
– Tato, a czym Ty w ogóle się zajmujesz w pracy? – zapytała mnie ostatnio Jagódka.
– Od jakiegoś czasu głównie uczeniem maszynowym.
– A co to znaczy? – dopytywała.
– Pamiętasz Stefana, pieska cioci Natalki? Zawsze jest głodny. Możesz pomyśleć, że tak jak Ty karmisz Stefana, tak ja karmię maszyny danymi. Są w stanie bardzo dużo zjeść i moim zadaniem jest pilnować by miały co jeść. Jednak najważniejsze, aby jadły zdrowe jedzenie, a nie śmieciowe.
– Mam nadzieję, że te maszyny nie szczekają na Ciebie jak Stefan – zaśmiała się.
W internecie można znaleźć setki artykułów o tym, czym jest a czym nie jest uczenie maszynowe (ang. machine learning). Dla mnie najprostsza definicja to taka, że uczenie maszynowe to:
metody służące do karmienia maszyn danymi, aby na podstawie tych danych oraz własnych błędów poznały reguły rozwiązujące dany problem.
Można o tym myśleć jak o odwróceniu roli, którą wykonywałem przez wcześniejsze lata jako analityk danych, gdzie definiując reguły szukałem odpowiedzi.

Historia uczenia maszynowego
Jednym z pierwszych przykładów uczenia maszynowego jest projekt Arthura Samuela, który w latach 1952-1962 rozwijał program do szkolenia zawodników szachowych. To on pierwszy raz użył pojęcia „uczenie maszynowe” na konferencji w 1959 roku.
Arthur Samuel, 1959
Uczenie maszynowe daje komputerom możliwość „uczenia się” bez bycia konkretnie zaprogramowanym do danego zadania.
Później dość znanym przykładem był system Dendral z 1965 roku, który powstał na Uniwersytecie Stanforda w celu zautomatyzowania analiz i identyfikacji molekuł związków organicznych nieznanych wówczas chemikom.
Następnie przez kolejne dekady było dość spokojnie i cicho w zakresie uczenia maszynowego. Przeżywało ono swoje średniowiecze i zapomnienie. Do lat 90. było wykorzystywane głównie w prostych grach (np. w warcabach). Potem uczenie maszynowe było coraz częściej wykorzystywane przede wszystkim przez przeglądarki internetowe (Google, Yahoo) oraz wspomagało systemy anty-spamowe. Dopiero z początkiem 2010 roku upowszechniło się dzięki rozwojowi sieci neuronowych.

Dlaczego dopiero teraz? Wynika to głównie z tego, że obecnie mamy mnóstwo danych oraz dość tanią „technologię”. Czyli możemy karmić wieloma gigabajtami danych tanie komputery 🙂

Przykłady uczenia maszynowego
Tak jak wspomniałem wcześniej uczenie maszynowe najczęściej potrzebuje na wejściu dane oraz odpowiedzi.
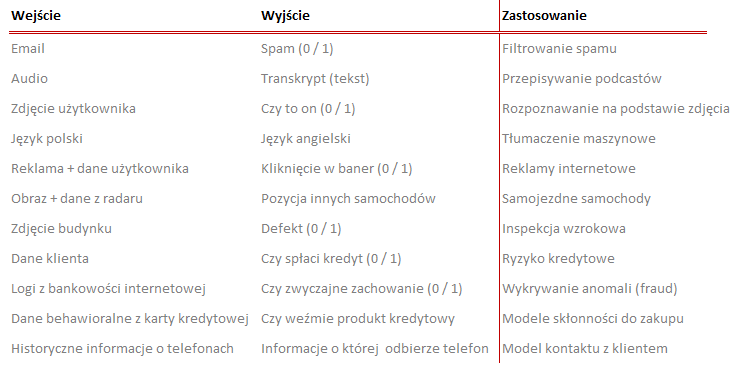
Przykłady można mnożyć w nieskończoność. Niemniej jednak chciałem Wam pokazać, że jeśli wydaje Wam się, że nie używacie uczenia maszynowego, to tylko Wam się wydaje. Jest ono obecne u Was na co dzień – chociażby jeśli używanie telefonu oraz aplikacji Google – czy to wyszukiwarki, poczty lub map.
Pamiętajcie również, że korzystając z takich narzędzi płacicie za nie własnymi danymi. Sam korzystam z nich ze względu na to, że bardzo ułatwiają mi życie, ale mam świadomość, jakiego typu informacje firmy pozyskują na temat mojego życia np. o geolokalizacji (moja pozycja X / Y na mapie):
- gdzie pracuję (8 h w jednym miejscu od poniedziałku do piątku),
- gdzie tankuję (co około 800 km jak jestem na stacji),
- gdzie przebywają moje dzieci (poranne odwożenie do żłobka i przedszkola oraz odbieranie po pracy),
- gdzie jadamy na mieście z żoną (restauracje z czasem oczekiwania),
- czy jeżdżę autem zgodnie z przepisami ruchu drogowego (czy prędkość jest ok),
- jak często chodzę do fryzjera (wizyta przez 30 min w salonie),
- itp. itd.
Mam nadzieję, że widzicie na ile sposobów można wykorzystać jeden rodzaj danych.
Jakie są rodzaje uczenia maszynowego?
Jak mogliście zauważyć jest mnóstwo rzeczy, które można rozwiązać za pomocą uczenia maszynowego. Najważniejsze jest, aby wiedzieć jakie dane mamy na wejściu i co chcemy osiągnąć. W zależności od problemu możemy wybrać odpowiedni rodzaj uczenia maszynowego, który chcemy dobrać. Można je podzielić na trzy główne rodzaje:

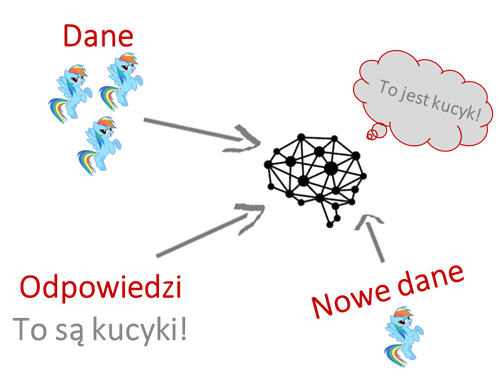
Uczenie nadzorowane (Supervised learning)
Jest to analogiczne do tego, jak uczy się Jagoda albo Otylka :). Dostają informacje, jak należy coś rozwiązać od rodziców (Ja i Elwira) albo od „cioć” ze żłobka lub przedszkola.
Jest to najczęściej wykorzystywany rodzaj uczenia maszynowego. Sam w pracy modelując obecnie ryzyko kredytowe klientów (czy spłaca kredyt) na wejściu mam zbiór cech opisujących klientów oraz informacje kto spłacił a kto nie (odpowiedź / etykiety / target). Właśnie dlatego, że uczenie nadzorowane jest nazwane „nadzorowanym”.
Przykładami takiego uczenia jest wszystko z punktu „Przykłady uczenia maszynowego” oznaczone jako 0/1. Ponadto inne wykorzystanie uczenia nadzorowanego to:
- zdjęcie rentgenowskie i rozpoznajemy czy pacjent jest chory na zapalenie płuc,
- tweet i rozpoznajemy sentyment czy jest obraźliwy,
- rozpoznawanie konkretnych twarzy (np. Mirka :)).
Uczenie nienadzorowane (Unsupervised learning):
Uczenie się bez nadzoru jest przeciwieństwem uczenia nadzorowanego. Czasami moje dziewczyny uczą się samodzielnie próbując odgadnąć pewne zależności. Czyli próbują dopasować pewne zależności bez prawidłowej odpowiedzi.
Przekładając to na modelowanie – na wejściu mamy same charakterystyki i nie narzucamy żadnych odpowiedzi czy coś jest np. dobre a coś złe. Algorytm ma na celu podczas procesu uczenia znaleźć samemu interesujące wzorce czy zależności. Po to jest to robione, aby potem człowiek (lub inteligentny algorytm) mógł wejść i zrozumieć nowo zorganizowane dane.

Przykładami mogą być:
- segmentacja klientów (algorytmy grupowania, które podzielą klientów na podgrupy),
- systemy rekomendacyjne (szukanie podobnych klientów i pokazywanie podobnych filmów / produktów),
- redukcja wymiarów (zredukowanie 100 cech do 10 innych wartości nie mówiąc jak).
Dlaczego ta dziedzina uczenia jest moim zdaniem bardzo ciekawym obszarem? Ponieważ większość danych na świecie jest nieoznaczona! Można w ten sposób analizować terabajty nieoznaczonych danych, aby je lepiej rozumieć, co może być źródłem potencjalnego zysku dla wielu branż.
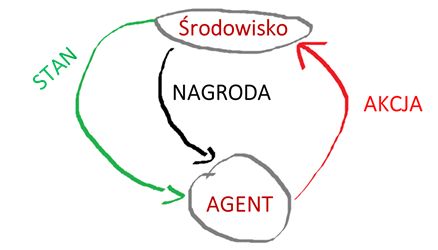
Uczenie ze wzmocnieniem (Reinforcement Learning)
Ten rodzaj uczenia jest z jednej strony bardzo ciekawy, ale z drugiej jest najtrudniejszy. W miarę łatwo można dostrzec różnicę pomiędzy uczeniem nienadzorowanym a nadzorowanym natomiast różnica między uczeniem ze wzmocnieniem jest bardziej mglista.
Pomyślcie, że dzieci mogą się uczyć czegoś samodzielnie podobnie jak w przypadku uczenia nienadzorowanego. Jednak może się coś wydarzyć, że zostaną ukarane i zrozumieją, aby czegoś nie powtarzać, np. dotknięcie garnka z gotującą się zupą. Nie ostrzegając ich (nie robiąc uczenia nadzorowowanego :)) po pierwszym dotknięciu zapamiętają, aby tego więcej nie robić.
W przypadku każdego problemu z uczeniem ze wzmocnieniem potrzebujemy agenta i środowiska oraz połączenia tych dwóch elementów za pomocą pętli informacji zwrotnej. Aby połączyć agenta ze środowiskiem w rzeczywistości dajemy mu zestaw określonych działań, które może podjąć. Te działania wpływają na środowisko, w którym jest osadzony. Aby połączyć środowisko z agentem, stale wysyłamy dwa sygnały do agenta: zaktualizowany stan i nagrodę (nasz sygnał wzmocnienia dla zachowania).
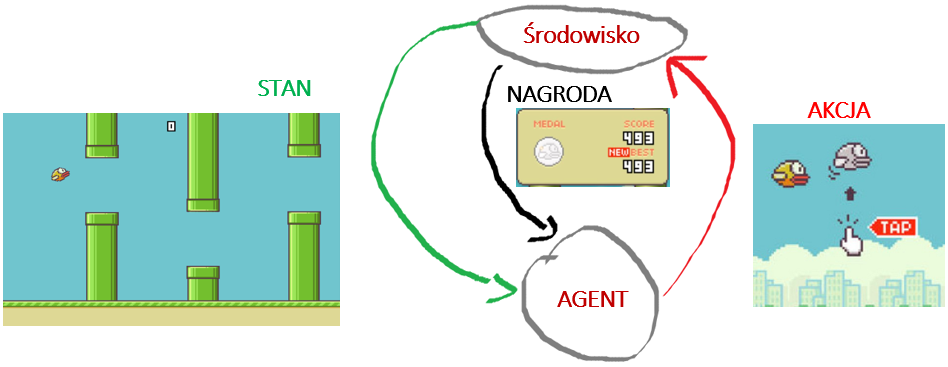
Aby jeszcze lepiej zrozumieć uczenie ze wzmocnieniem najlepiej przyjrzeć się przykładowi gry Agenta w Flappy Bird.
W grze Flappy Bird agentem jest nasz algorytm uczenia się, a środowiskiem jest sama gra. Nasz agent ma bardzo ubogi zestaw działań – przycisk odbicia. Zaktualizowany stan będzie screenem (klatką) z gry w miarę upływu czasu. Nagrodą jest każda ominęta przeszkoda, a naszym sygnałem nagrody będzie zmiana wyniku. Tak długo, jak połączymy wszystkie te elementy razem, będziemy przygotowywać scenariusz uczenia się w celu wzmocnienia gry i nauki jak najdalszego lotu.
Podsumowanie
Mam nadzieję, że teraz definicja uczenia maszynowego i jego rodzaje są jaśniejsze i bardziej zrozumiałe.
Chciałem na koniec pokazać Wam, że często jest mała granica i można podchodzić do problemów dwojako.
Weźmy na przykład wykrywanie fraudów w bankowości (wyłudzenia kredytów). Najczęściej podchodzi się do tego zagadnienia robiąc uczenie nadzorowane i mając informacje z przeszłości. Natomiast można spróbować innego podejścia i wykrywać anomalie grupując klienta w celu wyłapania takich zależności. Wówczas można mówić już o uczeniu nienadzorowanym.
Innym typem żonglowania może być w pierwszym kroku przygotowanie klasteryzacji klientów dla jakiejś części danych, a następnie dorzucenie tej informacji jako charakterystyki podczas budowy modelu już z wykorzystaniem uczenia nadzorowanego.
Chcę jeszcze podkreślić, że bardzo ważne jest, abyśmy wszyscy rozumieli, na czym polega uczenie maszynowe, nawet jeśli sami nigdy nie stworzymy systemu uczenia maszynowego. Nasz świat bardzo szybko się zmienia, a uczenie maszynowe staje się coraz bardziej powszechne we wszystkim, co nas otacza oraz z czego korzystamy na co dzień. Zrozumienie podstaw uczenia maszynowego pomoże nam poruszać się po tym świecie i pozwoli na lepsze rozumienie technologii, której używamy.
Pozdrawiam,

PS. Tutaj jeszcze super grafika, którą znalazłem z przykładami uczenia maszynowego:

Zdjęcie tytułowe: Pixaby



O rety! Ależ to Pan wspaniałe wytłumaczył! Właśnie dziś próbowałam wytlymaczyc zespołowi (komunikacja wewnętrzna) co to jest ML, bo facet na konferencji o komunikacji wewnętrznej nawijał im makaron na uszy. Trafił na grupę, która nie jest mocno zaawansowana w technologiach, danych i algorytmach. Spróbuję im to wytłumaczyć z Pańskimi przykładami. Dziękuję!
Pingback: Uczenie maszynowe co to: Kluczowe pojęcia i zastosowania - ᴘʀᴏᴍᴘᴛᴏᴡʏ 🤖
„Nagrodą jest każda przeleciana przeszkoda”. „Przeleciana”? Dobra, litościwie pominę z czym mi się to kojarzy ale powinno być zwykłe „ominięta”.
W sumie można to zmienić z „przeleciana” na „ominięta” :D, już poprawione 😉
System Dendral z 1695… mała literówka się wkradła ;D
Pozdrawiam
dziekuje :*. Już poprawione 🙂
A będą jakieś podstawy w Python?
Hej Tedi, nie myślałem o tym, ponieważ jest sporo stron i naprawdę dobrych blogów o samym Pythonie. Ale może dodam artykuł z których bibliotek sam najczęściej korzystam i z czym warto się zapoznac 🙂
Pierwszy raz tu zajrzałem i jestem zaskoczony i zdumiony. Lekkość i trafność opisów i wielki dar dydaktyczny. Gratuluje i staję sie Twoim fanem.
rzadko się zdarza aby polski autor pisał w tak przystępny sposób artykuły o ML. Super, zmuszony przez klienta do wejścia w ten temat w kontekście wyszukiwania anomalii w szeregach czasowych moje zrozumienie tematyki rośnie 🙂
dziękuję za miłe słowa 🙂
Pingback: 18 inspirujących linków, które powinien znać każdy fan data science i uczenia maszynowego. - Blog IT-Leaders
Pingback: Jak działa regresja liniowa? I czy warto ją stosować? - Mirosław Mamczur
Pingback: 18 inspirujących linków, które powinien znać każdy fan data science i uczenia maszynowego - Mirosław Mamczur
Bardzo fajny blog i info przekazane w przystępny sposób 😉
Dzięki Mika! Miłego dnia życzę
Pingback: Czym jest i jak się uczy sztuczna sieć neuronowa? - Mirosław Mamczur