
– Tatusiu, pobawisz się z nami w Psi patrol? – zapytała Jagódka.
– Hmm… za minutkę Skarbie. Teraz zacząłem zabawę transformerami – uśmiechnąłem się.
Jagódka i Oti zaczęły rozglądać się po pokoju.
– Ale nigdzie nie widzimy tych robo samochodzików. Chłopcy w przedszkolu je uwielbiają.
– Aaaa. Ja się bawię troszkę innymi. To taka magiczna maszynka, gdzie wrzucasz mu jedno zdanie, a dostajesz nowe zdanie, artykuł, czy nawet wiersz.
Sieci neuronowe typu transformer podbijają świat w zakresie przetwarzania tekstu. Są naprawdę niesamowitymi modelami, często określanymi jako „state of the arts„. Używane są do:
- przewidywania kolejnego słowa,
- tłumaczenia z innego języka,
- odpowiadania na pytania,
- podsumowywania dokumentu,
- parafrazowania,
- tworzenia nowego tekstu,
- gry w szachy (praca z sierpnia 2020),
- i wielu innych…
Jeśli troszkę obracasz się w świecie data science i uczenia maszynowego, to pewnie słyszałeś o najbardziej znanych transformerach takich jak BERT, GPT-2 czy GPT-3. Super, że są i możemy ich używać. Ale jak działają?
Czym jest transformer w uczeniu maszynowym?
Wszystko zaczęło się nie tak dawno temu od pracy naukowej „Attention is all you need” przestawionej w 2017 roku. Artykuł omawiał nowatorską architekturę zwaną Transformer.
Miała ona na celu rozwiązywanie zadań sekwencyjnych (sequence-to-sequence). Czyli na wejściu mamy jedną sekwencję (np. zdanie lub akapit) i otrzymujemy inną (np. przetłumaczone zdanie lub streszczenie akapitu).
Niemniej jednak model transformatora może wykonać prawie każde zadanie dotyczące przetwarzania naturalnego języka (NLP). Możemy go użyć do modelowania języka, tłumaczenia lub klasyfikacji. Transformer wykonuje te zadania szybko, usuwając sekwencyjną naturę problemu, czyli zamiast przekazywać do sieci wyraz po wyrazie, od razu przekazywane jest całe zdanie.
Do tej pory jednym z najlepszych sposobów uchwycenia zależności w sekwencjach były sieci rekurencyjne (RNN, GRU czy LSTM). I to one głównie były wykorzystywane do rozwiązywania problemów NLP. Sam w tym roku wykorzystałem sieć LSTM do predykcji ryzyka na podstawie surowych transakcji (jeszcze nie znałem transformerów :P). Jednak zespół prezentujący artykuł udowodnił, że można poprawić wyniki w zadaniach np. tłumaczeniowych, mimo rezygnacji z RNN na rzecz mechanizmu uwagi! Największą różnicą było to, że do sieci rekurencyjnych kolejne słowa wchodzą jedno po drugim a w transformerze wchodzi cała sekwencja od razu!

W tym artykule pokażę przykład transformera służącego do tłumaczenia języka polskiego na hiszpański! A co, niech będzie ukłon w stronę głównego właściciela banku, w którym pracuję (Santander) :).
Ogólnie możesz wyobrazić sobie, że transformer działa tak:

Prosto? Spokojnie – nie chcę byś uciekł. Zaraz pokażę architekturę z pracy naukowej😛 Kilka dni próbowałem ją zrozumieć.
Na czym polega idea działania transformera?
Bardzo upraszczając – transformer jest zasadniczo stosem warstw kodera i dekodera (więcej o koderach i dekoderach możesz poczytać w tym poście).
Rolą warstwy kodującej jest zakodowanie naszego polskiego zdania do postaci numerycznej (używany jest tzw. mechanizm uwagi, ale szczegóły za chwilkę). Z drugiej strony dekoder ma na celu wykorzystanie zakodowanych informacji z warstw kodera do uzyskania tłumaczenia na język hiszpański.
Dobra, sięgnijmy teraz do oryginalnej architektury i zwiększmy poziom szczegółowości!
Architektura transformera
Pierwotna architektura transformera wygląda tak:
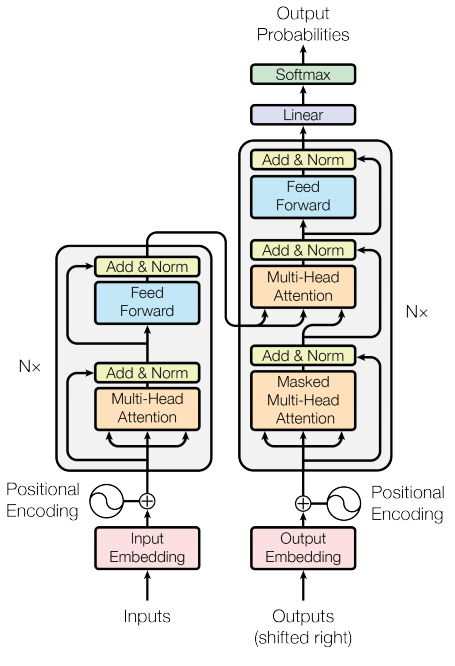
Na początku można się przerazić, ale przeanalizujmy wszystko po kolei. Podzielmy całą architekturę na małe kawałki.
To zaczynajmy!
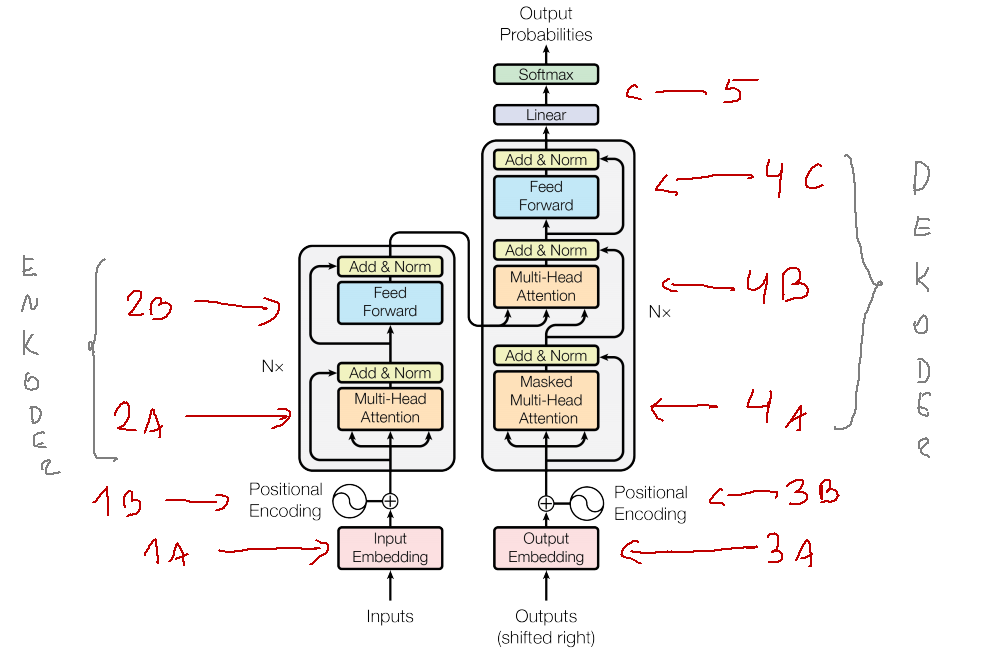
1a. Input Embedding
Powiem to krótko i brutalnie – komputery nienawidzą tekstu. Za to kochają liczby. Z tego powodu najchętniej działają na macierzach.

Dlatego w pierwszym kroku zamieniamy słowa na liczby wykorzystując tzw. zanurzenie (ang. embeddings). Polega ono na tym, by osadzić słowa w przestrzeni wielowymiarowej. Słowa o podobnym znaczeniu powinny być w przestrzeni koło siebie.

Można samemu wytrenować embeddingi albo skorzystać z już dostępnych (np. wytrenowane dla języka polskiego są tutaj). A o wizualizacji embeddingów pisałem TUTAJ.
1b. Positional Encoding
Embeddingi zamieniają słowo na wektor. Ale to samo słowo w różnym kontekście może mieć różne znaczenie.

I tutaj wchodzą do akcji tzw. „positional encoders”, czyli enkodery pozycjonujące. Są to wektory, które dają kontekst na podstawie pozycji słowa w zdaniu / sekwencji.

W papierze wykorzystano funkcje sinusa i cosinusa do generowania tych funkcji. Natomiast można byłoby stworzyć inne rozsądne funkcje (choć nic mi nie przychodzi do głowy :P)
Zatem mając wcześniejsze embeddingi zamieniamy słowa z naszego polskiego zdania na wejściu i dodając pozycje w zdaniu otrzymujemy słowo zapisane wektorowo (czyli embeding) z informacją o kontekście ! Super 🙂

Przechodzimy teraz do naszego enkodera (lub jak niektórzy wolą kodera), który składa się z dwóch elementów.

2a. Multi-Head Attention
Pamiętasz tytuł pracy naukowej, w której pierwszy raz przedstawiono transformery? „Attention is all you need„. Zatem dobrze się domyślasz, że ten kawałek będzie teraz istotny :).
Wyliczając wartość uwagi (attention) tak naprawdę odpowiadamy na pytanie: jak istotne jest dane słowo w zdaniu polskim, w stosunku do innych słów w tym samym zdaniu. Matematycznie jest to przedstawione za pomocą wektora uwagi (attention vector), który jest obliczany dla każdego słowa. Wektor wychwytuje relacje kontekstowe między słowami w zdaniu.

Problemem jest to, że dla każdego słowa jego uwaga będzie najwyższa. Natomiast taka informacja jest troszeczkę … nieprzydatna. Chcemy tak naprawdę mieć interakcje z innymi słowami. Dlatego tworzymy 8 niezależnych wektorów dla każdego słowa, a następnie liczymy średnią ważoną, aby policzyć wektor uwagi dla poszczególnych słów. Ponieważ używamy wielu wektorów to… już się domyślasz :), że nazywamy to „multi-head attention”.
2b. Feed Forward
Mamy nasze wektory dla słów. Teraz przekazujemy je do zwykłej sieci MLP (Multi Layer Perceptron), która jest używana dla każdego wektora uwagi w celu przekształcenia go i przekazania do kolejnej warstwy enkodera lub do dekodera.

I tutaj ważna rzecz! Każdy wektor jest niezależny. Zatem każdy można wrzucić do osobnej sieci, dzięki czemu zrównoleglimy wyliczenia i znacznie przyśpieszymy proces! To sprawia, że możemy przekazać w tym samym czasie nasze słowa do kodera, który zwróci tyle samo zakodowanych wektorów.
Uff… już półmetek architektury.

Lećmy dalej. Teraz przejdźmy do drugiej części bloku archutektury, gdzie znajduje się dekoder. Jego głównym zadaniem ma być przewidywanie kolejnego występującego słowa. Czyli wracając do przykładu „Mam ładne …” przewidujemy prawdopodobieństwa dla kolejnego słowa.
3a. Embedding & 3b. Positional encoding
Tak jak poprzednio zaczynamy karmić maszynę danymi. Tutaj na wejściu dajemy zdanie po hiszpańsku. W pierwszym kroku, tak jak poprzednio, zamieniamy słowa na embeddingi przekształcając słowo na wektor. Następnie również dodajemy wektor pozycjonujący. Ten wektor przekazujemy do poziomu dekodera, który składa się z trzech głównych elementów.

4a. Masked Multi-Head Attention
Tak jak poprzednio w pierwszym kroku mamy „uwagę”. Natomiast nie możemy przekazać całego zdania, bo byłoby to zbyt proste. Z tego powodu nakłada się tak zwaną „maskę”.
Podobne jest to do zadań związanych z przetwarzaniem obrazu, gdzie również nakłada się czasami maski (jak tutaj przy płaszczu niewidce LINK).

Często „maska” to po prostu macierz zer. Mamy już zamaskowane zdanie i wyliczony wektor uwag. Zanim przejdziemy do wyliczenia prawdopodobieństwa z przewidywanym kolejnym słowem to najpierw…
4b. Multi-head Attention with encoder
… łączymy dwa wektory ze sobą – wyjściowy z enkodera i z powyższego kroku 4a z dekodera.

W tym miejscu dzieje się „magia” 🙂 . Tak naprawdę sprawdzane jest w jakim stopniu każdy wektor słów jest ze sobą powiązany. Tutaj dokonywane jest właśnie połączenie, czyli w naszym przypadku zamiana polskich słów na hiszpański.
4c. Feed Forward
Następnie przekazujemy wektory do sieci Feed-Forward. Jej zadaniem jest uproszczenie tłumaczenia wektora, by łatwiej było przerobić transformerowi wynik parowań.
Później wynik z sieci przekazywany jest do „linear layer„, który przekształca wcześniejsze wyniki w wymiar wynoszący dokładnie tyle, ile jest słów w języku hiszpańskim. W kolejnym kroku funkcja „softmax” zamienia wyniki w prawdopodobieństwa, co dla nas ludzi jest bardzo fajne zrozumiałe i interpretowalne.
A czym jest wyjściowe słowo? Po prostu słowem z najwyższym prawdopodobieństwem z wcześniejszego etapu!
Brawo, dobrnęliśmy do końca. W ten sposób trenując taki transformer dla dużej ilości tekstu będziemy mieli fajny model do tłumaczenia z polskiego na hiszpański.
Transformer – zalety i wady
Główną zaletą transformerów jest szybkość działania w porównaniu z siecią RNN lub LSTM. Ponadto elementem, który wpływa na to, że coraz chętniej się po nie sięga, są dużo lepsze wyniki w porównaniu z innymi algorytmami.
Wady transformerów to m.in.:
- potrzeba dużej mocy obliczeniowej, aby zostały wytrenowane;
- potrzeba naprawdę dużej ilości danych do wytrenowania;
- są stosunkowo młodymi modelami i jeszcze nie mamy ich „wyczucia” chociażby w aspekcie hiperparametrów;
- dostępne są przykłady, że gorzej sobie radzą z hierarchicznymi danymi;
- w związku z tym, że są stosunkowo nowe, to w przypadku „buga” możliwe, że będziesz pierwszą osobą, która go zobaczy i będziesz próbował zgłosić do poprawy.
Podsumowanie
Mam nadzieję, że po lekturze tego artykułu, choć troszkę bliższe Ci jest pojęcie transformerów. Jeżeli czujesz niedosyt i chciałbyś zagłębić się bardziej w to zagadnienie to odsyłam Cię do pracy „Attention is all you need„. Dowiesz się z niej, co i jak się przelicza oraz poznasz wzory matematyczne. Przyjemnej lektury!
Do usłyszenia wkrótce!
Pozdrawiam serdecznie z całego serducha,




Literówka – powinno być „architektury”?
„Teraz przejdźmy do drugiej części bloku archutektury, gdzie znajduje się dekoder.”
Super artykuł! Bardzo przystępnie wytłumaczone 🙂
Czy znasz jakiś kod, czy bibliotekę do sieci neuronowych?
Tak, gdyby co to pracuję nad własna biblioteką(ułatwienie do korzystania z bibliotek(np. datetime, googlesearch, speech_recognition) + własne funkcje).
Mógłbym Ci nią kiedyś przesłać!
Wydaje się spoko.
Mam nadzieje, że ułatwi niektórym osobą programowanie w pythonie. ( :
Myślałem nad modułem do kamery i widziałem twój artykuł:
https://miroslawmamczur.pl/wykrywanie-twarzy-real-time-w-15-liniach-kodu-w-python/
Czy mógłbym wykorzystać twój kod?
Jasne, wszystko co jest na blogu jest dla Was, do czytania, kopiowania i robienia z tym co chcecie 🙂
A odnośnie bibliotek jest kilka. Najbardziej popularne w python to tensorflow i pytorch.
Ciekawy artykuł.
Trochę wiem już o sieciach neuronowych(„transformerach”), lecz nie wiem jak napisać kod do AI wykorzystując sieci neuronowe(„transformery”).
Chyba numpy odegra ważną role macierzami, ale nie wiem jakie są algorytmy do zmieniania danych neuronów(a*x+b*y+c=ans) bez podawania reakcji(poprawnej).
//a //b //c
Myślałem o napisaniu kodu do uczenia robota chodzić, ale nie wiem jak np. dać reakcje(poprawną). Może -1*reakcje_robota/”prędkość_uczenia”.
Polecam dwa filmiki, które oglądałem jakiś czas temu o sieciach neuronowych („transformerach”):
1) https://www.youtube.com/watch?v=98uGsNvkzTI 23 min bardzo dobry
2) https://www.youtube.com/watch?v=kTMRfJWcBfA 11 min dobry
Wow, bardzo ciekawy temat 🙂 Ja akurat zaawyczaj korzystam z gotowców i nie piszę nic od podstaw tak jak Ty zamierzasz. Dlatego tym bardziej będę trzymał za Ciebie kciuki i Ci kibicował 🙂
„(więcej o koderach i dekoderach możesz poczytać w tym poście).” ) => brakuje linku 🙂
Dzieki, robisz fantastyczna robote, mistrzu !!
dziękuję za miłe słowa!
i korektę – już poprawione 🙂
Mam pytanie odnośnie Input Embedding i Positional Encoding. Jeśli dobrze rozumiem, to oba to są jakieś wektory liczb, które są do siebie dodawane i przekazywane dalej.
Dodając wektor Positional Encoding, zmieniamy ten początkowy wektor Input Embedding i tracimy informację jakiego słowa on dotyczył.
Może się chyba zdarzyć, że po dodaniu Input Embedding i Positional Embedding dla różnych słów i pozycji w zdaniu, otrzymamy identyczne wektory i skąd wtedy wiadomo, o jakie słowo i z jakiej pozycji chodzi?
Hej Dominik! Bardzo ciekawe pytanie. Niestety aż tak głęboko się nie zagłębiałem we wzory i nie jestem pewien czy może się zdarzyć taka sytuacja i jeśli tak jak wówczas może to zadziałać 🙁 Natomiast jeśli bardzo Ci na tym zależy, to jak skończę projekt: https://kartydatascience.pl/ mogę Ci pomóc w rozgryzieniu tego 🙂
Bardzo fajny wpis, który na luzie pokazuje jak działają transformery. Jednak dla kompletności brakuje mi informacji jak taki wytrenowany transformer tłumaczy z polskiego na hiszpański, bo przecież chcemy mu podać tylko polskie zdanie 🙂
Opisane jest to na przykład w tym wpisie:
https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04
Hej Grzesiek!
dziękuję za informację. W sumie bardzo fajny pomysł by coś takiego dodać.
Mógłbym jeszcze spróbować dokładniej pokazać mechanizm uwagi, bo jest on matematycznie bardzo ciekawy.
Dopiszę na swoją listę i mam nadzieję, że znajdę kiedyś chwilkę by do tego wrócić 🙂
Ostatnio krucho z czasem. Coraz częściej przysypia mi się wieczorem czytając dzieciaczkom książeczeki razem z nimi 😉
Pozdrawiam,
Mirek