
– Tato? Co robisz? – spytała Jagódka
– Staram się nauczyć model rozpoznawania stron internetowych.
– A jak to działa?
– Hmmmm… a co widzisz na tym obrazku?
– No kotka.
– A dlaczego według Ciebie Kochanie to jest kotek?
– Bo ma takie trójkątne uszka. No i ma wąsy.
– I ogon! – krzyknęła Oti na koniec przysłuchując się naszej rozmowie.
– No właśnie. I modele też uczą się rozpoznawać proste rzeczy takie jak trójkąty, cienkie kreseczki jak wąsy czy grube kreski jak ogon. W ten sposób mogą się nauczyć co czym jest.
Już wiesz jak działają proste sieci neuronowe MLP zwane perceptronem wielowarstwowym. Jeśli nie pamiętasz, to zapraszam TUTAJ. W tamtym artykule pokazałem jak można je wykorzystać do rozpoznania rodzaju ubrania ze zbioru Fashion Mnist. Jednak mówiąc szczerze, tamta architektura rozwiązania z mojego artykułu nie była najlepsza. Konwolucyjne sieci neuronowe, w skrócie CNN (ang. Convolutional Neural Network), doskonale radzą sobie z rozwiązaniem problemów związanych z obrazem (i nie tylko)!
Jednak najpierw zadajmy sobie na jedno ważne pytanie…

Co jest nie tak z najprostszą siecią MLP przy rozpoznawaniu obrazów?
Pamiętasz z poprzedniego artykułu jak wyglądało przykładowe ubranie z zbioru Fashion Mnist? Był to obraz 28×28 pikseli w odcieniu szarości:

Pamiętacie co zrobiłem, by nauczyć prostą sieć MLP? Zmieniłem wektor 28×28 na 1×784, a następnie wytrenowałem na niej proste warstwy gęste (dense).
Natomiast w dzisiejszym świecie średniej jakości aparat cyfrowy robi zdjęcia o rozdzielczości 1900 x 1600, co daje ponad 3 miliony wartości! A jeśli zbudowałbym prostą sieć z dwiema warstwami gęstymi po 512, to wówczas mówimy już o setkach miliardów parametrów do wytrenowania…
Zatem nawet zmniejszając liczbę neuronów w kolejnych warstwach, to trenując taką sieć będziemy wymagali dużej mocy obliczeniowej do przeliczenia takiej liczby parametrów – a to wpływa na czas i koszty. No i jak wiadomo, czas to pieniądz.
Drugim problemem (moim zdaniem poważniejszym) jest utrata informacji. To, co robimy w przypadku prostych sieci gęstych, to konieczność przekazania pojedynczego wektora. Zatem zmieniając kształt naszego zdjęcia na jeden długi wektor, tracimy informację o kształcie tego buta. Po prostu gubimy informacje będącą w sąsiednich pikselach. Pomyśl o innej drobnej modyfikacji. Gdybyśmy przesunęli but o 3 piksele do góry, to patrząc na obrazek byłoby to samo. Jednak z punktu widzenia jednego wektora 1×784 będzie to całkiem inny zapis. Skoro tyle jest problemów z siecią MLP, to domyślasz się, że ktoś już wpadł na lepsze rozwiązanie.
Konwolucyjne sieci neuronowe – historia
I tak na ratunek przychodzą nam konwolucyjne sieci neuronowe (inaczej zwane splotowe). Nazwa wzięła się z tego, że głównym elementem tych sieci jest warstwa wykorzystująca operację zwaną konwolucją (lub splotem) – o tym za chwilkę.
Lata 60′
Wszystko zaczęło się od pracy Hubela i Wiesela, którzy eksperymentowali w latach pięćdziesiątych i sześćdziesiątych XX wieku. Podłączyli oni mikroelektrody do mózgu kota i pokazywali zwierzęciu obrazki. Był to podłużny prostokąt, który obracał się wokół własnej osi. Badacze przypadkiem zauważyli, że na każdy obrazek reagowała tylko wybrana grupa neuronów! Czyli jeśli była to kreska ukośna to aktywowała się jedna grupa neuronów, a jak pionowa to inna.
Odkryli w ten sposób dwa typy komórek w pierwotnej korze wzrokowej zwane komórkami prostymi i komórkami złożonymi. Zaproponowali też kaskadowy model tych dwóch typów komórek do wykorzystania w rozpoznawaniu wzorców.

Lata 80′
W latach 80′ Kunihiko Fukushima inspirowany pracami Hubela i Wiesela pokazał światu „neokognitron„. Była to hierarchiczna, wielowarstwowa sztuczna sieć neuronowa używana do rozpoznawania znaków pisanych odręcznie w języku japońskim i innych zadań związanych z rozpoznawaniem wzorców. Wprowadził on dwa podstawowe typy warstw w sieciach CNN:
- warstwy splotowe
- i warstwy próbkowania (downsampling layers).
Natomiast pod koniec lat 80′ Yann LeCun w 1989 wykorzystał propagację wsteczną, aby modyfikować współczynniki jądra splotu. Zrobił to dla zbioru obrazków z ręcznie zapisanymi cyframi obrazów (MNIST). I to był przełomowy moment. Uczenie się sieci stało się w pełni automatyczne, działało lepiej niż ręczne projektowanie współczynników i było dostosowane do szerszego zakresu problemów z rozpoznawaniem obrazu i typów obrazów. Takie podejście stało się podstawą nowoczesnej wizji komputerowej.
2012 🙂
Jednak wówczas jeszcze komputery nie nadążały za człowiekiem. Prawdziwy rozkwit sieci CNN nastąpił w 2012 roku, kiedy to zespół Alex Krizhevsky wygrał w konkursie ImageNet w rozpoznawaniu obrazów o kilka długości w porównaniu z innymi drużynami. To tak jakby wszyscy na olimpiadzie w sprincie na 100 metrów biegli około 10 sekund i nagle pojawił się ktoś, kto potrafi ten dystans przebiec w 8.
Od tego czasu w modelowaniu obrazów głównie wykorzystuje się konwolucyjne sieci neuronowe.
Czym jest konwolucja?
Formalnie zdefiniowana matematyczna operacja splotu (czy konwolucji) jest dość zawiła i wykorzystuje całki. Pomyślmy jednak o niej troszkę inaczej i w prostszy sposób. Bardziej obrazowo operacja konwolucji jest przekształceniem macierzowym fragmentów zdjęcia, które ma na celu wydobycie informacji o konkretnych cechach obrazu. Dalej brzmi skomplikowanie? Spokojnie. Jest to wykorzystywane od wielu lat, tylko nie było wcześniej tak nazywane.
Pomyśl o prostym elemencie jak negatyw. Jest to po prostu przemnożenie zdjęcia przez macierz -1, aby odwrócić kolory.

Filtry, czyli kernele
W sieciach konwolucyjnych taką macierz, o której pisałem wyżej, nazywamy filtrem bądź kernelem. W pierwszej kolejności spróbujmy na własnych zdjęciach poczuć jak samemu można dobierać filtry, by wyciągnąć dzięki nim pewną informację.
Wczytajmy sobie swoje zdjęcie:
import numpy as np
import matplotlib.pyplot as plt
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
input_image = plt.imread('./m.png')
print(f'Input shape: {input_image.shape}')
a następnie jeszcze je zamienię w odcień szarości i zmniejszę o co drugi piksel:
gray_image = rgb2gray(input_image)
small_image = gray_image[::2,::2]
Tutaj jest prosta funkcja, gdzie możesz dla zabawy podać różne macierze i zobaczyć jakie filtry dopasowuje:
from scipy.signal import convolve2d
def apply_kernel_to_image(img, kernel, title=''):
feature = convolve2d(img, kernel, boundary='symm', mode='same')
# Plot
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(1, 2, 1)
ax1.imshow(img, 'gray')
ax1.set_title('Input image', fontsize=15)
ax1.set_xticks([])
ax1.set_yticks([])
ax2 = fig.add_subplot(1, 2, 2)
ax2.imshow(feature, 'gray')
ax2.set_title(f'Feature map - {title}', fontsize=15)
ax2.set_xticks([])
ax2.set_yticks([])
plt.show()
To zerknijmy kilka przykładowych macierzy (możesz poszukać różnych w internecie lub samemu dobrać):
#outline
kernel = np.array([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
apply_kernel_to_image(gray_image, kernel, 'outline')

#left sobel
kernel = np.array([
[1, 0, -1],
[2, 0, -2],
[1, 0, -1]])
apply_kernel_to_image(small_image, kernel, 'left sobel')

#blur
kernel = np.array([
[0.01, 0.01, 0.01],
[0.01, 0.01, 0.01],
[0.01, 0.01, 0.01]])
apply_kernel_to_image(small_image, kernel, 'blur')

#negative
kernel = np.array([
[-1, -1, -1],
[-1, -1, -1],
[-1, -1, -1]])
apply_kernel_to_image(small_image, kernel, 'negative')

Polega to na tym, że macierz idzie kroczek po kroczku po zdjęciu i przemnaża wartości zwracając wynik.
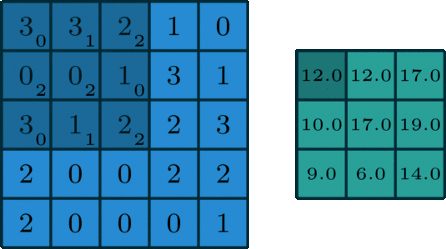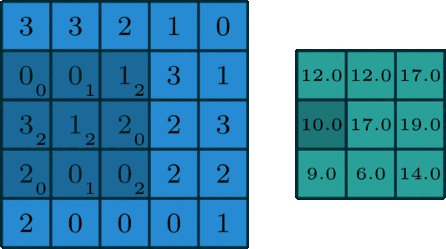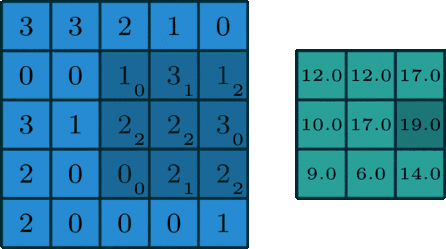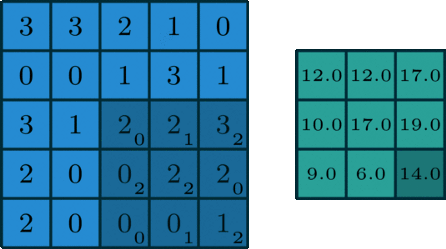
Możesz porównać dobieranie filtrów do inżynierii cech. Każdy taki filtr jest cechą (charakterystyką). Na szczęście nie będziemy ich sami dobierać, tylko pomoże nam w tym… matematyka🙂 i propagacja wsteczna.
Jeśli czujesz matematyczny niedosyt, to polecam zobaczyć wytłumaczenie zasad działania przez Andrew NG na swoim kursie (LINK – klikając free enroll jak dasz na dole „audit this course” będziesz mógł go przerobić za darmo).
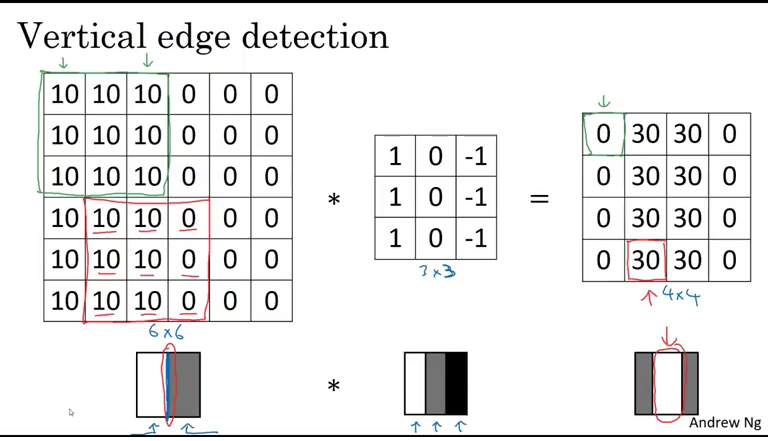
Konwolucyjne sieci neuronowe – architektura
Ostatnio w pracy chętnie sięgam po sieci CNN. Dlatego postaram opisać dokładnie, co robią kolejne warstwy sieci, abyśmy wspólnie je zrozumieli – ja też, bo opisując to dla Ciebie również się uczę.
Warstwa wejściowa (Input Layer)
Jest to warstwa wejściowa, która reprezentuje obraz wejściowy do sieci. Warto zwrócić uwagę na rodzaj obrazu, który mamy. W przypadku kolorowych zdjęć będziemy używać trzech kanałów wejściowych RGB, odpowiadającym odpowiednio kanałom czerwonym, zielonym i niebieskim. W naszym przypadku (Fashion Mnist) mamy skalę szarości i dlatego mamy jeden kanał.
Warstwa konwolucyjna / splotowa (Convolutional Layers)
Warstwy splotowe są podstawą sieci konwolucyjnych CNN, ponieważ zawierają wyuczone filtry (kernele), które wyodrębniają cechy odróżniające od siebie różne obrazy.
Kiedyś zastanawiałem się, dlaczego definiując warstwę CNN nie podajemy tych filtrów. Tak naprawdę wartości w filtrach (tak jak wyżej sami mogliście sobie dobrać, jakie chcieliście) są dobierane i optymalizowane podczas trenowania sieci. I są dobrane tak, by minimalizować błąd naszej sieci przy rozwiązywaniu problemu, który zdefiniujemy. W naszym przypadku będą dobierane takie filtry, aby jak najlepiej odróżnić od siebie różne ubrania garderoby.
Ważne, abyście zwrócili uwagę, że filtry są współdzielone na całym zdjęciu. Zatem wagi dobierane są do filtra, który jest następnie przesuwany po całym zdjęciu.
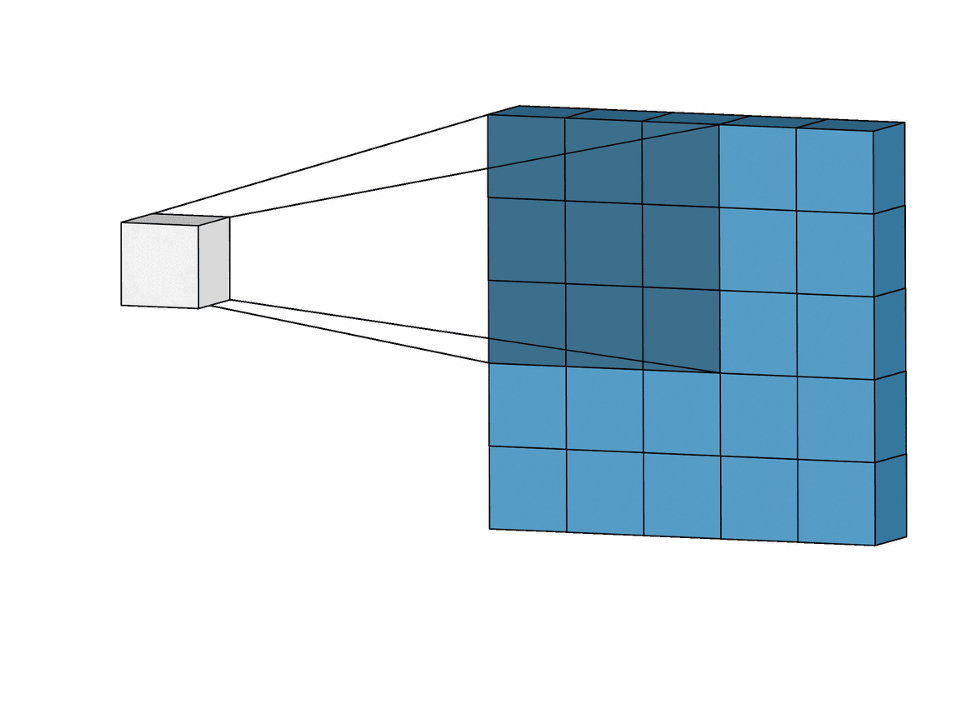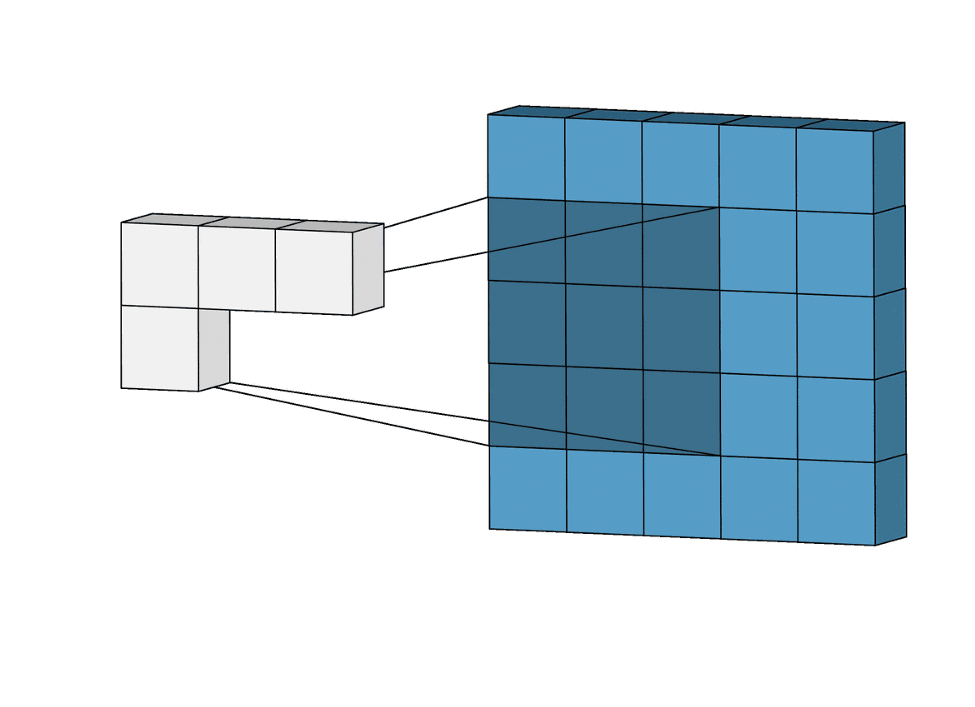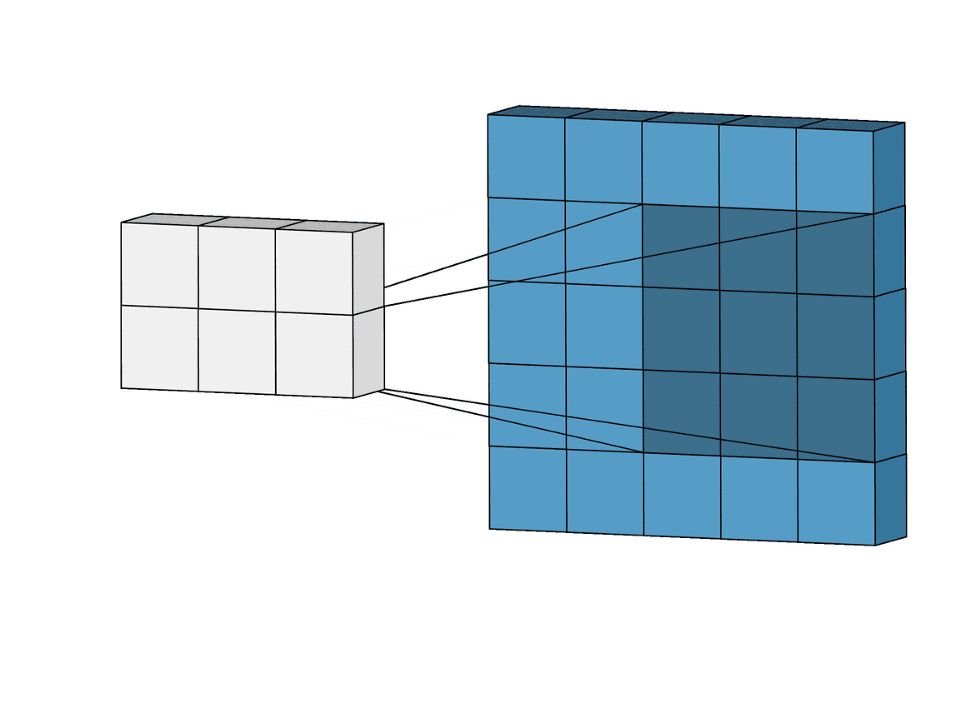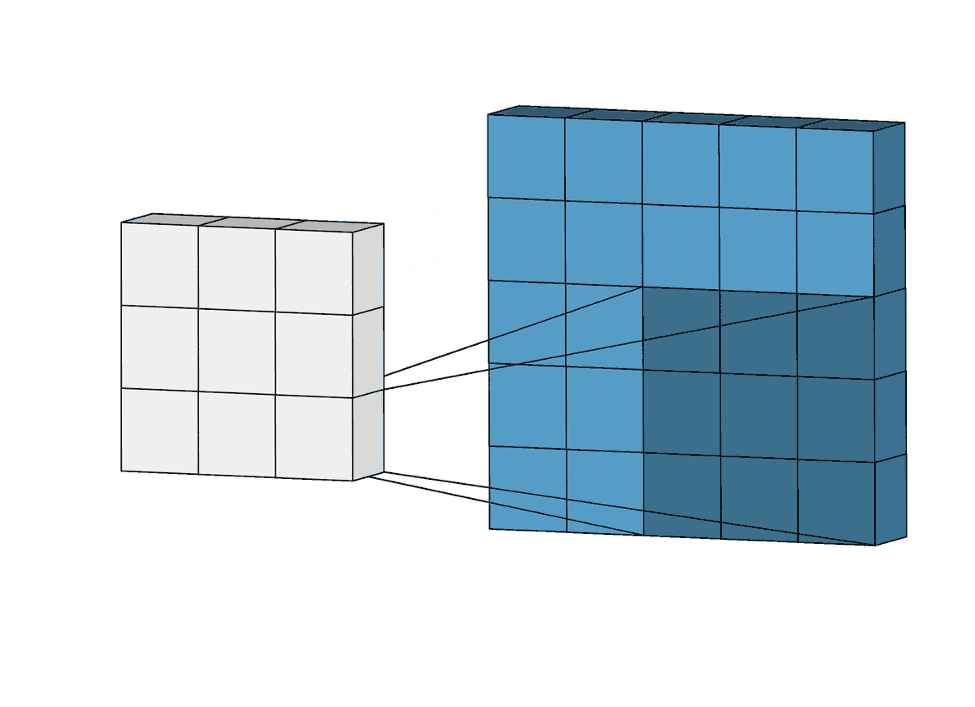
Nawet jeśli będzie trzeba dodać 1 000 filtrów (3×3), to ostatecznie będziemy dobierać „tylko” 9 000 wag. W porównaniu z liczbą wag przy sieci MLP, gdzie mogło być ich nawet około miliarda, widzimy sporą różnicę. A co ważniejsze, rozmiar samego zdjęcia nie wpływa na liczbę wag w warstwie konwolucyjnej!
Hiperparametry dla warstwy kowolucyjnej
Tworząc warstwę konwolucyjną musimy zdefiniować kilka parametrów.
Kernel Size (rozmiar jądra)
Rozmiar jądra, często nazywany również rozmiarem filtra, odnosi się do wymiarów przesuwanego okna nad wejściem. Wybór tego hiperparametru ma ogromny wpływ na zadanie klasyfikacji obrazu. Na przykład małe jądra są w stanie wydobyć z danych wejściowych znacznie większą ilość informacji zawierających wysoce lokalne funkcje. Mniejszy rozmiar jądra prowadzi również do mniejszego zmniejszenia wymiarów warstw, co pozwala na głębszą architekturę.

I odwrotnie, duży rozmiar jądra wyodrębnia mniej informacji, co prowadzi do szybszego zmniejszenia wymiarów warstw, czego skutkiem często jest gorsza wydajność. Ale czasami możemy zyskać lepszą generalizację problemu. Jak w życiu – coś za coś 🙂. Duże jądra lepiej nadają się do wyodrębniania większych elementów.
Ostatecznie wybór odpowiedniego rozmiaru jądra będzie zależał od zadania i zestawu danych, ale generalnie mniejsze rozmiary jądra prowadzą do lepszej wydajności zadania klasyfikacji obrazu.
Padding (wypełnienie)
Padding definiuje sposób obsługi obramowania próbki. Umożliwia to otrzymanie rozmiaru wyjścia takiego samego jak rozmiar wejścia (przy założeniu, że strides jest przesunięciem o jeden). Osiąga się to kosztem dodania dodatkowych (sztucznych) wag na krawędziach (najczęściej z wartością zero). Dlaczego z zerami? Bo są wydajne – zapewniają prostotę i wydajność obliczeniową. Takie podejście jest stosowane w wielu wydajnych sieciach CNN, takich jak AlexNet. Rzuć okiem na poniższy przykład (mam nadzieję, że pozwoli Ci on łatwiej zrozumieć 🙂).
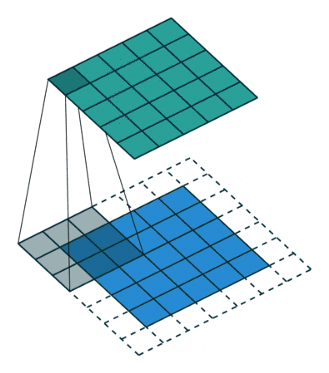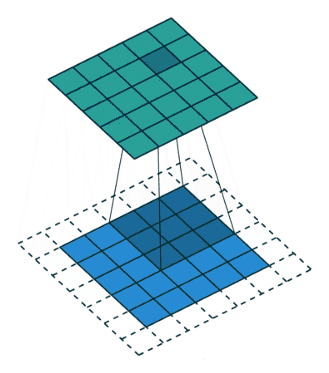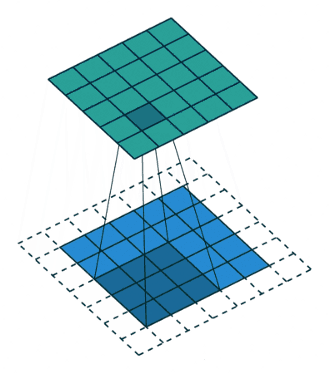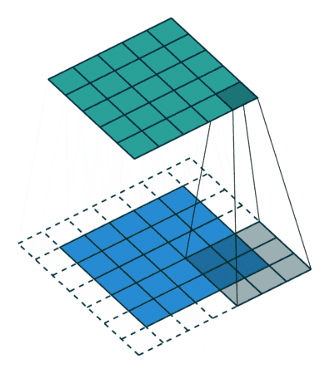
Jak widzisz powyżej, dzięki dodanej „ramce” rozmiar wyjściowy (zielony kwadrat) ma rozmiar 5×5. Tyle samo co obraz wejściowy (niebieski kwadrat). Gdyby nie było dodanej ramki, wówczas rozmiar wyjściowy wynosiłby 3×3.
Strides (kroki)
Parametr stride wskazuje, o ile pikseli jądro powinno zostać przesunięte na raz. Czyli inaczej mówiąc, oznacza krok przesunięcia okna filtra. Najczęściej używa się kroku wynoszącego 1 dla warstw splotowych. Oznacza to, że iloczyn skalarny jest wykonywany w oknie wejściowym np. 3×3 w celu uzyskania wartości wyjściowej, a następnie jest przesuwany o jeden piksel dla każdej kolejnej operacji.
Na poniższym przykładzie masz zobrazowane przesuwanie jądra o wielkości 3×3 (szary kwadrat) po obrazie 5×5 pikseli z parametrem stride równym 2 i padding równym 1.

Funkcje aktywacji
Jednym z powodów, dla których sieci neuronowe są w stanie osiągnąć tak olbrzymią dokładność, jest ich nieliniowość. Nieliniowość jest niezbędna do wytworzenia nieliniowych granic decyzyjnych, tak aby wynik nie mógł być zapisany jako liniowa kombinacja danych wejściowych.
Gdyby nie było nieliniowej funkcji aktywacji, głębokie sieci CNN przekształciłyby się w pojedynczą, równoważną warstwę splotową, która nie działałaby tak dobrze.
ReLU (Rectified Linear Activation)
ReLU stosuje do modelu potrzebną nieliniowość. Dodatkowo została opracowana nie przez matematyków, a informatyków. Dzięki temu jest naprawdę szybka w trenowaniu (bo implementacja jest prosta).

Na przykład, jeśli zastosuje się ReLU na wartości 4,23, wynik będzie wynosił 4,23, ponieważ 4,23 jest większe niż 0. W większości problemów, które rozwiązywałem w pracy, używałem tej funkcji przy sieciach CNN.
SoftMax
Operacja softmax służy kluczowemu celowi: upewnieniu się, że wyniki CNN sumują się do 1. Z tego powodu operacje softmax są przydatne do skalowania wyników modelu na prawdopodobieństwa.

Po przejściu przez funkcję softmax każda klasa odpowiada teraz odpowiedniemu prawdopodobieństwu!
Pooling Layers
Sąsiednie piksele na obrazach mają zwykle podobne wartości, więc warstwy konwolucyjne zazwyczaj również generują podobne wartości dla sąsiednich pikseli w wyjściach. W rezultacie wiele informacji zawartych w danych wyjściowych warstwy konwolucyjnej (conv) jest zbędnych. Na przykład, jeśli użyjemy filtra wykrywającego krawędzie poziome i znajdziemy silną krawędź w określonym miejscu, istnieje bardzo duże prawdopodobieństwo, że znajdziemy je również w miejscach przesuniętych o 1 piksel w prawo i lewo od oryginalnego.
I tutaj z pomocą przychodzi nam „Pooling” (łączenie? – wybacz, ale nie kojarzę jak to fajnie przetłumaczyć:)). Istnieje wiele metod tak zwanego „poolingu” w różnych architekturach CNN, ale wszystkie mają jeden cel. Jest nim stopniowe zmniejszanie rozmiaru obrazu, co zmniejsza liczbę parametrów do wytrenowania. Więc skraca czas działania sieci, upraszcza nasz model i w niektórych przypadkach pomaga walczyć z przeuczeniem (overfitingiem) naszej sieci.
Idea poolingu polega na tym, że kilka pikseli np. rozmiar 2×2 mapujemy na 1 piksel. Najbardziej znane są dwa rodzaje poolingów:
- max (maximum) – gdy bierzemy maksymalną wartość z 4 pikseli,
- avg (avarage) – gdy bierzemy średnią wartość z 4 pikseli.
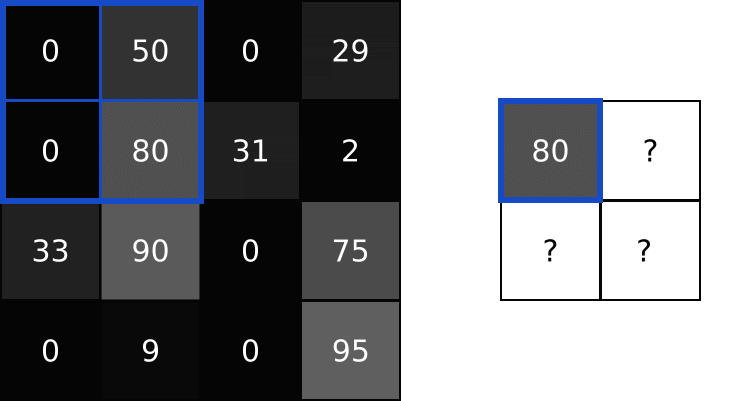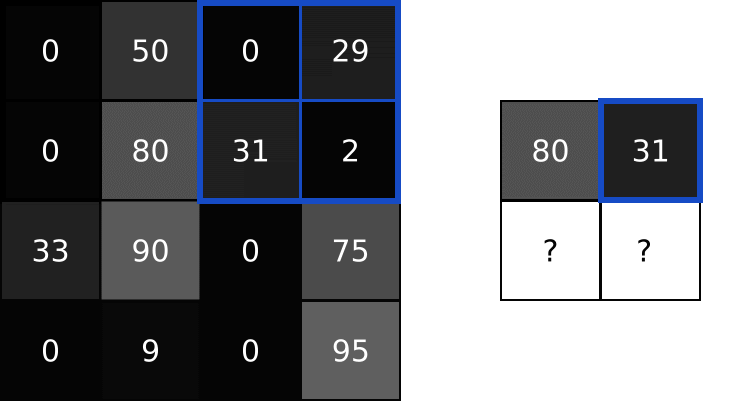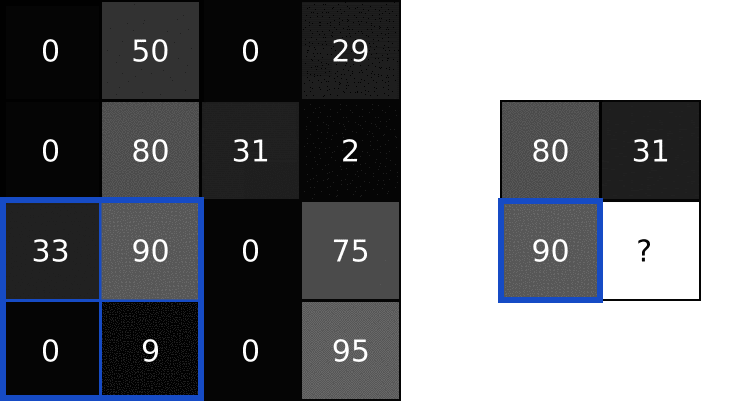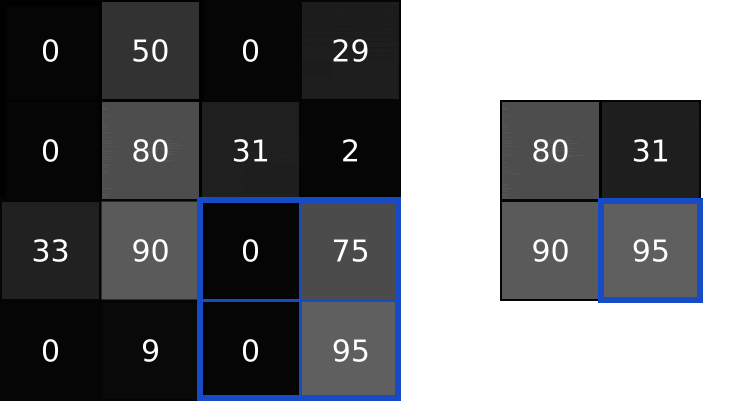
W powyższym przykładzie możesz zobaczyć max pooling z parametrem (size) wynoszącym 2. Dlatego przechodzimy po obrazie wykorzystując rozmiar 2×2 i bierzemy maksymalną wartość jako piksel wyjściowy.
Dropout Layer (wartwa porzucenia)
Tylko przypomnę, że najpopularniejszym sposóbem do walki z przetrenowaniem w przypadku sieci neuronowych (w tym także konwolucyjne sieci neuronowe) jest porzucanie. Dropout polega na losowym ustawieniu wychodzących krawędzi ukrytych jednostek (neuronów tworzących ukryte warstwy) na 0 przy każdej aktualizacji fazy treningu. Metoda ta jest bardzo efektywna, ponieważ co każde przejście losowo wyłączane są połączenia. Dzięki temu sieć neuronowa nie nauczy się „na pamięć” zbyt szybko, ponieważ architektura co przeliczenie odrobinę się zmienia poprzez zerowanie losowych połączeń neuronów.Innymi metodami walki z przeuczeniem są jeszcze:
- regularyzacja wag,
- metoda wczesnego zakończenia (early stopping),
- batch normalization,
- lub… więcej danych.
Jak chcesz wiedzieć więcej, to o większości napisałem troszkę więcej TUTAJ.
Flatten Layer (warstwa spłaszczająca)
Jest to ważny krok. Ta warstwa przekształca naszą wielowymiarową warstwę w sieci w jednowymiarowy wektor. Robimy to po to, aby dopasować dane wejściowe w pełni połączonej warstwy do klasyfikacji. Na przykład tensor o wielkości 10x10x3 zostałby przekształcony w wektor o rozmiarze 300 (1 x 300).
Dlaczego to robimy? Bo zadaniem poprzedzających warstw splotowych sieci było wyodrębnienie cechy z obrazu wejściowego. A teraz nadszedł najwyższy czas, aby sklasyfikować cechy.
Najczęściej używamy funkcji softmax do klasyfikowania tych cech, co wymaga jednowymiarowych danych wejściowych. Dlatego konieczna jest spłaszczona warstwa.
Kod w Python
Przygotujmy sobie na wstępie dane (analogicznie jak w poprzednim projekcie o sieciach). Wczytajmy dane o zbiorze fashion mnist i podzielmy na trzy próbki: treningową do trenowania, testową do sprawdzania mocy i dokręcania modelu i walidacyjną, którą użyjemy do ostatecznego sprawdzenia wyniku.
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
print(f'tensorflow version: {tf.__version__}')
#wczytanie danych
fashion_mnist = tf.keras.datasets.fashion_mnist
(X_train, y_train), (X_val, y_val) = fashion_mnist.load_data()
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train)
print(f'Zbiór uczący: {X_train.shape}, zbiór testowy: {X_val.shape}, zbiór walidacyjny: {X_val.shape}')
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
X_train = X_train.astype('float32') / 255.0
X_val = X_val.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0

Super. Dane wczytane. Najpierw zróbmy prostą architekturę dla sieci MLP byśmy zobaczyli, jakie dała wyniki. Najpierw wczytajmy dodatkowe funkcje:
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, add, Dense, Dropout
from tensorflow.keras.losses import SparseCategoricalCrossentropy
i krótką funkcję do ryzowania wykresu:
def draw_curves(history, key1='accuracy', ylim1=(0.7, 1.00),
key2='loss', ylim2=(0.0, 0.6)):
plt.figure(figsize=(12,4))
plt.plot(history.history[key1], "r--")
plt.plot(history.history['val_' + key1], "g--")
plt.ylabel(key1)
plt.xlabel('Epoch')
plt.ylim(ylim1)
plt.legend(['train', 'test'], loc='best')
plt.show()
Teraz wytrenujmy sieć neuronową MLP dla porównania wyników:
model = Sequential()
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
EarlyStop = EarlyStopping(monitor='val_loss',
patience=5,
verbose=1)
history = model.fit(X_train, y_train,
epochs=100, verbose=1,
validation_data = (X_test, y_test),
callbacks = [EarlyStop],
)
draw_curves(history, key1='accuracy', key2='loss')
score = model.evaluate(X_val, y_val, verbose=0)
print("CNN Error: %.2f%%" % (100-score[1]*100))
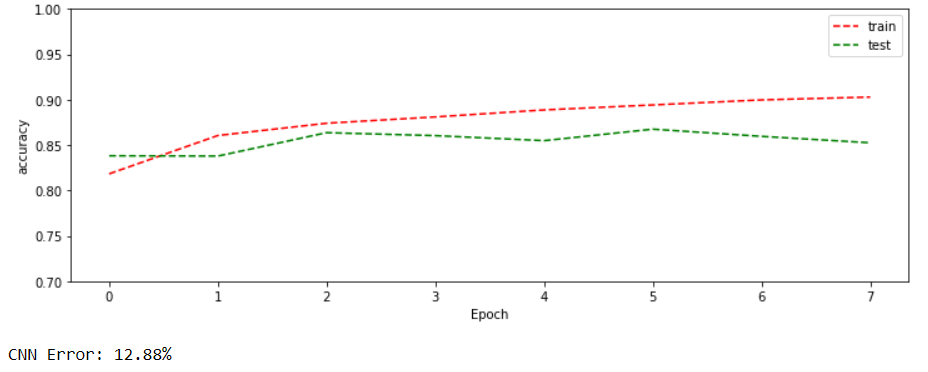
Błąd na próbce walidacyjnej wynosi prawie 13%. Nie jest źle. Ciekawe czy konwolucyjne sieci neuronowe ten wynik przebiją.
Wczytajmy dodatkowe warstwy:
from tensorflow.keras.layers import Conv2D, MaxPool2D
I troszeczkę musimy poprawić nasze dane wejściowe.
Wiemy, że w naszym zbiorze wszystkie obrazy mają ten sam rozmiar kwadratu 28 × 28 pikseli i że obrazy są w skali szarości. Dlatego możemy załadować obrazy i zmienić kształt tablic danych, aby mieć jeden kanał koloru.
# w przypadku CNN należy dodać jeszcze info o kanałach
X_train_cnn = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test_cnn = X_test.reshape((X_test.shape[0], 28, 28, 1))
X_val_cnn = X_val.reshape((X_val.shape[0], 28, 28, 1))
I teraz definiująć pierwszą wejściową warstwę zdefiniujemy rozmiar jako input_shape=(28, 28, 1).
Konwolucyjne sieci neuronowe CNN – pierwszy model
Zbudujmy pierwszy model! Stwórzmy prostą sieć składającą się z jednej warstwy konwolucyjnej z filtrem 3×3, a następnie MaxPooling. Potem spłaszczmy wektor i przepuśćmy przez warstwę gęstą.
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()

history = model.fit(X_train_cnn,
y_train,
epochs=100,
verbose=1,
validation_data = (X_test_cnn, y_test),
callbacks = [EarlyStop],
)
draw_curves(history, key1='accuracy', key2='loss')
score = model.evaluate(X_val_cnn, y_val, verbose=0)
print("CNN Error: %.2f%%" % (100-score[1]*100))

Jak widać mimo użycia prostej architektury model się poprawił. Teraz błąd wynosi już poniżej 10%. Pobawmy się jeszcze chwilkę i dodajmy kolejną warstwę konwolucyjną:
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()

Zwróćcie proszę uwagę, jak spadła liczba parametrów do niecałych 486 tysięcy. Wytrenujmy jeszcze wynik i sprawdźmy, czy kolejna warstwa coś poprawiła.
history = model.fit(X_train_cnn,
y_train,
epochs=100,
verbose=1,
validation_data = (X_test_cnn, y_test),
callbacks = [EarlyStop],
)
draw_curves(history, key1='accuracy')
score = model.evaluate(X_val_cnn, y_val, verbose=0)
print("CNN Error: %.2f%%" % (100-score[1]*100))
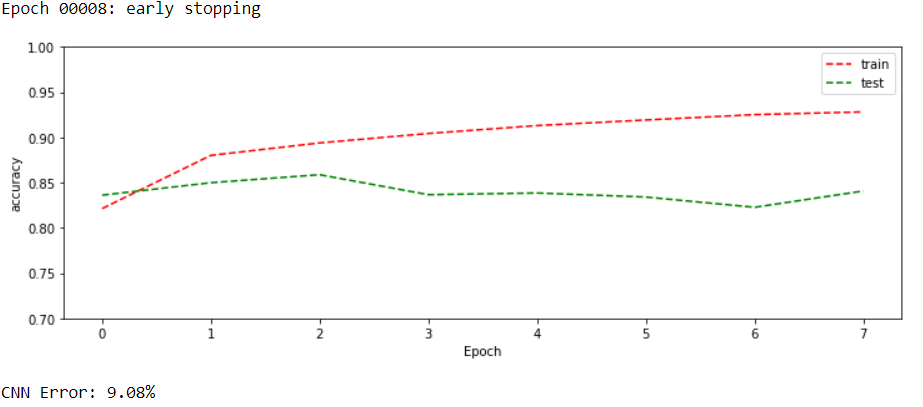
Jupi! Udało się zmniejszyć błąd i przebić wcześniejszy wynik.
Jeśli przeglądniecie znane architektury sieci neuronowych z modeli „State of the Art” , to dostrzeżecie, że często wykorzystywany jest sposób robienia wdówch warstw sieci konwolucyjnych a potem pooling. Sprawdźmy czy coś to jeszcze poprawi:
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()

history = model.fit(X_train_cnn,
y_train,
epochs=100,
verbose=1,
validation_data = (X_test_cnn, y_test),
callbacks = [EarlyStop],
)
draw_curves(history, key1='accuracy')
score = model.evaluate(X_val_cnn, y_val, verbose=0)
print("CNN Error: %.2f%%" % (100-score[1]*100))

I jak widać, również w tym przypadku zadziałało. Jeśli masz ochotę wypróbuj kilka różnych własnych architektur i pochwal się w komentarzu wynikami, jakie masz!
Jak interpretować warstwy konwolucyjne?
Jeśli chcesz jeszcze lepiej zrozumieć jak działają sieci, to polecam krótki filmik pokazujący narzędzie CNN Explainer. Polecam pobawić się narzędziem jak znajdziesz chwilkę.
A tutaj na YouTube opis:
Mam nadzieję, że rozjaśniłem Ci, czym są konwolucyjne sieci neuronowe.
A jeśli zbudowałeś swoją architekturę podziel się w komentarzu jaką oraz wynikiem!
Pozdrawiam serdecznie z całego serducha,




Pingback: Uczenie głębokie – założenia, technologie, narzędzia, możliwości, ograniczenia, zastosowania, zagrożenia. – Etyczne i społeczne aspekty przetwarzania danych i sztucznej Inteligencji
„Na przykład małe jądra są w stanie wydobyć z danych wejściowych znacznie większą ilość informacji zawierających wysoce lokalne funkcje”
Co znaczy „wysoce lokalne funkcje” ???
Cześć, a dlaczego w przypadku CNN zmiennej zależnej y nie rozkodowujemy na zmienne kategoryczne zerojedynkowe jak w przypadku ANN?
Dobra chyba już znam odpowiedź. W tym celu użyliśmy funkcji „SparseCategoricalCrossentropy”. 🙂
Witam,
mam trzy pytania:
1. Podczas trenowania modelu otrzymuję user warning: „`sparse_categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a sigmoid or softmax activation and thus does not represent logits. Was this intended?”. Czy dobrym sposobem na rozwiązanie problemu jest ustawienie from_logits na False?
2. W każdym epochu podczas wyświetlania się postępu pokazuje mi, że przetworzono 1407/1407 próbek. W zbiorze X_train jest ich jednak 45000. Dlaczego podczas trenowania sieci nie są używane wszystkie próbki?
3. Rozumiem, że zamiana X_train oraz X_val za pomocą metody astype na float32 i podzielenie ich przez 255 pozwala na zapisanie ich w zakresie od 0 do 1. Dlaczego jednak nie zrobił Pan tego samego z X_test?
Doszedłem już do odpowiedzi na drugie pytanie. Wyświetlana jest liczba próbek w batchu a nie w całym zbiorze. Defaultowy batch_size = 32, dlatego 45000/32 = 1407
P.S.
Przepraszam za dodanie dwóch komentarzy (strona zaktualizowała się dopiero po 5 minutach).
Hejo!
1. Tak 🙂
2. Gratuluje, że sam znalazłeś odpowiedź. Dobra cecha naukowca danych 🙂
3. Ponieważ nie zauważyłem tego błędu z mojej strony. Bardzo dziękuję za zwrócenie uwagi i już poprawiam! Oczywiscie, że trzeba tak samo podejść do preprocessingu wszystich zbiorów tak samo! 🙂
Super, dzięki!
Thx!
Bardzo fajny teks. Dzięki!
dziękuję Adrian!
Wielkie dzięki! Świetnie wyjasnione
Dziękuję 🙂
Pingback: Sieci konwolucyjne do rozpoznawania zapalenia płuc! - Mirosław Mamczur