
Histogram (ang. histogram :)) jest jednym z najbardziej popularnych i znanych wykresów statystycznych. Histogram jest wizualizacją rozkładu danych liczbowych w zadanych podziałach badanej zmiennej. Każdy słupek histogramu przedstawia częstotliwość w danych danego przedziału, czyli ile razy wystąpiły. Poniżej prosty przykład przedstawiający długość życia dla krajów na świecie. Wziąłem wszystkie lata, by było więcej obserwacji do prezentacji histogramu.
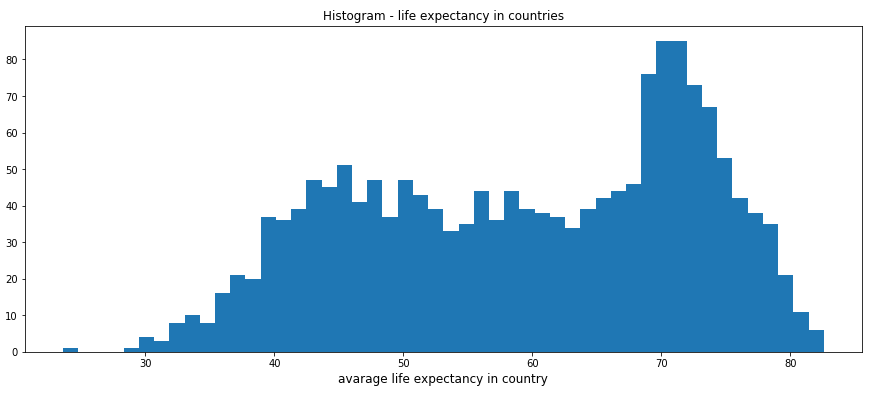
Możecie zauważyć, że histogram złożony jest z prostokątnych słupków, które przedstawiają liczebność obserwacji (pionowa oś Y) w danym przedziale (pozioma oś X).
Histogramy pomagają w wizualny sposób:
- przedstawić, gdzie koncentrują się wartości,
- pokazać jakie są skrajności,
- pokazać czy występują jakieś luki.
Są również przydatne do przybliżenia rozkładu prawdopodobieństwa. Dzięki temu od razu możesz wykryć błędy w danych.
Kształt histogramu może być bardzo różny w zależności od liczby przedziałów. Natomiast pamiętajcie, by wypróbować różne warianty przed wyciągnięciem jakichkolwiek wniosków. Dla przykładu tutaj są te same dane co wyżej, ale dla różnej liczby przedziałów (bins):
fig, axs = plt.subplots(ncols=3, nrows=3, figsize=(12, 8))
index = 0
axs = axs.flatten()
for i in [5,10,20,30,40,50,60,80,100]:
axs[index].hist(x="lifeExp", data=df, bins=i)
axs[index].set_title(f'bins={i}')
index = index + 1
plt.tight_layout()
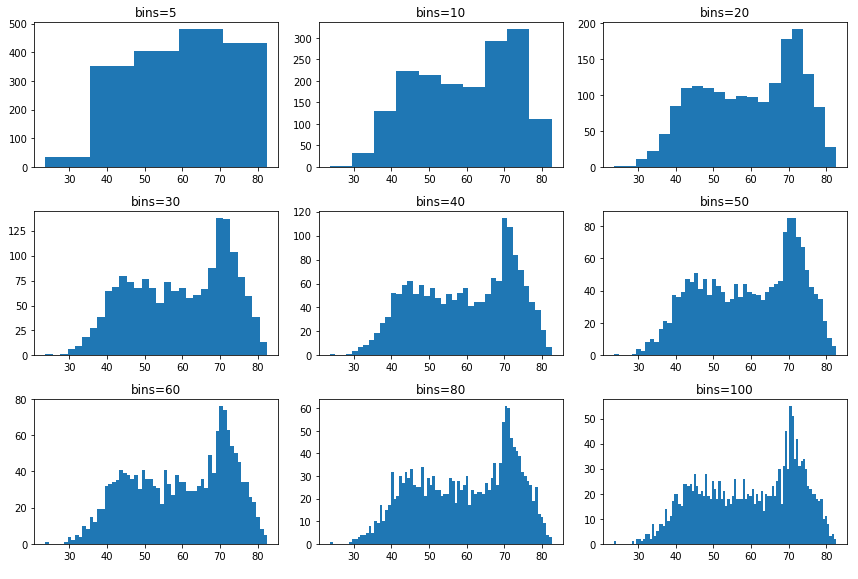
Jestem pewien, że widzicie, że wykres dla większej liczby przedziałów jest bardzo podobny do wykresu gęstości. W przypadku porównania kilku rozkładów można dodać je na tej samej osi i używając przezroczystości.
Częstą odmianą histogramu jest też histogram lustrzany: umieszcza on dwa histogramy twarzą w twarz w celu porównania ich rozkładu. Albo możesz wykorzysta do tego wykres skrzypcowy.
Najczęstsze błędy:
- Bardzo często histogram jest mylony z wykresem kolumnowym, który podaje wartość dla każdej grupy. Tutaj mamy tylko zmienną numeryczną i rysujemy jej rozkład.
- Jeśli nie spróbujesz przetestować różnej liczby przedziałów (ang. bins) możesz pominąć w niektórych przypadkach istotne informacje
- Nigdy nie próbuj dawać różnych rozmiarów przedziałów – nie chcemy manipulować danymi 🙂
- Staraj się nie porównywać więcej niż 3 grup na histogramie by nie zaciemniać obrazu
Histogram w Python
Użyjmy danych z średnim wiekiem życia w krajach. W powyższym artykule przygotowałem proste wykresy w bibliotece matplotlib a teraz wykorzystamy dla odmiany seaborn.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
url = 'https://raw.githubusercontent.com/plotly/datasets/master/gapminderDataFiveYear.csv'
df = pd.read_csv(url)
plt.figure(figsize=(10,5))
fig = sns.distplot(a=df["lifeExp"], hist=True, bins=25, kde=False)
fig.set(title='Histogram - life expectancy in countries');
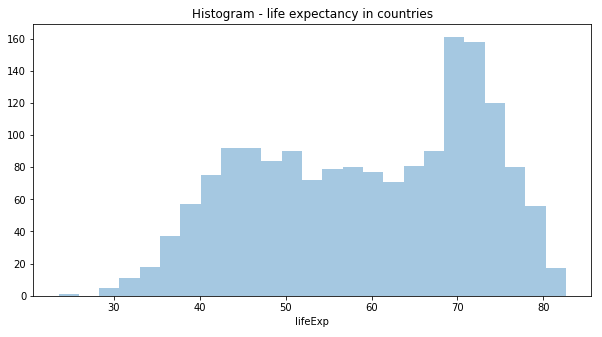
Bardzo prosto na podstawie jednego parametru kde można dodać linię z gęstością:
plt.figure(figsize=(10,5))
fig = sns.distplot(a=df["lifeExp"], hist=True, bins=25, kde=True)
fig.set(title='Histogram - life expectancy in countries');

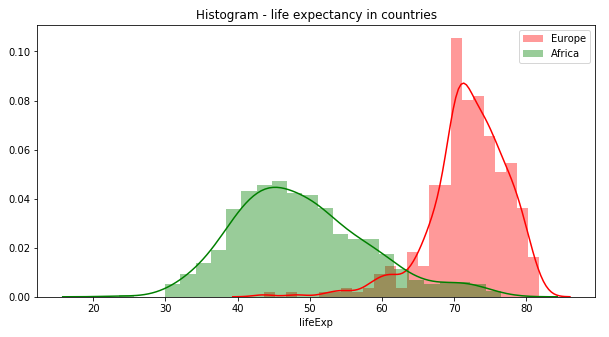
Poniżej jeszcze przykład nałożenia dwóch histogramów na jeden wykres:
plt.figure(figsize=(10,5))
fig = sns.distplot(a=df[df['continent']=='Europe']["lifeExp"],
hist=True, bins=25, kde=True, color="red",
label='Europe')
fig = sns.distplot(a=df[df['continent']=='Africa']["lifeExp"],
hist=True, bins=25, kde=True, color="green",
label='Africa')
fig.legend()
fig.set(title='Histogram - life expectancy in countries');
Życzę Wam udanego rysowania histogramów 🙂
Pozdrawiam serdecznie,




Kolejny świetny artykuł!
Pozdrawiam, Mateusz.