
– Hej Tato, co dzisiaj robiłeś w pracy? – zapytała Jagódka.
– Dzisiaj rysowałem słowa, aby zobaczyć, czy dobrze je wytrenowaliśmy – odpowiedziałem.
– Jak to rysowałeś słowa na wykresie? Nie rozumiem.
– Hmm… Słowa są bardzo ciekawą rzeczą. Rzadko występują bez ładu i składu i często to, co jest koło nich ma znaczenie. To tak jak na Twojej półeczce z książkami. Masz pięknie poustawiane wszystkie książki w jakiejś kolejności. Najpierw jest seria z „Maszą i Niedźwiedziem”. Następnie stoją książeczki z księżniczkami, za nimi książeczki o autkach, a dalej o zwierzątkach. Każda ma swoje miejsce, prawda? Gdyby nagle jedna z książek o księżniczkach była obok bajek o zwierzaczkach, coś byłoby nie tak. W ten sam sposób narysowałem słowa, aby spojrzeć czy podobne z nich są koło siebie.
– Ale to oczywiste tatusiu. Przecież Bella nie może być obok zwierzątek, tylko MUSI być z innymi księżniczkami.
We wcześniejszych dwóch wpisach opisałem dwie najbardziej podstawowe metody redukcji wymiarów: PCA oraz t-SNE. Chciałem Wam teraz pokazać przykład z życia wzięty, gdzie i w jaki sposób można wykorzystać te metody do wizualizacji. A będziemy wizualizować word embedding.
Czym jest word embedding (osadzenie słów)?
Word embedding jest określeniem technik (modeli), które nauczyły się zapisywać słowa w postaci wektorów. Technika ta pojawiła się na początku lat 2000 za sprawą serii prac Yoshuy Bengio, jednak prawdziwy jej rozkwit nastąpił w 2013 roku za sprawą publikacji prac zespołu Google pod przewodnictwem Tomasa Mikolova. Na ostatniej konferencji DataWorkshop miałem niesamowitą przyjemność osobiście poznać Tomasa i chwilkę z nim porozmawiać o metodach używanych przeze mnie do zagadnień, nad którymi obecnie pracuję w Santander.
A po co w ogóle słowa osadzać w takich przestrzeniach? Po pierwsze, ponieważ modele uczenia maszynowego (sieci, gradient boostingi, drzewa) zostały zaprojektowane do uczenia się na liczbach. A po drugie zagnieżdżanie słów tak naprawdę polega na poprawie zdolności do uczenia się na podstawie danych tekstowych reprezentując te dane jako wektory o niższych wymiarach. To właśnie te wektory nazywane są embeddingami (osadzeniem).
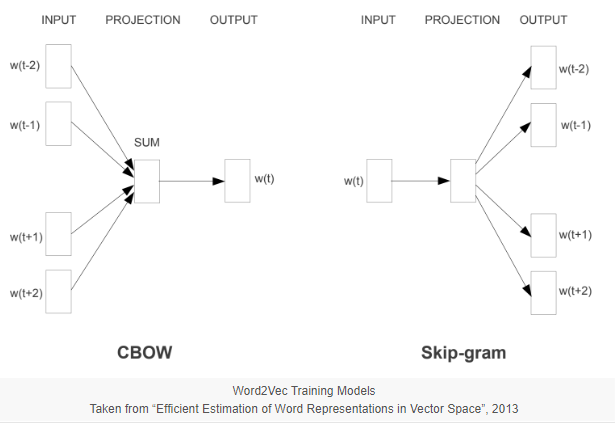
Do stworzenia word embedding stosuje się przede wszystkim dwie metody:
– Continuous Bag of Words (CBoW),
– Continuous skip-gram.
W pierwszej z nich model przewiduje aktualnie uczone słowo na podstawie słów otaczających bez uwzględnienia kolejności (bag of words). W drugiej model wykorzystuje aktualne słowo do prognozowania słów otaczających, przy czym słowom bliższym przyporządkowana jest wyższa waga. Dokładniej omówię obie metody w jednym z kolejnych wpisów.
Po co wizualizować word embedding?
Wizualizacja embeddingów to potężna technika! Pomaga zrozumieć, czego nauczył się algorytm i czy jest to zgodne z tym, czego się spodziewaliśmy.
Pomyślcie o tym w ten sposób: mając 5 wymiarową przestrzeń, słowie TATA można byłoby przypisać wektor [1, 1, 0.5, 0.2, 0] a MAMA [0, 0, 0.5, 0.2, 0]. Dzięki prostym wzorom matematycznym TATA minus MAMA da nam wektor [1, 1, 0, 0 ,0]. Ten wektor mógłby odzwierciedlać słowo KOBIETA. Fajnie byłoby takie zależności zwizualizować, aby potwierdzić czy dobrze zostały wytrenowane embeddingi.
Czym jest TensorBoard?
TensorBoard to interfejs służący do wizualizacji wykresów i innych narzędzi do zrozumienia, debugowania oraz optymalizacji modeli.
Wizualizacja word embeddingów jest standardową funkcją w TensorBoard. Do jej przygotowania należy skorzystać z projektora, który oferuje nam TensorBoard.
Składa się on z trzech głównych elementów:
- Panel danych – służy do uruchamiania danych do wizualizacji,
- Panel rzutów – miejsce do wyboru rodzaju rzutu i metod redukujących wymiary,
- Panel słów – służy do wyszukiwania określonych słów i patrzenia na najbliższych sąsiadów.

Jeśli nie możecie się doczekać stworzenia własnej wizualizacji to możecie wejść na przykład przygotowany przez twórców tensorflow: https://projector.tensorflow.org/
Mając wizualizacje możecie zagłębić się w zrozumienie word embedding, które macie. Możecie je przybliżać, oddalać, obracać lub przesuwać wykres w sposób, jaki Wam odpowiada. Można wskazać kursorem myszy punkt i zobaczyć co on oznacza. Ponadto wyświetleni zostaną najbliżsi sąsiedzi od bieżącego punktu.
Przykład w Python
Jeśli już wiemy, co możemy przygotować, to spróbujmy to zrobić sami.
Dane
Tak jak wspomniałem wcześniej, nie będziemy zajmować się wytrenowaniem własnych embeddingów, tylko skorzystamy z już przygotowanych i wytrenowanych dla języka polskiego. Tutaj jest strona z wieloma gotowymi embeddingami: http://dsmodels.nlp.ipipan.waw.pl/
Ja pobrałem najmniejszy zbiór (po rozpakowaniu i tak jest to 280 MB!), który został wytrenowany na polskiej Wikipedii.
import numpy as np
import tensorflow as tf
import os
import subprocess
import tempfile
from tensorboard import main as tb
from tensorflow.contrib.tensorboard.plugins import projector
Poniżej definiujemy ścieżkę do ściągniętych embeddingów oraz sprawdzamy czy się poprawnie wczytują.
VECTORS_PATH = r'../data/wiki-forms-all-100-skipg-ns-30-it100.txt'
TENSORBOARD_PORT = 2345
with open(VECTORS_PATH, encoding='utf-8') as input_file:
print('Plik z wektorami się wczytuje')
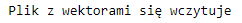
Przygotowanie danych
Teraz stwórzmy tymczasowy folder, gdzie zapiszemy wszystkie dane potrzebne do przygotowania wizualizacji word embedding w TensorBoard:
# tworzenie tymczasowego folderu
temp_tensorboard_directory = tempfile.TemporaryDirectory()
temp_tensorboard_directory_name = temp_tensorboard_directory.name
print(f'Folder do przygotowania wizualizacji embeddingów: {temp_tensorboard_directory.name}')
#przygotowanie ścieżek i nazw plików
metadata_output_path = os.path.join(temp_tensorboard_directory_name, 'metadata.tsv')
model_checkpoint_path = os.path.join(temp_tensorboard_directory_name, 'model.ckpt')
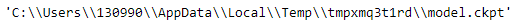
Teraz zapiszmy nasze dane w postaci array z numpy:
#przygotowanie embeddingów zapisanych w formie array i zapis do folderu tymczasowego
words, embeddings = [], []
with open(VECTORS_PATH, encoding='utf-8') as input_file:
for line in input_file:
word, *embedding = line.split()
words.append(word)
embeddings.append(np.array(embedding, dtype=float))
embeddings = np.array(embeddings)
with open(metadata_output_path, 'w', encoding='utf-8') as output_file:
output_file.writelines(word + '\n' for word in words)
A teraz zapiszmy embeddingi w odpowiedniej formie pod TensorBoard:
embeddings_var = tf.Variable(embeddings, name='moje_embeddingi', trainable=False)
summary_writer = tf.summary.FileWriter(temp_tensorboard_directory_name)
Parametryzacja
W tym kroku określamy zmienną, którą chcemy rzutować oraz jaka jest ścieżka metadanych (nazwy i klasy).
# Create a config object to write the configuration parameters
config = projector.ProjectorConfig()
config.model_checkpoint_path = model_checkpoint_path
# Add embedding variable
embedding = config.embeddings.add()
embedding.tensor_name = embeddings_var.name
# Link this tensor to its metadata file (e.g. labels) -> we will create this file later
embedding.metadata_path = metadata_output_path
# Write a projector_config.pbtxt in the logs_path.
# TensorBoard will read this file during startup.
projector.visualize_embeddings(summary_writer, config)
Teraz należy zainicjować sesję ze zdefiniowanymi zmiennymi i zapisać je w katalogu.
session = tf.InteractiveSession()
session.run(tf.global_variables_initializer())
# Save the tensor in model.ckpt file
saver = tf.train.Saver()
saver.save(session, model_checkpoint_path)

Wizualizacja
I to wszystko! Teraz wystarczy zobaczyć naszą wizualizację!
Możemy zrobić to bezpośrednio z konsoli lub z Jupyter Notebook’a.
print(f'tensorboard --logdir={temp_tensorboard_directory_name} --port={TENSORBOARD_PORT}')
subprocess.call(['tensorboard', '--logdir={}'.format(temp_tensorboard_directory_name), '--port={}'.format(TENSORBOARD_PORT)])
Następnie należy wpisać adres lokalny (Link można podejrzeć w konsoli) w przeglądarkę i mamy efekt naszej pracy!

Mam nadzieję, że przyda Wam się powyższa wizualizacja w Waszych projektach.
Pozdrawiam serdecznie,




Pingback: Bazy wektorowe w projektach AI: od teorii do praktyki - beAIware.pl
Dzięki! Świetna robota! 🙂
Pingback: Czym jest i jak działa transformer (sieć neuronowa)? - Mirosław Mamczur