
– Tato, ilu rybakom pomogłeś w tym roku? – spytała zaniepokojona Jagódka
– Jakim rybakom córeczko?
– Bo mówiłeś kiedyś, że robisz sieci. No a rybacy używają sieci.
– Hihi – uśmiechnąłem się. Pozwól, że opowiem Ci pewną historię…
Człowiek od zarania wieków inspiruje się naturą. Ludzie obserwowali przez stulecia jak ptaki latają i marzyli by również wzbić się w powietrze jak one. Początki nie były łatwe.
Natomiast ludzie się nie poddawali i próbowali dalej. I dzięki temu powstały samoloty, które w tym momencie potrafią z zawrotną prędkością latać tysiące kilometrów przewożąc setki osób. I mimo, że samoloty były inspirowane ptakami to ich obecnie już nie przypominają – nie muszą machać skrzydłami by lecieć.

Podobnie ludzie zainteresowali się ludzkim mózgiem, który inspirował ich to tworzenia inteligentnych maszyn. To pomogło stworzyć sztuczne sieci neuronowe (ang. artificial neutral networks), które pierwszy raz zostały przedstawione w 1943 roku przez neurofizjologa Warrena McCullocha i matematyka Waltera Pittsa.
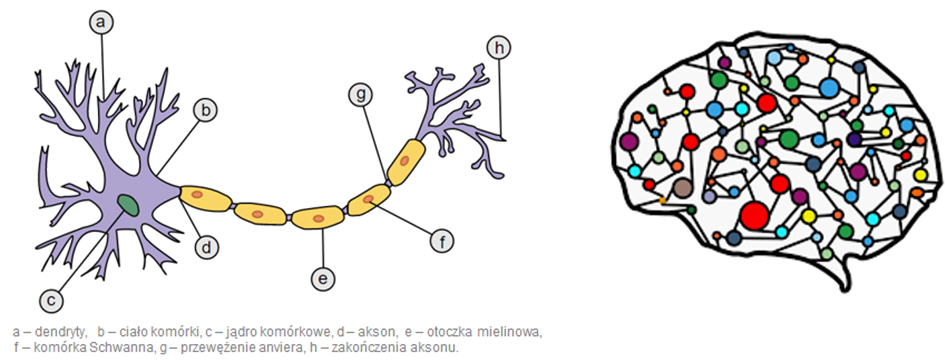
Czym jest neuron?
Wymienieni uczeni zaproponowali bardzo prosty model matematyczny, który nazwano sztucznym neuronem (ang.neuron). Miał on co najmniej jedno wejście binarne (0/1 albo prawda/fałsz) i tylko jedno binarne wyjście. Wyjście zostaje uaktywnione jeśli osiągnięta została określona ilość wejść.

Taki układ jest niewiele lepszy od zwykłych bramek logicznych. Twórcy pokazali, że nawet dla tak uproszczonego modelu możliwe jest dla sieci neuronowej (mnóstwo neuronów połączonych ze sobą) rozwiązanie dowolnego zagadnienie logicznego.
Czym jest perceptron?
Aktualnie stosuje się inny rodzaj sztucznych neuronów zwany perceptronem, który daje odpowiedź w formie liczby rzeczywistej.
Pojedynczy perceptron jest jedną z najprostszych sieci neuronowych zaproponowaną przez Franka Rosenblatta w 1957 roku. Frank wziął prosty sztuczny neuron binarny i go odrobinę zmodyfikował:
- Na wejściu i wyjściu zamiast wartości binarnych mogą być liczby. Będziemy je nazywać węzłami.
- Połączenia węzłów mają nadaną wagę. Mówiąc, że uczymy sieć tak naprawdę szukamy najlepszych wag.
- Wartość wyjściowa w węźle składa się z dwóch części: sumy wartości z warstw poprzednich pomnożonej przez wagi (będziemy nazywać je blokiem sumującym) oraz nałożonej na tą sumę funkcji aktywacji. Zadaniem funkcji aktywacji jest przede wszystkim przekształcenie wartości w węźle po to, aby wprowadzić do modelu nieliniowość, dzięki czemu możemy nauczyć model wyłapywać mniej intuicyjne zależności.

Wspomniany perceptron to najprostsza sieć neuronowa złożona z jednego sztucznego neuron.

Prosty przykład perceptronu
Dobra, zacznijmy od przykładu działania najprostszej sieci neuronowej (czyli perceptron) aby rozwiać Wasze wątpliwości jak to działa.
Chcemy przygotować prostą sieć, która rozwiąże nam problem wyceny nieruchomości. Załóżmy, że na wejściu mamy trzy informacje:
- liczba pokoi,
- metraż,
- stała.
Teraz nadajmy jej losowe wagi przypisane do naszych wejściowych charakterystyk. Niech odpowiednio wagi przyjmą wartości 1.000, 50 oraz 1. Wówczas wycena naszej nieruchomości wyniesie 55 tys. mimo iż w rzeczywistości (na luty 2020) nieruchomość wyceniana jest na 515 tys.
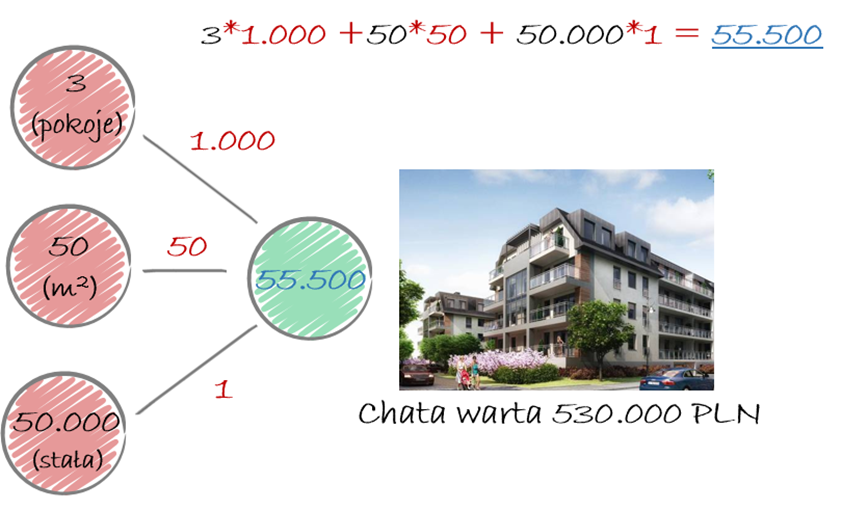
Teraz modyfikujemy wagi w naszej sieci neuronowej.
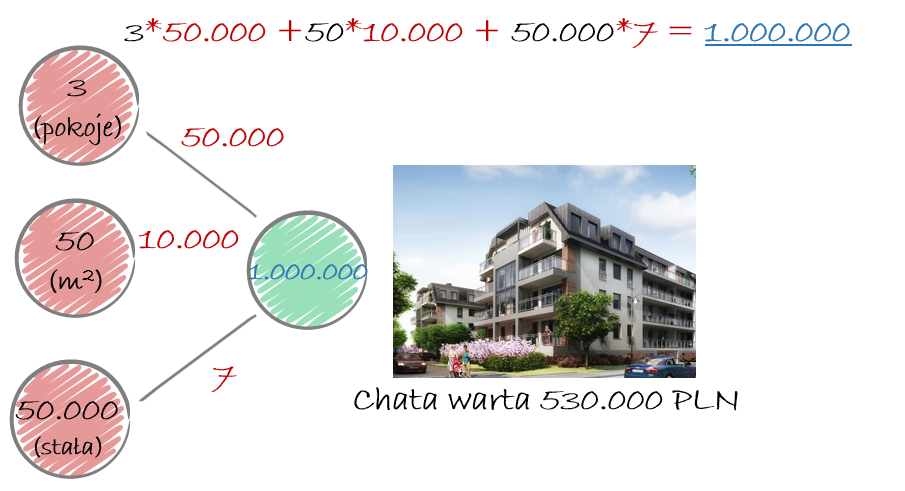
Tym razem wagi są za duże. Spróbujmy jeszcze raz.

Uff… udało się co do złotówki. I o to właśnie chodzi w sieciach, by dobrać optymalne wagi. Tylko, że nie robimy tego dla pojedynczej obserwacji a dla całego zbioru danych 🙂 Mam nadzieję, że jest to jasne teraz.

Czym jest sieć neuronowa?
Jak sobie możecie wyobrazić to jeden sztuczny neuron ma niewielkie możliwości rozwiązywania bardziej skomplikowanych problemów. Natomiast wiele neuronów można połączyć w warstwy, gdzie jedna warstwa przekazuje wyniki kolejnej warstwie. W ten sposób można powiedzieć, że budujemy pewien rodzaj „mózgu”, który będzie przekazywał impuls pomiędzy neuronami, aby otrzymać odpowiedź na nasz problem. Powtarzając wielokrotnie tą czynność połączenia między neuronami się wzmacniają i nasza sieć zaczyna się uczyć.
Poniżej przygotowałem przykładową sieć neuronową:
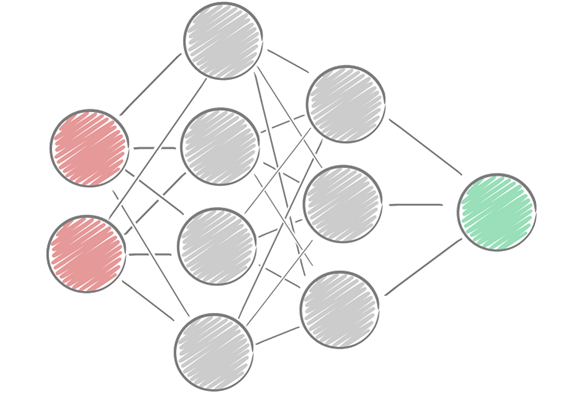
Sieci neuronowe składa się z trzech warstw:
- Warstwa wejściowa / input layer (czerwone neurony – kółeczka) – zbiera dane i przesyła je dalej (każdy neuron z warstwy wejściowej przesyła dane do każdego neuronu w warstwie ukrytej)
- Warstwa ukryta / hidden layer (szare neurony) – są to stany pośrednie. Tutaj przede wszystkim zachodzi proces uczenia się i szukana liniowych i nieliniowych zależności. Może być wiele warstw ukrytych. Im sieć ma więcej warstw ukrytych tym może znaleźć głębsze zależności.
- Warstwa wyjściowa / output layer (zielone neurony) – zwracany jest wynik.
Jeśli jak w powyższym przykładzie wszystkie warstwy skonstruowane są tak, że każdy węzeł poprzedniej warstwy jest połączony z każdym węzłem następnej warstwy, to taką sieć nazywamy perceptronem wielowarstwowym (ang. Multi Layer Perceptron MLP).
Jak się ma sieć neuronowa do głębokiego uczenia?
W wielu artykułach możecie znaleźć pojęcie głębokiego uczenia (ang. deep learning) związanego z uczeniem maszynowym. Jak już zauważyliście z powyższego schematu sieć neuronowa może posiadać wiele warstw ukrytych. Tak naprawdę zwiększając liczbę warstw ukrytych można powiedzieć, że wchodzimy w uczenie głębokie. Ile powinno być tych warstw aby nazwać uczenie głębokim? Widziałem wiele artykułów z różnymi liczbami. Dlatego nie chciałbym podawać konkretnej wartości. Najważniejsze byście zapamiętali, że sieć z więcej niż jedną warstwą ukrytą można nazwać głęboką :).
Do czego najlepiej nadaje się sieć?
Sieci wyśmienicie radzą sobie z nieliniowymi i skomplikowanymi problemami. Najczęściej wykorzystywane są do danych, które nie mają uporządkowanej i prostej struktury. Dlatego przede wszystkim używa się ich do problemów związanych z przetwarzaniem:
- obrazu,
- dźwięku,
- tekstu,
- logów.
Natomiast można jej również jak najbardziej użyć do prostszych problemów. Chociażby fajnym przykładem może być to, że w bankowości do modelowania ryzyka od lat ’90 używana była regresja logistyczna. Zauważcie proszę, że sieć bez żadnych warstw ukrytych z funkcją aktywacji sigmoid jest tak naprawdę taką regresją logistyczną.
Jak się uczy sieć neuronowa?
Najbardziej rozpowszechnione są dwa rodzaje uczenia sieci.
Pierwszym z nich jest tzw. feed forward. Polega na tym, że na początku losujemy wagi. Następnie zgodnie z wcześniejszym obrazkiem z sieci idziemy od lewej do prawej. Wagi możemy poprawić aby dostać lepszy wynik.
Natomiast można wykorzystać wyższą matematykę i za pomocą gradientów i reguły łańcuchowej zacząć wracać w naszej sieci do samego początku rozkładając odpowiednio wartości błędów i próbując poprawić wagi. Ten proces nazywamy propagacją wstęczną (ang. back propagation / backprop).
Idea działania propagacji wstecznej
Zobaczmy wspólnie jak to działa na przykładzie. Pamiętacie jeszcze przykład z mieszkaniem we Wrocławiu? Skomplikujmy przykład i dodajmy dwie warstwy ukryte: pierwszą z 3 neuronami a drugą z dwoma. Charakterystyki zamieńmy na wartości X1, X2 oraz X3 a wagi oznaczmy odpowiednio jak na obrazku:

Przepuszczamy dane przez naszą sieć z inicjalnymi wagami i możemy wyliczyć naszą predykcję (niebieskie y z daszkiem 🙂 )

Ideą algorytmu propagacji wstecznej jest aktualizacja wag na podstawie wartości oczekiwanej oraz wyjścia z sieci neuronowej. Zatem wyliczamy nasz błąd i funkcję straty.
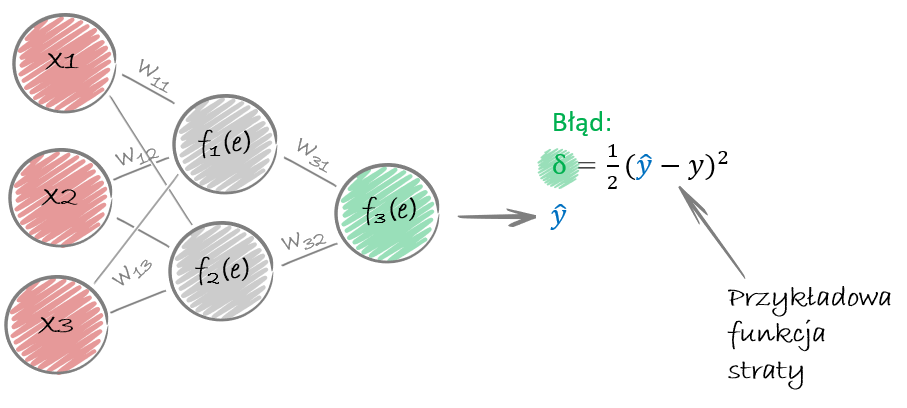
Dla warstw pośrednich wyznaczenie błędu odbywa się poprzez przemnożenie błędu wyjściowego z sieci przez odpowiednie wagi. Szczegóły na przykład można poszukać tutaj.

I teraz można powiedzieć, że „dzieje się magia”.

Mając już określony błąd sygnału dla każdego neuronu, możemy przystąpić do modyfikacji wag jego połączeń wejściowych. Aktualizacja wag następuje poprzez minimalizację błędu (pochodna funkcji aktywacji). Uwzględnia również szybkość uczenia się (parametr ) oraz wejście do neuronu.

Uff…dobrnęliśmy do końca.
Uspokoję Was – na szczęście nie musimy tego liczyć! Odpowiednie biblioteki napisane przez mądrych ludzi zrobią to za nas :).

Czym jest architektura sieci?
Podczas budowania modeli drzewiastych jak np. XGBoost najwięcej czasu w pracy poświęcamy na przygotowanie danych. Wynika to z tego, że jest mnóstwo fajnych bibliotek, które pomagają szybko nam zoptymalizować wszystkie hiperparametry w modelu.
W przypadku sieci jest to odrobinę bardziej skomplikowane. Tutaj można pomyśleć, że naszymi hiperparametrami są:
- liczba warstw ukrytych,
- rodzaje warstw,
- liczba neuronów w warstwach,
- wartość funkcji aktywacji w poszczególnych warstwach,
- dobór początkowych wag naszej sieci,
- itp…
Również tutaj można wykorzystać mechanizmy z baysowską optymalizacją, jednak czas uczenia sieci jest znacznie dłuższy. W tym miejscu przydaje się doświadczenie, które inżynierowie danych nabierają wraz z kolejnymi projektami oraz ucząc się od osób z większym doświadczeniem. Natomiast już wielcy gracze mówią otwarcie, że pracują nad automatycznym budowaniem architektury. Jestem bardzo ciekawy, w którym kierunku to pójdzie. Wyobrażam siebie, że maksymalnie za 5 lat będą już biblioteki, które będą w tle same dobierać optymalną architekturę do naszego zagadnienia i dostarczonych danych i z czasem same będą się douczać oraz rozszerzać swoją architekturę wraz z większą liczbą danych.
Chcesz lepiej poczuć sieć i dobór architektury?
Polecam przykład udostępniony przez tensorflow. Możesz sterować liczbą danych wejściowych, funkcjami aktywacji, liczbą neuronów itp. itd.
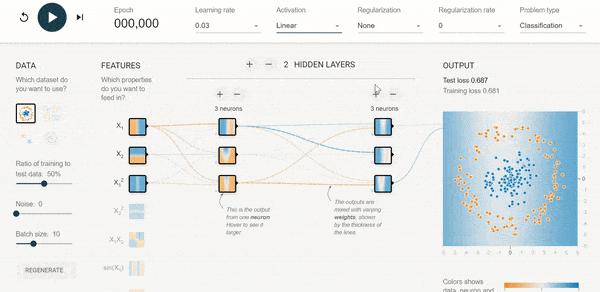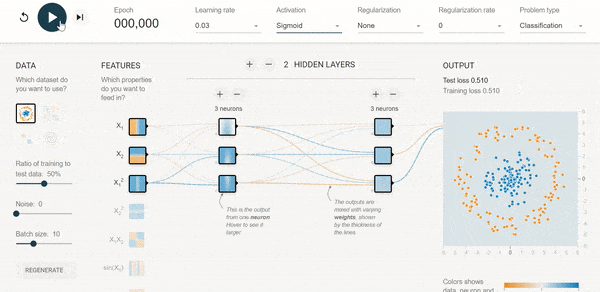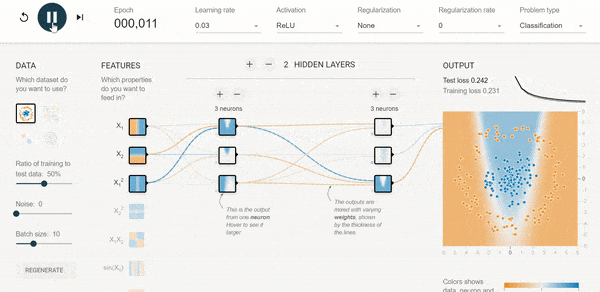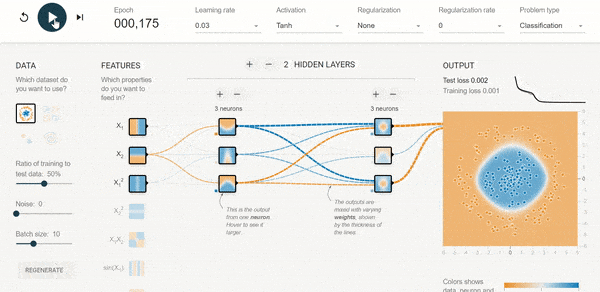
Tutaj LINK: https://playground.tensorflow.org/
Podsumowanie
Powyżej omówiłem przykłady najprostszych sieci neuronowych czyli tzw. perceptronów i wielowymiarowych perceptronów, które przekierowują impuls w prawo. Istnieje mnóstwo innych bardziej złożonych sieci, które z czasem będę opisywać na blogu.
Trzymajcie się ciepło!

Obraz Quang Nguyen vinh z Pixabay



W przykładzie: Prosty przykład perceptronu ma Pan określone wejście jako „Stała”, czym ona jest? i dlaczego w tym przykładzie na wejściu Pan ustawił ją na 50 000 ? To jest „wklad wlasny” w nieruchomość? Jak to należy interpretować?
Dzień dobry, w tekście jest wskazane, że „Aktualizacja wag następuje poprzez minimalizację błędu (pochodna funkcji aktywacji). Uwzględnia również szybkość uczenia się (parametr ) oraz wejście do neuronu.” Czy w związku z tym w_32 nie powinno jakoś odnosić się do funkcji f_2(2)?
Jeszcze jedna malutka uwaga:) chyba zamiast x_1 wszedzie, powinno byc x_1, x_2, x_3:)
Pozdrawiam!
Dziękuję :* Poprawione 😀
Pozdrawiam serdecznie!
Czesc! Wydaje mi sie, ze waga w13 jest w zlym miejscu, co jest troche mylace. Czy nie powinna byc przypisana takze do f_1(e)?
Pozdrawiam!
Cześć Kasiu!
bardzo dziękuję Ci, że uważnie przeczytałaś całość. Jak najbardziej masz racje. Poprawiłem na wizualizacjach by było ok 😉
Pozdrawiam serdecznie!
Cześć, dzięki za ten artykuł.
Nie rozumiem jednej rzeczy. W perceptronie dodajesz bias, a w MLP już go nie widzę. Ma go nie być kiedy jest więcej niż 1 neuron?
w sumie można byłoby go tam dodać. Odnośnie MLP to zależy od tego jak go implementujesz. A w ramach wyprowadzania wzorów jego nie dałem by było prościej.
W kwestii okreslania meta-parametrow sieci (liczba layerow itp.) polecam ksiazke: https://www.amazon.com/Automated-Machine-Learning-Challenges-Springer/dp/3030053172
Art. Czym jest sieć rozdział Chcesz lepiej poczuć sieć: jest „tensforflow” powinno być „tensorflow”. Pozdrawiam
Serdecznie dziękuję! Już poprawione 🙂