
W poprzednim artykule postarałem się w jasny sposób wyjaśnić czym jest sieć neuronowa oraz w jaki sposób się uczy. Teraz pokażę Wam na przykładzie jak należy przygotować dane a następnie jak można przygotować własną sieć wykorzystując bibliotekę tensorflow.
Zbiór danych
Sieci neuronowe można wykorzystać do rozwiązania problemów w wielu aspektach. Natomiast w oparciu o moje doświadczenie najlepiej radzą sobie one z nazwijmy to „brudnymi” danymi lub niestrukturyzowanymi: logi, obrazy, głos, surowe dane transakcyjne itp. itd. W przypadku, gdy mamy już zestaw gotowych charakterystyk to bardzo dobrym rozwiązaniem jest wykorzystanie algorytmów z dziedziny wzmocnienia gradientowego takie jak: XGBoost, CATboost czy LightGBM.
Aby lepiej poznać sieci dla przykładu wykorzystajmy znany zbiór danych Fashion-MNIST przygotowany przez zespół Zalando. Składa się on z obrazów oraz przypisanego do nich opisu garderoby. Zbiór treningowy ma 60.000 obserwacji a testowy 10.000.
Troszeczkę Was rozczaruję, to nie będą stroje w stylu pokazów Victoria Secret 🙁

# wczytanie potrzebnych bibliotek
import tensorflow as tf
#wczytanie danych
fashion_mnist = tf.keras.datasets.fashion_mnist
(X_train, y_train), (X_val, y_val) = fashion_mnist.load_data()
print(f'Zbiór uczący: {X_train.shape}, zbiór walidacyjny: {X_val.shape}')

Naszą cechą jest obraz, który jest tabelą w NumPy w rozmiarze 28 na 28 pikseli. Wartości w tej macierzy przyjmują wartość od 0 do 255 co odpowiada wartościom kolorów w notacji RGB (Red Green Blue).
import matplotlib.pyplot as plt
plt.figure(figsize=(7,7))
plt.imshow(X_train[0], cmap=plt.cm.binary)
plt.colorbar()
plt.show()

Możecie sobie to wyobrazić w ten sposób, że każdemu pikselowi odpowiada konkretny odcień szarości.
def plot_digit(digit, dem=28, font_size=8):
max_ax = font_size * dem
fig = plt.figure(figsize=(10,10))
plt.xlim([0, max_ax])
plt.ylim([0, max_ax])
plt.axis('off')
for idx in range(dem):
for jdx in range(dem):
t = plt.text(idx*font_size, max_ax - jdx*font_size,
digit[jdx][idx], fontsize=font_size,
color="#000000")
c = digit[jdx][idx] / 255.
t.set_bbox(dict(facecolor=(c, c, c), alpha=0.5,
edgecolor='#f1f1f1'))
plt.show()
plot_digit(X_train[0])

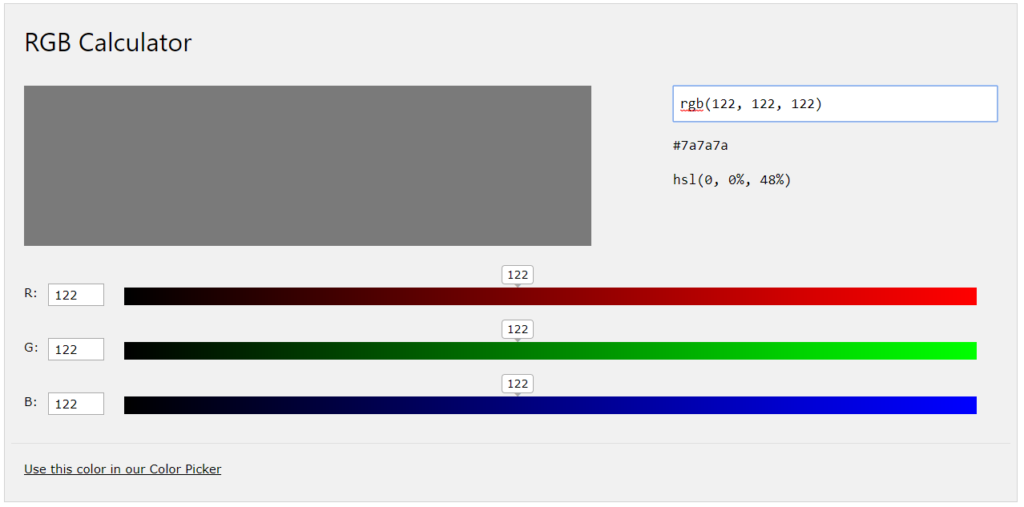
Wartość liczbowa piksela ma odpowiednik w skali RGB, np. wartość 0 w notacji RGB (0, 0, 0) to kolor czarny a 255 to kolor biały. Pośrednie wartości to są odcienie szarego. Poniżej dla przykładu odcień dla wartości 122:

Natomiast naszą kategorią, którą będziemy przewidywać jest zbiór liczb całkowitych od 0 do 9, które odpowiadają klasie ubrań przedstawionych na obrazkach:

Poniżej pierwsze 40 elementów z naszego zbioru:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
plt.figure(figsize=(14,10))
for i in range(40):
plt.subplot(5, 8, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train[i]])
plt.show()

Przygotowanie danych
Sieć neuronowa musi mieć poprawnie przygotowane dane. Jedną z ważniejszych zasad jest, że dane wejściowe muszą mieć taki sam rozmiar. Zatem w przypadku zdjęć odpowiednio się je obcina do takiej samej wielkości lub stosuje się inne metody. W przypadku wrzucania danych tekstowych należy również odpowiednio obciąć zbyt długie sekwencje do krótszej długości, a te które były zbyt krótkie uzupełnić np. zerami.
W naszym przypadku nie mamy problemu, ponieważ zbiór jest już przygotowany i każda obserwacja ma na wejściu obraz składający się z 28 na 28 pikseli czyli posiada ten sam rozmiar. Inaczej mówiąc każdy piksel jest osobną cechą, czyli tak jakbyśmy mieli 784 (28 x 28) charakterystyk opisujących nasz ubiór, który chcemy przewidzieć.
Parametry naszej sieci neuronowej najczęściej są inicjowane za pomocą niewielkich liczb losowych. Czasami może się okazać, że skonstruowana sieć neuronowa może niezbyt dobrze radzić sobie w przypadkach, gdy wartości cech są znacznie większe. Pamiętajmy też, że wejście do kolejnych węzłów to waga przemnożona przez wartość i nałożona na to funkcja aktywacji.

Stąd można wnioskować, że jeśli charakterystyki wejściowe mają podobną skalę wówczas znacznie ułatwimy naszej sieci przygotowanie predykcji. Dlatego dobrą praktyką jest przygotowanie standaryzacji cech. Najprościej wykorzystać wbudowane klasy z biblioteki scikit-learn.
Natomiast w naszym przypadku (gdzie mamy wartości z zakresu od 0 do 255) wystarczy podzielić liczby przez 255 i będziemy mieć dane z przedziału [0 – 1].
X_train = X_train.astype('float32') / 255.0
X_val = X_val.astype('float32') / 255.0
Dane do trenowania mamy przygotowanie. Teraz zajmijmy się przygotowaniem zbioru objaśnianego (y). Jak wspomniałem wcześniej naszym zadaniem jest przewidzenie 10 klas. Wobec tego naszym celem jest przewidzenie prawdopodobieństwa dla każdej z tych klas. Wykorzystajmy jeszcze wbudowane funkcje do kodowania „One Hot” (na język polski możemy to przetłumaczyć mniej więcej jako „gorącojedynkowy” :)).
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train, len(class_names))
y_val = to_categorical(y_val, len(class_names))
Możecie zobaczyć, że teraz przerobiliśmy zbiór na One Hot Encoding:

Bierzmy się za pierwszą architekturę.

Pierwsza architektura
Tak jak ostatnio wyjaśniałem sieć neuronowa składa się z warstwy wejściowej, ukrytych i wyjściowej. Można powiedzieć, że jest prawie nieskończona liczba możliwości jaką można dobrać dla każdego przypadku.
Wiele osób z dużym doświadczeniem w zakresie uczenia głębokiego mówi, że dobór odpowiedniej architektury to sztuka.
Istnieją dwa interfejsy API do definiowania modelu w Keras:
- sekwencyjny (Sequential model API) – jest prostszy, składa się z kolejnych warstw,
- funkcjonalny ( Functional API) – jest odrobinę bardziej skomplikowany, ale dzięki temu można składać bardziej złożone modele z wieloma wejściami czy wyjściamy, sklejać w locie czy współdzielić warstwami.
My wykorzystamy pierwszy ze sposobów.
from tensorflow.keras.models import Sequential
model = Sequential()
Teraz możemy do naszego modelu poprzez komendę add dodawać kolejne warstwy.
Zacznijmy od tego, że na wejściu model otrzymuje macierz dla każdej obserwacji 28 x 28. Wobec tego spłaszczmy ją do pojedynczego wektora 1 x 784
from tensorflow.keras.layers import Flatten, add
model.add(Flatten(input_shape=(28, 28)))
Pierwsza warstwa zawsze musi posiadać parametr input_shape, który mówi o tym jakie dane dostanie sieć neuronowa na początku.

Definiowanie pierwszej warstwy ukrytej
Jak pamiętacie warstwy gęste odpowiadają za poziom skomplikowania sieci. Im trudniejsze zagadnienie do zamodelowania tym warstw powinno być więcej i bardziej skomplikowane.
Dodając warstwy ukryte należy odpowiedzieć sobie na kilka pytań:
- ile powinno ich naszym zdaniem być,
- ile powinny zawierać neuronów,
- jaką powinny mieć funkcję aktywacji.
Im więcej neuronów jest na jednej warstwie, tym większe możliwości będzie miała nasza sieć neuronowa w zakresie rozwiązywania skomplikowanych problemów. Jednak zawsze jest coś kosztem czegoś. Zbyt duża liczba jednostek będzie mogła prowadzić do przetrenowywania sieci oraz dłuższego czasu jej wyliczenia.
Na początku dodajmy tylko jedną warstwę ukrytą składającą się z 128 neuronów i funkcji aktywacji ReLU (ang. rectified linear unit). Jest to najbardziej znana i najczęściej stosowana funkcja w przypadku warstw ukrytych.

Jak widać w powyższym wzorze: jeśli suma ważonych elementów wchodzących do neuronu jest większa niż 0 wówczas funkcja aktywacji po prostu zwraca tą wartość. W wypadku wartości ujemnych funkcja ReLU zwraca 0.
from tensorflow.keras.layers import Dense
model.add(Dense(128, activation='relu'))
W naszym przypadku w pierwszym podejściu definiujemy tylko jedną warstwę ukrytą. Oczywiście tak jak w przypadku liczby neuronów im więcej warstw ukrytych tym więcej nasza sieć neuronowa będzie mogła się nauczyć kosztem wydłużenia czasu lub overfittiniem. Powyżej zastosowałem najprostszą warstwę gęstą (dense), dla której wszystkie jednostki poprzedniej warstwy są połączone ze wszystkimi w następnej.
Definiowanie warstwy wyjściowej
Ostatnia warstwa, nazywana warstwą wyjściową, powinna mieć zdefiniowaną liczbę neuronów zależną od tego co przewidujemy. W naszym przypadku chcemy przewidzieć 10 klas, stąd przyjmiemy liczbę neuronów równą 10.
Oprócz tego należy zdefiniować strukturę funkcji aktywacji naszej warstwy wyjściowej. To jaką przyjmujemy funkcję aktywacji w dużym znaczeniu zależy od tego co chcemy prognozować. Przykładowo dla:
- klasyfikacji binarnej najlepiej przyjąć funkcję aktywacji o kształcie „S”,
- klasyfikacji wielowymiarowej najczęściej stosowana jest znormalizowana funkcja wykładnicza softmax,
- przypadku regresji nie ma potrzeby nakładać funkcji aktywacji.
W naszym przykładzie jest 10 klas więc użyjemy softmax. Dzięki temu otrzymamy na wyjściu tablicę składającą się z 10 wartości dla naszej obserwacji sumujących się do 1. Zatem te 10 wartości można traktować jako prawdopodobieństwa, że nasza obserwacja należy do jednej z 10 klas.
model.add(Dense(10, activation = 'softmax'))
Kompilacja modelu
Kompilatorem nazywamy program służący do automatycznego tłumaczenia kodu napisanego przez nas na język, który będzie rozumiany przez maszynę przeliczającą naszą sieć.
W tym kroku są jeszcze przed nami postawione dwa ważne zadania.
Pierwsze z nich to określenie funkcji straty, czyli funkcji która będzie sprawdzać jak nasza prognoza z sieci myli się od prawdziwej wartości. W tym miejscu najistotniejszy jest rodzaj problemu, który mamy. Najczęściej polecane są tutaj poniższe propozycje:
- dla klasyfikacji binarnej użycie binarnej entropii krzyżowej (binary_crossentropy),
- dla klasyfikacji wielowymiarowej użycie kategoryzującej entropii krzyżowej (categorical _crossentropy),
- w przypadku regresji błąd średniokwadratowy (mse).
Drugim zadaniem jest określenie algorytmu optymalizacji. Jego zadaniem jest poprawne pokierowanie funkcji straty do znalezienia jak najmniejszego błędu. Tutaj również jest wiele algorytmów do dyspozycji. Jedne z nich to:
- propagacja RMS,
- propagacja ADAM (ang. adaptive moment estimation),
- stochastyczny spadek wzdłuż gradientu i metoda pędu (AGD).
Więcej o wszystkich dostępnych optymalizacjach możecie poczytać tutaj: https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
Gdybyście mieli jakiekolwiek wątpliwości co stosować to proponuję zastosować prostą zasadę, której nauczył mnie Vladimir Alekseichenko: „Mirek, jak czegoś nie wiesz przyjmij wartości domyślne i idź dalej. Potem będzie czas na poprawki„.
Dobra, a wracając do naszego zagadnienia wykorzystajmy Adama 🙂
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
Podsumowanie modelu
Jak już skończymy dobierać architekturę można zobaczyć jak ona wygląda:
model.summary()

W omawianym przykładzie utworzyłem sieć składającą się tylko z jednej warstwy ukrytej. Tak jak widać nawet tak prosta sieć neuronowa jaką przygotowaliśmy ma już ponad 101 tysięcy parametrów (wag) do wytrenowania. Liczba parametrów w kolejnej warstwie to liczba wejść z wcześniejszej + wyraz wolny. Warstwy gęste (Dense) polegają na tym, że każda ma połączenie z każdą kolejną warstwą.
Dodatkowo można kolejne warstwy „mrozić” i wówczas liczba wszystkich „trainable parameters” będzie mniejsza niż wszystkich. Samo mrożenie warstw postaram się wyjaśnić przy omawianiu zagadnienia „transfer learning” w późniejszych wpisach.
Trenowanie modelu
Tutaj sprawa nie jest bardziej skomplikowana niż przy innych modelach. Po prostu wykorzystujemy funkcję fit do wytrenowania sieci neuronowej 🙂 Natomiast zanim puścimy przeliczenie sieci warto doprecyzować kilka parametrów:
- w pierwszej kolumnie podajemy zbiór do trenowania,
- w drugiej kolumnie mamy naszą zmienną do przewidzenia,
- epoch – odpowiada za liczbę epok użytych do trenowania modelu – jedna epoka oznacza przejście całego zbioru przez sieć oraz powrót,
- verbose – parametr, dzięki któremu można ustawić informacje jakie mają wyświetlać się podczas trenowania sieci,
- batch_size – odpowiada za zdefiniowanie ile rekordów (obserwacji) przechodzi na raz podczas pojedynczego przebiegu zanim nastąpi pierwsza aktualizacja wag parametrów,
- validation_data – tutaj przekazujemy nasz zbiór do walidacji.
history = model.fit(X_train,
y_train,
epochs=10,
verbose=1,
batch_size = 256,
validation_data = (X_val, y_val)
)

Gdybyśmy natomiast nie chcieli podejmować decyzji na zbiorze walidacyjnym tylko trzymać go do ostatecznej oceny możemy albo wcześniej ze zbioru treningowego wydzielić jeszcze dodatkowy zbiór testowy na początku albo wykorzystać zamiast validation_data parametr validation_split, który odpowiada za to jak podzielić zbiór treningowy, na treningowy i testowy.
history = model.fit(X_train,
y_train,
epochs=10,
verbose=1,
batch_size = 256,
validation_split = 0.2
)

Wizualizacja z trenowania
By lepiej zrozumieć jak uczyła się nasza sieć neuronowa najlepiej narysować wykres uczenia dla zdefiniowanej metryki oraz straty w podziale na próbkę treningową oraz testową.
def draw_curves(history, key1='accuracy', ylim1=(0.8, 1.00),
key2='loss', ylim2=(0.0, 1.0)):
plt.figure(figsize=(12,4))
plt.subplot(1, 2, 1)
plt.plot(history.history[key1], "r--")
plt.plot(history.history['val_' + key1], "g--")
plt.ylabel(key1)
plt.xlabel('Epoch')
plt.ylim(ylim1)
plt.legend(['train', 'test'], loc='best')
plt.subplot(1, 2, 2)
plt.plot(history.history[key2], "r--")
plt.plot(history.history['val_' + key2], "g--")
plt.ylabel(key2)
plt.xlabel('Epoch')
plt.ylim(ylim2)
plt.legend(['train', 'test'], loc='best')
plt.show()
draw_curves(history, key1='accuracy', ylim1=(0.7, 0.95),
key2='loss', ylim2=(0.0, 0.8))
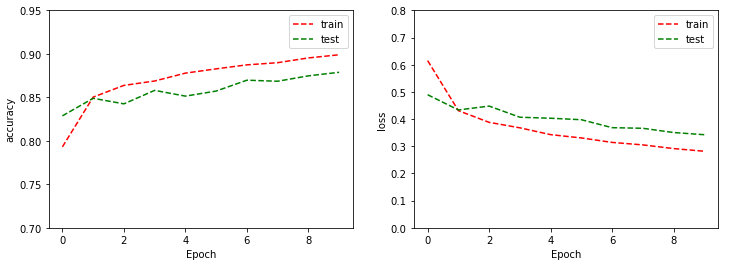
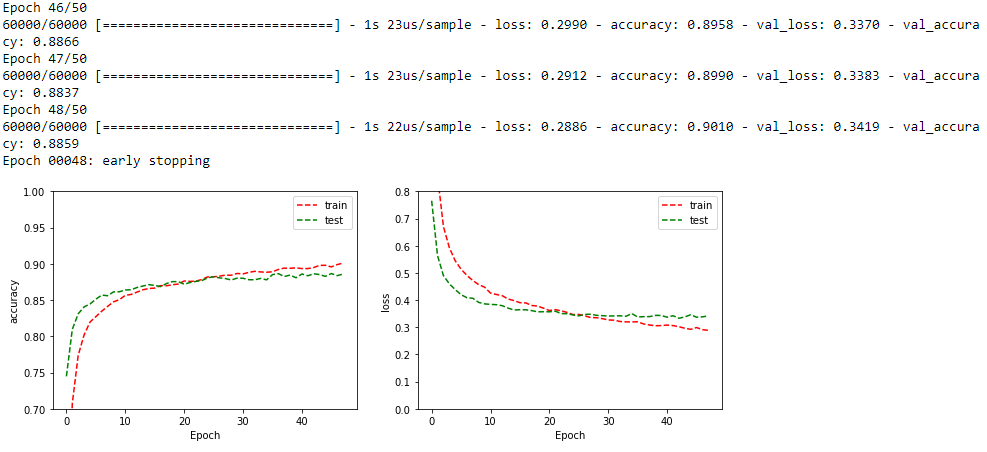
Wykres na lewo prezentuje jak wraz z kolejnymi epokami wygląda metryka accurancy w podziale na zbiorze treningowym i testowym. Widać, że na obu wykresach jest wzrost zatem spokojnie można byłoby zwiększyć jeszcze liczbę epok. Gdyby zielona linia zaczęła maleć oznaczałoby to, że mamy overfitting (przetrenowanie modelu).
Drugi wykres przedstawia stratę w podziale na zbiór uczący oraz testowy. Widać, że strata dla obu spada, zatem można byłoby zwiększyć liczbę epok dla tej architektury.
Sprawdźmy, jakby wyglądało to dla 50 epok definiując wszystkie kroki ponownie, abyście zobaczyli jak niewiele miejsca całość zajmuje:
model2 = Sequential()
model2.add(Flatten(input_shape=(28, 28)))
model.add(Dense(128, activation='relu'))
model2.add(Dense(10, activation = 'softmax'))
model2.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history2 = model2.fit(X_train,
y_train,
epochs=50,
verbose=1,
batch_size = 256,
validation_data = (X_val, y_val)
)
draw_curves(history2, key1='accuracy', ylim1=(0.7, 0.95),
key2='loss', ylim2=(0.0, 0.8))
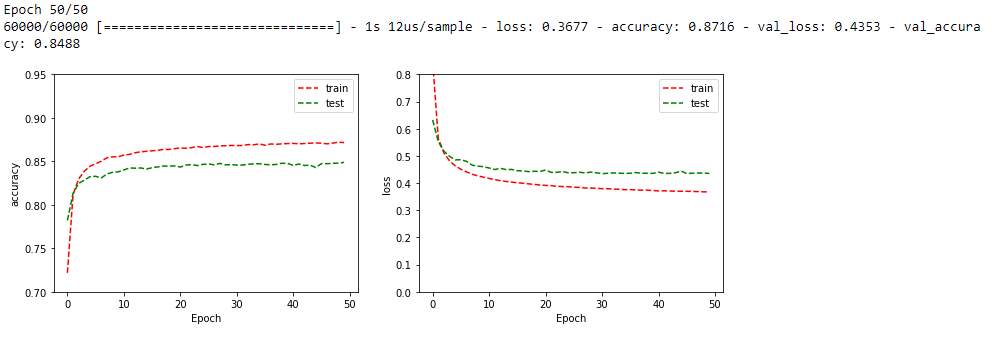
Jak widać zbiór walidacyjny od około 20 epoki nie polepsza się. Natomiast zbiór treningowy cały czas coraz lepiej działa. Wynika to z tego, że sie neuronowa zaczęła zapamiętywać dane treningowe. W przypadku bardziej skomplikowanych architektur często strata na zbiorze walidacyjnym zaczyna od pewnego momentu mocno rosnąć. Na szczęście jest kilka sposobów aby sobie z tym radzić.
Predykcja
Predykcje wykonujemy również w miarę intuicyjnie wykorzystując polecenie predict.
y_train_pred = model.predict(X_train)
y_val_pred = model.predict(X_val)
Zwizualizujmy sobie jeszcze czy dobrze nasz model przewiduje. Na zielono zaznaczamy poprawną klasę a na czerwono oznaczamy klasy, gdzie nasz model się myli.
def plot_value_img(i, predictions, true_label, img):
predictions, true_label, img = predictions[i], true_label[i], img[i]
predicted_label = np.argmax(predictions)
true_value = np.argmax(true_label)
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.yticks(np.arange(len(class_names)), class_names)
thisplot = plt.barh(range(10), predictions, color="gray")
thisplot[predicted_label].set_color('r')
thisplot[true_value].set_color('g')
plt.subplot(1, 2, 2)
plt.imshow(img, cmap=plt.cm.binary)
if predicted_label == true_value:
color = 'green'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions),
class_names[true_value]),
color=color)
plt.show()
plot_value_img(1, y_val_pred, y_val, X_val)
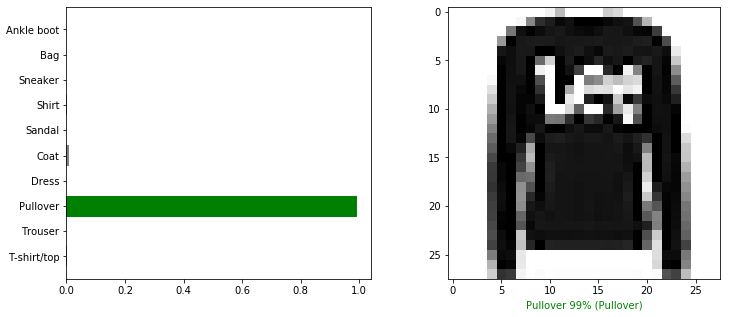
Jak widać model przewidział na 99%, że będzie to sweter i się nie pomylił 🙂 Spójrzmy na inną obserwację.

W innym przykładzie model już tylko na 70% powiedział, że na obrazku widzi koszulę. Na szczęście dalej z sukcesem.
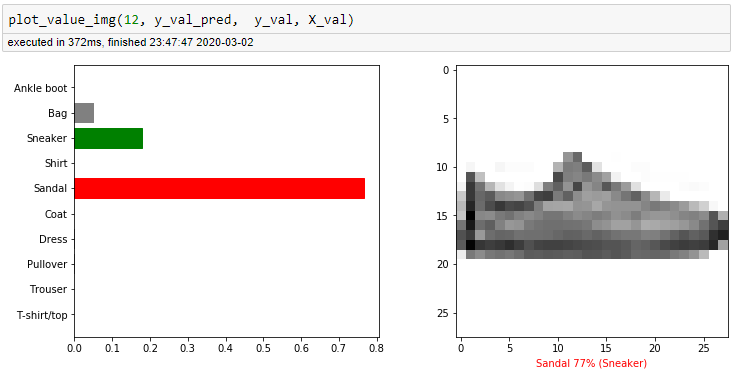
A tutaj model powiedział na 77%, że to sandał a w rzeczywistości jest to obuwie sportowe.
Jak sobie radzić z przetrenowaniem?
Najbardziej znane są cztery metody:
a. Więcej danych
Jeśli mamy bardzo dużo danych to najprostszym sposobem jest po prostu trenowanie sieci na większej liczbie danych. Dla przykładu jeśli dograliśmy informacje na podstawie ostatniego kwartału wówczas okres można rozszerzyć do całego roku. W przypadku modeli w oparciu o dźwięk można porozmnażać obrazy dokonując np obrotów, rotacji, zaciemnienia, dodania zakłóceń itp.
W przypadku danych numerycznych są metody, dzięki którym można powiększyć zbiór danych, np. wykorzystując autoenkodery.
b. Metoda porzucania (dropout)
Jest to najpopularniejszy sposób do walki z przetrenowaniem w przypadku sieci neuronowych. Dropout polega na losowym ustawieniu wychodzących krawędzi ukrytych jednostek (neuronów tworzących ukryte warstwy) na 0 przy każdej aktualizacji fazy treningu.
Fajnie to obrazuje przykładowa wizualizacja:

Metoda ta jest bardzo efektywna, ponieważ co każde przejście losowo wyłączane są połączenia. Dzięki temu sieć neuronowa nie nauczy się „na pamięć” zbyt szybko, ponieważ architektura co przeliczenie odrobinę się zmienia poprzez zerowanie losowych połączeń neuronów.
W Tensorflow dodajemy kolejne warstwy wykorzystując „Dropout” oraz definiując jaka część neuronów ma zostać zapomniana. Np. dla wartości 0.2 zostanie wylosowanych 20% połączeń do wyzerowania.
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.2))
Można jeszcze warstwę dodać na samym początku podczas wczytywania danych. Dzięki temu będziemy „porzucać” część danych wejściowych.
model.add(Dropout(0.5, input_shape=(28,28)))
c. Regularyzacja wag
Kolejną techniką do walki z przeuczeniem jest dokładanie do warstw kar, aby ich wartości były mniejsze. Te metody nazywamy regularyzacjami wag.
Tutaj przykład dodania regularyzacji normą L2 do warstwy gęstej:
from tensorflow.keras import regularizers
model2.add(Dense(10, activation = 'relu',
kernel_regularizer=regularizers.l2(0.01)))
d. Metoda wczesnego zakończenia (early stopping)

Jest to moja ulubiona metoda 🙂 Na dodatek idea jest bardzo prosta. Polega na tym, by zakończyć uczenie, gdy strata na zbiorze testowym nie rośnie. Czyli trenując dalej sieć nie poprawiamy mocy modelu na zbiorze testowym.
W tensorflow mamy do dyspozycji funkcję EarlyStopping, która monitoruje stratę na zbiorze testowym po zakończeniu każdej epoki. Jeśli strata nie maleje, wówczas trening sieci zostaje zatrzymany. Należy zdefiniować 3 podstawowe parametry ustawiając early stopping:
- monitor – definiujemy, co chcemy monitorować na podstawie czego zatrzymamy proces uczenia,
- patience – tym parametrem definiujemy liczbę epok po ilu zatrzyma się nasz model jeśli nie zaobserwujemy zmniejszania się funkcji straty,
- verbose – a tutaj w jaki sposób będzie wyświetlana informacja o early stoping.
Pamiętacie jak powyżej odpaliliśmy architekturę dla 50 epok, aby pokazać jak sieć neuronowa się przeucza? Wykorzystajmy ten sam kod przy wykorzystaniu techniki early stopping.
from tensorflow.keras.callbacks import EarlyStopping
model2 = Sequential()
model2.add(Flatten(input_shape=(28, 28)))
model2.add(Dense(128, activation='relu'))
model2.add(Dense(10, activation = 'softmax'))
model2.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
EarlyStop = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1)
history2 = model2.fit(X_train,
y_train,
epochs=50,
verbose=1,
batch_size = 256,
validation_data = (X_val, y_val),
callbacks = [EarlyStop]
)
draw_curves(history2, key1='accuracy', ylim1=(0.7, 1.0),
key2='loss', ylim2=(0.0, 0.8))

Jak widać super zadziałało! 🙂

Warto dodać jedną rzecz. Nasz model zatrzymał się po 3 epokach od najlepszego modelu. Dlatego warto jeszcze zapisać najlepszy model, który otrzymaliśmy. Można ten parametr też zdefiniować w callbackach. Zapewnia to poniższy kod do trenowania sieci:
from tensorflow.keras.callbacks import ModelCheckpoint
ModelCheck = ModelCheckpoint(filepath='moj_najlepszy_model.h5',
monitor='var_loss',
save_best_only=True)
history2 = model2.fit(X_train,
y_train,
epochs=50,
verbose=1,
batch_size = 256,
validation_data = (X_val, y_val),
callbacks = [EarlyStop, ModelCheck]
)
Ostateczna architektura
Teraz możecie usiąść i dobrać najlepszą architekturę w takim czasie jaki sobie założycie.
Dla przykładu ja dobrałem taką:
from tensorflow.keras.callbacks import EarlyStopping
model_best = Sequential()
model_best.add(Flatten(input_shape=(28, 28)))
model_best.add(Dense(128, activation='relu'))
model_best.add(Dropout(0.3))
model_best.add(Dense(64, activation='relu'))
model_best.add(Dropout(0.3))
model_best.add(Dense(32, activation='relu'))
model_best.add(Dropout(0.3))
model_best.add(Dense(10, activation = 'softmax'))
model_best.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
EarlyStop = EarlyStopping(monitor='val_loss',
patience=5,
verbose=1)
history_best = model_best.fit(X_train,
y_train,
epochs=50,
verbose=1,
batch_size = 1024,
validation_data = (X_val, y_val),
callbacks = [EarlyStop]
)
draw_curves(history_best, key1='accuracy', ylim1=(0.7, 1.0),
key2='loss', ylim2=(0.0, 0.8))
Jestem pewien, że możecie pobić wynik! Dajcie znać w komentarzach ile wykręciła Wasza sieć neuronowa prostą architekturą warstw gęstych (Dense) oraz wykluczeń (Dropout).
Podsumowanie
Jeśli powtórzyliście opisane przeze mnie kroki to jestem pewien, że będziecie umieli już pisać swoje własne sieci. W jednym z kolejnych wpisów opowiem i pokażę, że sieć neuronowa konwulcyjna (CNN) jest wyśmienita do analizy zdjęć i nie tylko!
Pozdrawiam serdecznie,




Świetny artykuł, jak ktoś chce się od podstaw wgryźć w sieci neuronowe. Cały blog mi się przyda na doktoracie.
Znalazłem też literówkę: przy ModelCheck w monitor powinno być „val”, a nie „var”. Liczę, że się przyda 🙂
????
gut job miało być 🙂
Gratuluję dobrze napisanego podręcznika. Krótko, zwięźle i precyzyjnie przedstawione zostało zagadnienie.
Od 2 dni trenuję sieć i póki co mam wynik jak poniżej.
Epoch 30/100
59/59 [==============================] – 7s 113ms/step – loss: 0.1607 – accuracy: 0.9414 – val_loss: 0.4060 – val_accuracy: 0.8797
Super, cieszę się, że mogłem pomóc. Mam nadzieję, że teraz pójdziesz dalej i wytrenujesz własną sieć do nowego problemu 😉 Powodzenia w zabawie (i przy okazji nauce)!
witam,
jako zoltodziob w sferze cnn z checia przegladam ten przyklad i niestety wyskakuje mi blad jak dochodze do sekcji PREDYKCJA , tam gdzie po przetrenowaniu modelu mozna wybrac zdjecie i sprawdzic jak sobie model radzi
def plot_value_img(i, predictions, true_label, img):
predictions, true_label, img = predictions[i], true_label[i], img[i]
predicted_label = np.argmax(predictions)
true_value = np.argmax(true_label)
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.yticks(np.arange(len(class_names)), class_names)
thisplot = plt.barh(range(10), predictions, color=”gray”)
thisplot[predicted_label].set_color(’r’)
thisplot[true_value].set_color(’g’)
plt.subplot(1, 2, 2)
plt.imshow(img, cmap=plt.cm.binary)
if predicted_label == true_value:
color = 'green’
else:
color = 'red’
plt.xlabel(„{} {:2.0f}% ({})”.format(class_names[predicted_label],
100*np.max(predictions),
class_names[true_value]),
color=color)
plt.show()
plot_value_img(1, y_val_pred, y_val, X_val)
ValueError: shape mismatch: objects cannot be broadcast to a single shape
niestety na tym etapie nie wiem jak to naprawic – nie wiem jaki to blad, bo sprawdzam kod ze stronka i jest ok, zadnego bledu w kopiowaniu
Hej! Nie przejmuj się błędami. Każdy z nas był kiedyś żółtodziobem, więc się tym nie zrażaj.
Ten błąd może wystąpić, gdy podczas rysowania współrzędna x i współrzędna y pojawią się parami i nie mają tej samej długości.
Możliwe, że wystąpił z powodu użycia innej wersji pakietu.
Spróbuj prześledzić linijka po linijce gdzie jest błąd i jakie są rozmiary wektorów do rysowania. Może tutaj jest błąd. Jak będą problemy daj znać. Jakbyś wysłał notebooka z informacją o wersjach pakietów to mógłbym zerknąc 😉
Dziękuje za świetny artykuł, przyda się na studia 🙂
dziękuję. I powodzenia na studiach! ps. baw się i zwiedzaj świat też na studiach ile wlezie, bo potem już nie będzie tyle czasu 😛
Świetny artykuł – wielkie dzięki! 😉 To na pewno dobra baza do dalszych eksperymentów i nauki.
Po małych modyfikacjach:
Epoch 50/50
59/59 [==============================] – 1s 10ms/step – loss: 0.1859 – accuracy: 0.9316 – val_loss: 0.3397 – val_accuracy: 0.8914
dzięki! objaśnione na tyle przystępnie, że da się treść zrozumieć, i wystarczająco szczegółowo żeby dalej samemu drążyć temat dalej 🙂
Dzięki za info. W sumie masz rację, że najważniejsze byśmy sami wszystko szczegłowiej zgłebiali i drążyli 😉
Wszystko bardzo dobrze wytłumaczone, lepiej niż zrobił to google w swoim tutorialu! Właśnie tego potrzebowałam. Zostałam na studiach rzucona na głęboką wodę, więc fajnie że można znaleźć pomoc w takich artykułach jak ten.
Dziękuję!
Super! Cieszę się, że mogłem pomóc Ci Zosia 🙂
I powodzenia ze studiami !
Dzięki za fajny artyuł
Nie ma za co! 🙂
Pozdrawiam serdecznie