgenowskim:
- zacienienia w obrębie płata płuca – w zależności od zaawansowania choroby może obejmować całe płuco, płat lub kawałek,
- plamiste cienie mające tendencje do zlewania się,
- w przypadku wirusowego zapalenia płuc szukamy obrazu mlecznej szyby.
I to jest dla nas bardzo istotna informacja!
Zajmiemy się właśnie rozpoznawaniem zapalenia płuc na podstawie zdjęcia rentgenowskiego.
No to do dzieła!

Zbiór danych
W internecie można znaleźć kilka różnych zbiorów danych ze zdjęciami RTG z zapaleniem płuc. Ja wykorzystałem dane z konkursu na Kaggle Chest X-Ray. Dane możesz pobrać bezpośrednio z Kaggle (około 1.15 GB).
Dodatkowo możesz też od razu wykorzystać platformę i dostępne na niej GPU do przeliczenia własnych modeli 🤪. Ja tak właśnie zrobiłem. Zanim zabierzemy się za sieci konwolucyjne, to należy najpierw przyjrzeć się danym i je przygotować.
Wczytanie danych
Zacznijmy od wczytania podstawowych bilbiotek
import numpy as np
import pandas as pd
import glob
i pobierzmy dane zgodnie ze strukturą, w jakiej zostały przygotowane w konkursie. Zdjęcia są w katalogach nazwanych próbką (train / test / val) i osobno w podkatalogach nazwanych flagą: czy zdjęcie było zaklasyfikowane przez radiologa jako pracjent zdrowy („NORMAL”) czy chory („PNEUMONIA”).
#path = './data/'
path = '/kaggle/input/chest-xray-pneumonia/chest_xray/'
# define paths
train_norm_dir = path + 'train/NORMAL/'
train_pneu_dir = path + 'train/PNEUMONIA/'
test_norm_dir = path + 'test/NORMAL/'
test_pneu_dir = path + 'test/PNEUMONIA/'
val_norm_dir = path + 'val/NORMAL/'
val_pneu_dir = path + 'val/PNEUMONIA/'
# find all files, our files has extension jpeg
train_norm = glob.glob(train_norm_dir + '*jpeg')
train_pneu = glob.glob(train_pneu_dir + '*jpeg')
test_norm = glob.glob(test_norm_dir + '*jpeg')
test_pneu = glob.glob(test_pneu_dir + '*jpeg')
val_norm = glob.glob(val_norm_dir + '*jpeg')
val_pneu = glob.glob(val_pneu_dir + '*jpeg')
Sprawdźmy liczności:
for files_list in [train_norm, train_pneu, test_norm, test_pneu, val_norm, val_pneu]:
files_list = [x.replace('\\', '/') for x in files_list]
print(f'train: healthy({len(train_norm)}), pneumonia({len(train_pneu)}).\
Healthy as % of total: {100*round(len(train_norm)/(len(train_norm+train_pneu)),2)}%')
print(f'test: healthy({len(test_norm)}), pneumonia({len(test_pneu)}). \
Healthy as % of total: {100*round(len(test_norm)/(len(test_norm+test_pneu)),2)}%')
print(f'val: healthy({len(val_norm)}), pneumonia({len(val_pneu)}). \
Healthy as % of total: {100*round(len(val_norm)/(len(val_norm+val_pneu)),2)}%')

Hmm…

Drobna poprawka zbiorów
Mam nadzieję, że znalazłeś chwilkę, aby przyjrzeć się powyższym wynikom. Jak dla mnie mając zbiór, gdzie dane:
- treningowe wynoszą ponad 5.000 zdjęć,
- do testowania (dokręcania) modelu wynoszą ponad 600,
- a zbiór walidacyjny wynosi 16, to…
… jakiś prima aprilisowy żart :). W przypadku posiadania takiej próbki bałbym się wnioskować o mocy modelu na postawie tylko 16 obserwacji.
Dodatkowo spójrz na stosunek zdjęć oznaczonych jako osoby zdrowe i chore. W każdym zbiorze jest inny.

Dlatego zdecydowałem się, by połączyć te wszystkie 3 zbiory w jeden i wylosować na nowo zbiór train, test i val. Dzięki temu będę miał pewność, że zbiory nie różnią się zbytnio od siebie. Stwórzmy zatem listę z linkami do zdjęć osób zdrowych i osobno chorych:
list_total = []
for x in train_norm + test_norm + val_norm:
list_total.append([x, 0])
for x in train_pneu + test_pneu+ val_pneu:
list_total.append([x, 1])
Ah… warto jeszcze zapewnić w wyborze próbki losowość danych. Więc dodajmy ją:
df_total = pd.DataFrame(list_total, columns=['image', 'label'])
df_total = df_total.sample(frac=1)
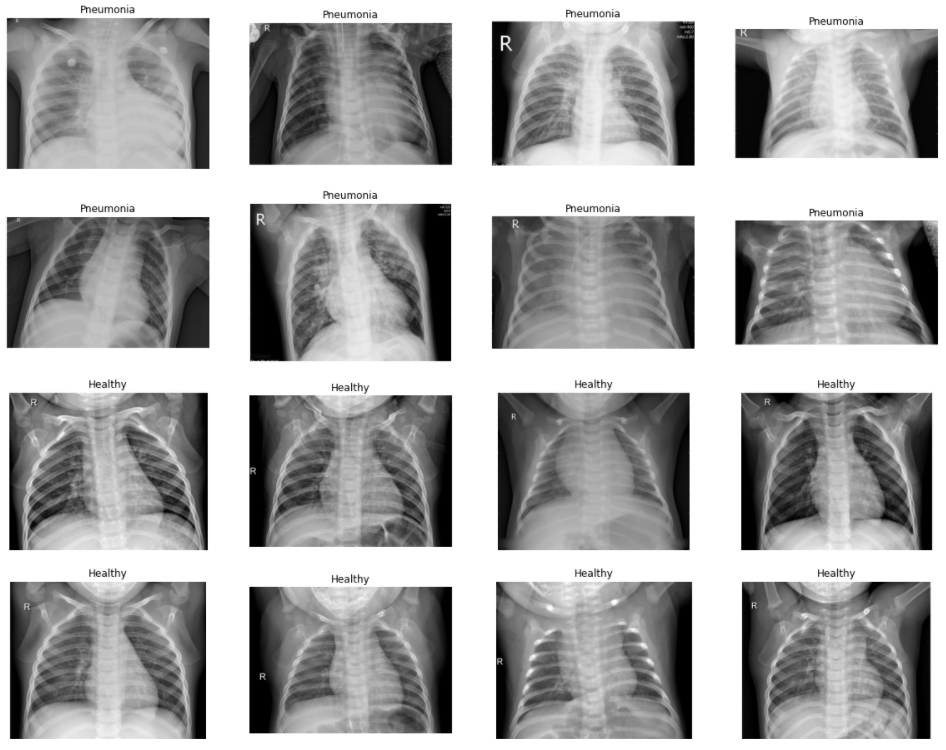
Przyjrzyjmy się jeszcze zdjęciom:
import matplotlib.pyplot as plt
plt.figure(figsize=(20,16))
for i,img_path in enumerate(df_total[df_total['label'] == 1][0:8]['image']):
plt.subplot(4,4,i+1)
plt.axis('off')
img = plt.imread(img_path)
plt.imshow(img, cmap='gray')
plt.title('Pneumonia')
for i,img_path in enumerate(df_total[df_total['label'] == 0][0:8]['image']):
plt.subplot(4,4,8+i+1)
plt.axis('off')
img = plt.imread(img_path)
plt.imshow(img, cmap='gray')
plt.title('Healthy')
Sieci konwolucyjne – przygotowanie danych!
Dobra, mamy załadowany zbiór do pamięci. Teraz należy przygotować odpowiednio dane, by można było dla nich przeliczyć sieci konwolucyjne CNN. Należy zrobić dwie rzeczy:
- zapisać dane w zrozumiały dla algorytmu sposób – w naszym przypadku zapiszę dane do tablicy array.
- przygotować preprocessing dla naszych zdjęć.
W pierwszym kroku warto zadbać o to, by zdjęcia wejściowe miały taki sam rozmiar. Dlatego przeskalujemy wszystkie zdjęcia do wielkości 256×256. Dlaczego tyle? Tyle wyszło mi podczas eksperymentowania. Testując różne sieci konwolucyjne zauważyłem, że dla takiej wielkości uzyskałem optymalny dla mnie czas pomiędzy wynikami a czasem trenowania.
Kolejna rzecz, to przekonwertowanie zdjęć na skalę szarości, aby był jeden kanał. W tym przypadku głębia kolorów nie ma aż takiego znaczenia. Następnie przeskalujemy jeszcze wartości z przedziału [0, 255], aby były w przedziale [0, 1]. Dzięki temu sieci konwolucyjne będą się szybciej uczyć.
Ostatnim krokiem jest zmiana macierzy 256 x 256 poprzez dodanie kolejnego wymiaru jako kanału. W związku, że jest on szary to zmieniamy na 256 x 256 x 1.
Tutaj całość (heh, więcej opisywania niż kodu 🤫):
import cv2
import numpy as np
def process_data(img_path):
img = cv2.imread(img_path)
img = cv2.resize(img, (256, 256))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = img/255.0
img = np.reshape(img, (256,256,1))
return img
def compose_dataset(df):
data = []
labels = []
for img_path, label in df.values:
data.append(process_data(img_path))
labels.append(label)
return np.array(data), np.array(labels)
X_total, y_total = compose_dataset(df_total)
print('Total data shape: {}, Labels shape: {}'.format(X_total.shape, y_total.shape))

Train vs test vs valid
Super. Teraz na nowo wylosujmy zbiory:
- Train: zbiór, na którym nasz model się będzie uczył.
- Test: próbka do wstępnego testowania modelu. Jeśli nie trenujesz modelu cross-walidacją, to możesz go wykorzystać do dokręcania modelu, np. optymalizacji hiperparametrów albo wstępnego zatrzymania (early stopping).
- Val: zbiór walidacyjny do ostatecznego porównania modeli. Pamiętaj, że ten zbiór losujesz i chowasz do szuflady!

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_total, y_total, test_size=0.3, random_state=2021)
X_val, X_test, y_val, y_test = train_test_split(X_test, y_test, test_size=0.5, random_state=2021)
print('Train data shape: {}, Labels shape: {}'.format(X_train.shape, y_train.shape))
print('Test data shape: {}, Labels shape: {}'.format(X_test.shape, y_test.shape))
print('Valid data shape: {}, Labels shape: {}'.format(X_val.shape, y_val.shape))

Wygląda znacznie lepiej niż poprzednio.
Potwierdźmy sobie jeszcze to wizualnie, bo nie oszukujmy się – łatwiej nam ludziom patrzeć na wykresy niż same cyfry.
plt.figure(figsize=(20,4))
plt.subplot(1,3,1)
pd.DataFrame(y_train)[0].value_counts().plot(kind='bar', color=['crimson','gray'])
plt.title(f'Train data - {100*round(sum(y_train)/len(y_train),3)}%')
plt.subplot(1,3,2)
pd.DataFrame(y_test)[0].value_counts().plot(kind='bar', color=['crimson','gray'])
plt.title(f'Test data - {100*round(sum(y_test)/len(y_test),3)}%')
plt.subplot(1,3,3)
pd.DataFrame(y_val)[0].value_counts().plot(kind='bar', color=['crimson','gray'])
plt.title(f'Validation data - {100*round(sum(y_val)/len(y_val),3)}%')
plt.show()

Przy metryce np. accurency łatwiej wnioskuje się, jeżeli zbiory są równoliczne. Przygotujmy wobec tego jeszcze zbalansowany zbiór walidacyjny. Jak? Najprościej jak się da. Z wykresu powyżej widać, że mniej jest danych o klasie „heatlhy”. Zatem weźmy wszystkie dane i dolosujmy tyle samo danych z drugiej klasy.
df_val_tmp = pd.DataFrame(y_val, columns=['target'])
index_goods = list(df_val_tmp[df_val_tmp['target']==0].index)
index_bads = list(df_val_tmp[df_val_tmp['target']==1].sample(len(index_goods)).index)
X_val_bal = X_val[index_goods + index_bads]
y_val_bal = y_val[index_goods + index_bads]
plt.figure(figsize=(10,4))
pd.DataFrame(y_val_bal)[0].value_counts().plot(kind='bar', color=['crimson','gray'])
plt.title(f'Validation balanced data - {100*round(sum(y_val_bal)/len(y_val_bal),3)}%')
plt.show()

Przekonwertuję jeszcze naszą zmienną docelową z binarnej na kategotryczną
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_val = to_categorical(y_val)
y_val_bal = to_categorical(y_val_bal)
i możemy przystąpić do modelowania!

Pierwszy model – sieci konwolucyjne
W poprzednim wpisie wyjaśniłem podstawy architektury sieci kownolucyjnych CNN, więc już do nich nie będę wracał.
W pierwszym kroku na podstawie kilkunastu eksperymentów dobrałem poniższą architekturę. Na pewno nie jest optymalna i możesz zrobić lepszą. Niemniej jednak daje moim zdaniem naprawdę satysfakcjonujące wyniki w rozsądnym czasie (podczas trenowania wykorzystującym GPU).
Wykorzystałem w niej dobre praktyki z najbardziej znanych architektur sieci CNN:
- podwójne warstwy konwolucyjne, a potem zmniejszenie (CNN+CNN+pooling),
- w kolejnych CNN zwiększam liczbę filtrów *2.
A oto model w wersji 1.0 😊
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
tf.__version__

model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu', input_shape=(256, 256, 1)))
model1.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu'))
model1.add(MaxPooling2D(pool_size=(2,2)))
model1.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model1.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model1.add(MaxPooling2D(pool_size=(2,2)))
model1.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model1.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model1.add(MaxPooling2D(pool_size=(2,2)))
model1.add(Flatten())
model1.add(Dense(128, activation='relu'))
model1.add(Dropout(0.33))
model1.add(Dense(2, activation='softmax'))
model1.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
callback = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1)
model1.summary()

Dodatkowo możesz zobaczyć, że ustawiłem w kodzie walidowanie wyniku na zbiorze testowym na wartości „val_loss” z parametrem „patience” równym 3. Zatem jak na zbiorze testowym parametr będzie spadał przez 3 epoki, to trening modelu się zatrzyma.
To trenujmy sieci konwolucyjne 🤩
history1 = model1.fit(X_train,y_train,
validation_data=(X_test, y_test),
epochs = 100,
verbose = 1,
callbacks=[callback])

Model zatrzymał się po 13 epokach. Zwizualizujmy sobie jeszcze jak wyglądał trening:
import seaborn as sns
def train_summary(history):
plt.figure(figsize=(20,5))
# plot loss & val loss
plt.subplot(1,2,1)
sns.lineplot(x=history.epoch, y=history.history['loss'], color='red', label='Train Loss')
sns.lineplot(x=history.epoch, y=history.history['val_loss'], color='orange', label='Test Loss')
plt.title('Loss on train vs test')
plt.legend(loc='best')
# plot accuracy and val accuracy
plt.subplot(1,2,2)
sns.lineplot(x=history.epoch, y=history.history['accuracy'], color='blue', label='Train Accuracy')
sns.lineplot(x=history.epoch, y=history.history['val_accuracy'], color='green', label='Test Accuracy')
plt.title('Accuracy on train vs test')
plt.legend(loc='best')
plt.show()

Patrząc na wykres „loss” można stwierdzić, że od epoki 3 model niewiele zyskał. Natomiast patrząc na metrykę accurancy jeszcze dokręciliśmy z 1 punkt procentowy od epoki 3.
Przyjrzyjmy się ostatecznym wynikom na zbiorze walidacyjnym, którego model jeszcze nie widział!
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import accuracy_score, recall_score, f1_score, \
roc_auc_score, precision_score
def model_summary(model, X, y):
y_pred = model.predict(X, batch_size=4)
y_pred = np.argmax(y_pred, axis=1)
y = np.argmax(y, axis=1)
print(f'accurency: {accuracy_score(y, y_pred)}')
print(f'recall: {recall_score(y, y_pred)}')
print(f'precision: {precision_score(y, y_pred)}')
print(f'f1: {f1_score(y, y_pred)}')
print(f'roc_auc: {roc_auc_score(y, y_pred)}')
cf_matrix = confusion_matrix(y, y_pred)
group_names = ['True Neg','False Pos','False Neg','True Pos']
group_counts = ["{0:0.0f}".format(value) for value in cf_matrix.flatten()]
group_percentages = ["{0:.2%}".format(value) for value in cf_matrix.flatten()/np.sum(cf_matrix)]
labels = [f"{v1}\n{v2}\n{v3}" for v1, v2, v3 in
zip(group_names,group_counts,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns.heatmap(cf_matrix, annot=labels, fmt='', cmap='Blues')
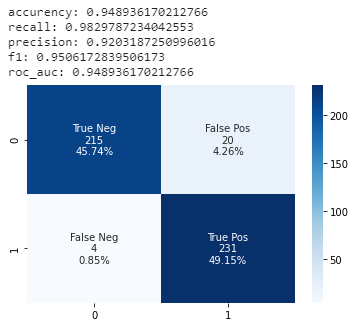
model_summary(model1, X_val, y_val)

No…zacnie! Poziom metryk zbliżony do zbioru testowego. Śmiało można powiedzieć, że modelu nie przetrenowaliśmy i wyniki są satysfakcjonujące. Nawet obawiam się, że może ciężko być nam przebić w kolejnych krokach ten model!
Dodatkowo widać, że mylimy się dla jedynie niecałych 4% przypadków. W całym zbiorze model popełnił błąd tylko dla 33 zdjęć!

A zobaczmy jak to wygląda na zbiorze zbalansowanym (50% goods / 50% bads).
model_summary(model1, X_val_bal, y_val_bal)
Ok, poziom accurency 95%, czyli można śmiało powiedzieć, że mylimy się tylko w 5 przypadkach na 100. A jakbyś się zastanawiał, dlaczego liczba „zdrowych” jest taka sama, to przypomnij sobie jak przygotowaliśmy ten zbiór – do wszystkich zdrowych dolosowaliśmy tę samą liczbę chorych 😉. No moje kochane sieci konwolucyjne – naprawdę możecie zmieniać świat!
Drugi model – data augmentation!
Spróbujmy coś jeszcze poprawić. Zakładam, ze architekturą się już wystarczająco pobawiłem i poeksperymentowałem, więc dalej tego tematu nie będę ruszał. Skoro nie archiktektura to co?
To dane! Ok, ale co można z nimi zrobić? Odrobinę je zmodyfikować!
Co to data augmentation (rozszerzenie danych)?
Dokładność modeli w uczeniu nadzorowanym zależy w dużej mierze od ilości i różnorodności danych dostępnych podczas szkolenia. Zatem w teorii im więcej danych tym lepiej. I wyjątkowo tutaj teoria zgadza się z praktyką!
Tylko jak rozmnożyć dane mając pierwotny zbiór? Na ratunek przychodzi nam „data augmentation„. To technika, która polega na zastosowaniu różnych przekształceń dostępnych danych w celu syntezy nowych danych.

Czyli mając zdjęcie (tak jak w naszym przypadku) możesz je:
- odrobinę przesunąć w prawo lub lewo,
- troszeczkę obrócić wokół własnej osi w obie strony,
- odwrócić jak w lustrze lub do góry nogami,
- zwęzić lub rozszerzyć,
- dodać szum (np. krople deszczu),
- rozmazać,
- itp. itd.
Zatem jak widzisz można naprawdę na mnóstwo sposobów rozmnożyć obraz.
Uwaga! Pamiętaj, że nie dotyczy to tylko zdjęć. Na przykład z dźwiękiem czy tekstem też można robić podobne rzeczy! A jeśli chciałbyś abym rozwinął ten temat w osobnym poście, to zostaw komentarz!
ImageDataGenerator w Keras!
Aktualnie bardzo prosto możemy wykorzystać data augmentation. W naszym przykładzie wykorzystamy wbudowaną funkcję z tensorflow zwaną ImageDataGenerator.
Możemy w bardzo prosty sposób zdefiniować w niej odpowiednie przekształcenia.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# define generator
datagen = ImageDataGenerator(
rotation_range=10,
zoom_range = 0.1,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=False,
vertical_flip=False
)
# fit generator on our train features
datagen.fit(X_train)
Powyżej widzicie, że zastosowałem niewielkie (do 10%) przekształcenia: rotacja, przyliżenie, przesunięcie w górę i w dół. Nie zrobiłem odwrócenia jak w lustrze, bo serce zawsze na zdjęciach po prawej stronie i mogłoby to zaburzyć znacznie mocniej dane treningowe.

No to trenujmy sieci konwolucyjne 🙂
Mamy zdefiniowane przekształcenie, to teraz zbudujmy model. Zrobimy we wcześniejszej architekturze jedynie jedną drobną modyfikację. Zamiast trenując na pierwotnym zbiorze przygotujmy trening na zbiorze przepuszczonym przez drobne przekształcenie pierwotne obrazu zdefiniowane krok wcześniej.
model2 = Sequential()
model2.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu', input_shape=(256, 256, 1)))
model2.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu'))
model2.add(MaxPooling2D(pool_size=(2,2)))
model2.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model2.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model2.add(MaxPooling2D(pool_size=(2,2)))
model2.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model2.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model2.add(MaxPooling2D(pool_size=(2,2)))
model2.add(Flatten())
model2.add(Dense(128, activation='relu'))
model2.add(Dropout(0.33))
model2.add(Dense(2, activation='softmax'))
model2.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
history2 = model2.fit(datagen.flow(X_train,y_train, batch_size=64),
validation_data=(X_test, y_test),
epochs = 100,
verbose = 1,
callbacks=[callback])
train_summary(history2)

model_summary(model2, X_val_bal, y_val_bal)

Hmm… większość powyższych metryk jest zbliżona do pierwszego modelu. Natomiast jestem przekonany, że model jest odrobinę bardziej czuły na dane wejściowe, np. gdyby zdjęcie zostało zeskanowane i odrobinkę odwrócone itp. Spróbujmy jeszcze wykorzystać naszą funkcję do drobnych losowych modyfikacji danych w inny sposób.
Trzeci model – podwajamy dane do treningu!
Warto zwrócić uwagę, że w drugim modelu, mimo dodania losowości do zdjęcia, mieliśmy taką samą próbkę pod względem liczności. Natomiast skoro na naszą próbkę treningową nakładamy losową modyfikację, to możemy bez problemu zbiór treningowy zwiększyć dwu, trzy lub wielokrotnie!
Zobaczmy, co się wówczas stanie w naszym przypadku:
model3 = Sequential()
model3.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu', input_shape=(256, 256, 1)))
model3.add(Conv2D(filters=32, kernel_size=(7,7), padding='same', activation='relu'))
model3.add(MaxPooling2D(pool_size=(2,2)))
model3.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model3.add(Conv2D(filters=64, kernel_size=(5,5), padding='same', activation='relu'))
model3.add(MaxPooling2D(pool_size=(2,2)))
model3.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model3.add(Conv2D(filters=128, kernel_size=(3,3), padding='same', activation='relu'))
model3.add(MaxPooling2D(pool_size=(2,2)))
model3.add(Flatten())
model3.add(Dense(128, activation='relu'))
model3.add(Dropout(0.33))
model3.add(Dense(2, activation='softmax'))
model3.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
history3 = model3.fit(datagen.flow(np.concatenate((X_train, X_train), axis=0),
np.concatenate((y_train, y_train), axis=0),
batch_size=64),
validation_data=(X_test, y_test),
epochs = 100,
verbose = 1,
callbacks=[callback])
train_summary(history3)

model_summary(model3, X_val_bal, y_val_bal)

Model jeszcze troszkę się poprawił! Super, bo widać, że zwiększenie próbki pomogło w tym przypadku. Choć przy tak niewielkim poziomie błędu, jaki osiągnęliśmy dla tego modelu wydaje mi się, że to równie dobrze mogło być spowodowane wylosowaniem lepszych wag przy inicjalizacji sieci konwolucyjnej.
False Negative vs False Positive – rozmyślania!
Przypomnę, że nie jestem lekarzem i nie jestem pewien czy to, co teraz zrobię ma uzasadnienie medyczne. Stawiam się w sytuacji pacjenta. Załóżmy, że znalazłem się w tej pechowej grupce, gdzie model się pomylił. To, w której grupie wolałbym być?
Ja osobiście chciałbym trafić do False Positive. Dlaczego?
Fałszywie pozytywny to pozytywny wynik testu, który powinien być negatywny. Czasami nazywa się to „fałszywym alarmem” lub „fałszywie dodatnim błędem”. Najbardziej obrazuje to wynik pozytywny testu ciążowego, jeśli w rzeczywistości nie jesteś w ciąży. W naszym przypadku wolałbym zostać zakwalifikowany jako chory i zacząć leczenie, niż pozostawionym samemu sobie. Po lekturze informacji o zapaleniu płuc wiem, że samo za bardzo nie przejdzie.
Hint. Jak czegoś nie wiesz to potwierdź z kimś, kto ma większą wiedzę. Ja potwierdziłem z ratownikiem medycznym Karolem Bączkowskim (dzięki za konsultacje!), że jeśli tylko nas stać, to lepiej skierować pacjenta na leczenie, niż go nie leczyć.
Co zatem możemy zrobić w modelu? Pożonglować wagami klas!
Teraz moim celem jest spowodowanie, by model w przypadku błędów przypisywał mniejszą „karę” w przypadku zaklasyfikowania zdjęcia jako zdrowy, a nie chory. Po prostu zmodyfikujmy wagę klas, by flaga chory była powiedźmy 4 razy większa. To spowoduje, że model będzie „zwracał większą uwagę” na przykłady z klasy zdjęć z chorobą. Najczęściej tego parametru używa się przy zbiorach niezbalansowanych, a my w ramach eksperymentu użyjmy go do podkręcenia False Positivów.
history4 = model4.fit(datagen.flow(np.concatenate((X_train, X_train), axis=0),
np.concatenate((y_train, y_train), axis=0),
batch_size=64),
validation_data=(X_test, y_test),
epochs = 100,
verbose = 1,
callbacks=[callback],
class_weight={0:1.0, 1:4.0}
)
model_summary(model4 X_val_bal, y_val_bal)

Hura! Zadziałało tak jak oczekiwałem! Model stracił troszkę na mocy, czyli rozpoznaje mniej przypadków prawidłowo niż wcześniej. Jednak zyskał nową funkcjonalność – w przypadku wątpliwości przypisuje taką klasę, aby pacjentów na wszelki wypadek leczyć.

Podsumowanie
Mam nadzieję, że widzisz w jak prosty sposób można osiągnąć fajne wyniki dla zadań związanych ze zdjęciami i będziesz częściej sięgać po sieci konwolucyjne CNN! Nie są takie straszne, a mogą pomóc nam zmieniać świat na lepsze :). Natomiast pamiętaj, by w przypadku wdrażania modeli na produkcję przetestować jego działanie (w tym artykule tego nie robiłem) i skonsultować wyniki z ekspertami!
Pozdrawiam z całego serducha!




Bardzo fajny poradnik!
Próbowałam odtworzyć wyniki jednakże pojawia mi się błąd, i niestety nie wiem jak go naprawić
df_val_tmp = pd.DataFrame(y_val, columns=[’target’])
index_goods = list(df_val_tmp[df_val_tmp[’target’]==0].index)
index_bads = list(df_val_tmp[df_val_tmp[’target’]==1].sample(len(index_goods)).index)
X_val_bal = X_val[index_goods + index_bads]
y_val_bal = y_val[index_goods + index_bads]
plt.figure(figsize=(10,4))
pd.DataFrame(y_val_bal)[0].value_counts().plot(kind=’bar’, color=[’crimson’,’gray’])
plt.title(f’Validation balanced data – {100*round(sum(y_val_bal)/len(y_val_bal),3)}%’)
plt.show()
TypeError Traceback (most recent call last)
in ()
5
6 X_val_bal = X_val[index_goods + index_bads]
—-> 7 y_val_bal = y_val[index_goods + index_bads]
8
9 plt.figure(figsize=(10,4))
TypeError: list indices must be integers or slices, not list
Genialne są te tutoriale związane z sieciami neuronowymi. Dzięki nim udało mi się przeskoczyć na wyższy poziom zrozumienia, jak to działa. Czytanie tutoriali obcojęzycznych jest pomocne, ale mimo wszystko jak się przeczyta to po polsku, aby załapać na poziomie bazowym o co to chodzi to robi różnicę. I to mimo tego, że znam angielski na poziomie zaawansowanym, to ojczysty język zawsze robi różnicę. Z niecierpliwością czekam na kolejne artykuł o sieciach neuronowych!
Pozdrawiam
Hej Wojtek!
Miło mi to słyszeć. Za jakiś czas planuję popisać więcej o sieciach związanych z NLP 🙂
Choć przyznam, że o wiele częściej wykorzystuję w pracy lasy / boostingi, stąd jest ich więcej na blogu.
Pozdrawiam serdecznie,
Mirek
Hej! Mam problem z tym kodem i nie wiem czemu …
Jużz przy liczebności :
„ZeroDivisionError Traceback (most recent call last)
in ()
2 files_list = [x.replace(’\\’, '/’) for x in files_list]
3
—-> 4 print(f’train: healthy({len(train_norm)}), pneumonia({len(train_pneu)}).Healthy as % of total: {100*round(len(train_norm)/(len(train_norm+train_pneu)),2)}%’)
5 print(f’test: healthy({len(test_norm)}), pneumonia({len(test_pneu)}). Healthy as % of total: {100*round(len(test_norm)/(len(test_norm+test_pneu)),2)}%’)
6 print(f’val: healthy({len(val_norm)}), pneumonia({len(val_pneu)}). Healthy as % of total: {100*round(len(val_norm)/(len(val_norm+val_pneu)),2)}%’)
ZeroDivisionError: division by zero”
Błąd sugeruje, że masz dzielenie przez zero:)
Wyświetl sobie samą wartość „len(train_norm+train_pneu)”. Zakładam, że po prostu tutaj masz tą liczbę równą 0 stąd taki komunikat błędu.
Zgrabnie zrobiony tutorial. Gratuluję! Może warto też przygotować i zamieścić link do ready-to-use pliku Jupyter-owego?
Dzięki za informacje i pomysł!
Pomyślę o tym by dorzucać również notebooki do nowszych artykułów.
Albo stworzę repozytorium na GIT 🙂
Możliwość komentowania została wyłączona.