
– Tato, co robisz?
– To, co Ci ostatnio obiecałem Kochanie.
– Aaa….skrobarkę – uśmiechnęła się Jagódka.
– Tak. Jak już się pozna podstawy to pisanie tego programu do ściągania danych idzie raz-dwa.
– To super, czyli idziemy robić naleśniki?
– Tak! Wołaj Oti i lecimy.
Bardzo długo przymierzałem się do nauki scrapingu. Na szczęście pojawił się ciekawy projekt zarówno w pracy jak i poza nią, co przyśpieszyło moją edukację w tym zakresie. Postawmy sobie cel, że chcemy pobrać na potrzeby projektu „naukowego” poezję polskich poetów. Tylko jak się do tego zabrać? Prosto!
Najpierw znajdźmy źródło danych. Po godzinie researchu miałem kilka super linków. Ostatecznie wybrałem zbiór z Wikipedii. O tutaj jest lista autorów. Mamy stronę internetową i co dalej? Zaczynajmy…
Z czego składa się strona internetowa?
Kiedy wszedłeś na stronę z tym artykułem to Twoja przeglądarka wysłała żądanie do serwera internetowego, by pobrać zawartość. Następnie serwer odesłał Ci odpowiednie pliki, by prawidłowo wyświetlić stronę. Pliki można z grubsza podzielić na:
- HTML – zawierają główną część strony,
- CSS – tutaj jest zdefiniowany wygląd (np. style czcionki, akapitów itp.),
- Zdjęcia – po prostu wszelkiego rodzaju grafiki, aby umożliwić wyświetlenie obrazów,
- JS – pliki Javascript dodające interaktywność na stronie.
Podczas scrapowania najczęściej chcemy wyciągnąć informacje zaszyte w HTML.

A co to jest HTML?
HTML to język, w którym napisana jest większość witryn internetowych. HTML służy do tworzenia stron i zapewnienia ich funkcjonalności. Kod użyty do uczynienia ich wizualnie atrakcyjnymi jest znany jako CSS i nie będę się tutaj na nim skupiał. W tym momencie ważniejsza jest nauka budowania domów (HTML), a nie projektowania wnętrz (CSS).
HTML został po raz pierwszy użyty przez Tima Berners-Lee i Roberta Cailliau w 1989 roku. To skrót od Hyper Text Markup Language. Hipertekst oznacza, że dokument zawiera łącza, które umożliwiają czytelnikowi przechodzenie do innych miejsc w dokumencie lub w ogóle do innego dokumentu. Język znaczników to sposób, w jaki komputery komunikują się ze sobą, aby kontrolować sposób przetwarzania i prezentacji tekstu. Aby to zrobić, HTML używa dwóch rzeczy: znaczników i atrybutów.
Czym są tagi i atrybuty?
Tagi są używane do zaznaczania początku elementu HTML i zwykle są ujęte w nawiasy ostre. Przykładem tagu jest: <h1>. Większość tagów musi być otwierana <h1> i zamykana </h1>, aby działały. W przypadku używania wielu tagów muszą być one zamknięte „od środka” – czyli w przeciwnej kolejności, w jakiej zostały otwarte (np. <p><b>od środka</b></p>).
Atrybuty zawierają dodatkowe informacje. Atrybuty mają postać otwierającego tagu, a dodatkowe informacje są umieszczone wewnątrz. Przykładem atrybutu jest:
<img src = „córeczki_tatusia.jpg” alt = „Zdjęcie moich dwóch z trzech dziewczyn.”>
W tym przypadku źródło obrazu (src) i tekst alternatywny (alt) są atrybutami znacznika <img>.

Podstawowa konstrukcja strony
Podstawowa konstrukcja strony składa się z poniższych elementów:
- <! DOCTYPE html> – ten tag określa język, w którym będziesz pisać na stronie. W tym przypadku językiem jest HTML 5,
- <html> – ten tag sygnalizuje, że odtąd będziemy pisać w kodzie HTML,
- <head> – to tutaj trafiają wszystkie metadane strony – rzeczy przeznaczone głównie dla wyszukiwarek i innych programów komputerowych,
- <body> – to jest miejsce, gdzie trafia zawartość strony.
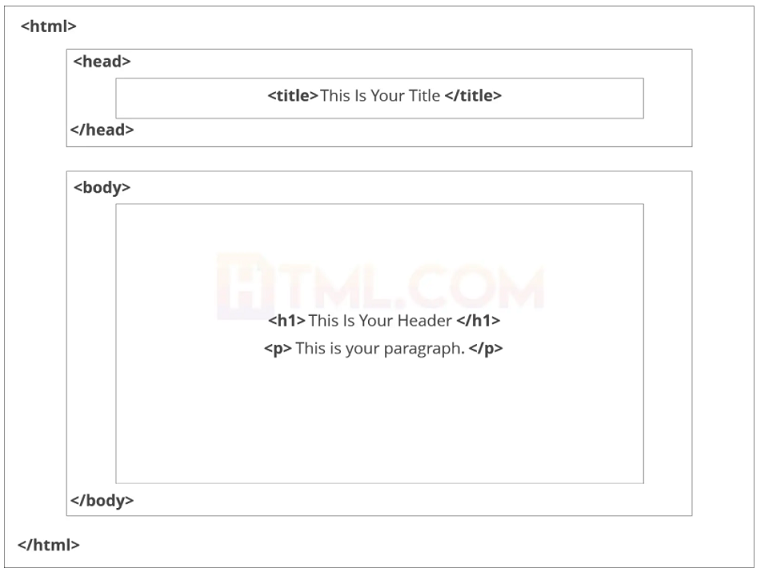
Zróbmy przykładową stronę. Tutaj jest kod:
<html>
<head>
</head>
<body>
<p>
To mój pierwszy paragraf!
<a href="https://miroslawmamczur.pl/kim-jest-data-scientist/">A to pierwszy post</a>
</p>
<p>
A tutaj drugi paragraf!
<a href="https://miroslawmamczur.pl/8-krokow-do-ladnych-wykresow/">I drugi post</a>
</p>
</body></html>
A tak wygląda:
===============================================To mój pierwszy paragraf! A to pierwszy post
A tutaj drugi paragraf! I drugi post
===============================================W powyższym przykładzie dodałem dwa tagi:
- <a> – znaczniki są łączami i nakazują przeglądarce renderowanie łącza do innej strony internetowej. Właściwość href tagu określa, dokąd prowadzi łącze
- <p> – jako nowy paragraf.
Te dwa znaczniki są najbardziej popularnymi tagami w HTML. Jest ich znacznie więcej i łatwo możesz ich wyszukać. O, na przykład TUTAJ.
Klasy i identyfikatory
Zanim przejdziemy do scrapingu warto poznać jeszcze tzw. klasy (ang. class) i identyfikatory (ang. id). Nadają one elementom HTML nazwy i ułatwiają korzystanie z nich podczas scrapingu.
Jeden element może mieć wiele klas, a klasa może być współużytkowania między elementami. Natomiast każdy element może mieć tylko jeden identyfikator, a identyfikatora można użyć tylko raz na stronie.
Klasy i identyfikatory są opcjonalne i nie wszystkie elementy będą je mieć. Natomiast jak są wówczas bardzo ułatwiają pracę.

Biblioteka request
Pierwszą rzeczą, jaką musimy zrobić, aby zeskrapować stronę internetową, jest po prostu jej pobranie. Możemy pobierać strony za pomocą biblioteki request w Python. Biblioteka wyśle żądanie GET do serwera, który pobierze dla nas zawartość HTML z danej strony. Pobierzmy dla przykładu poprzedni artykuł!
import requests
page_url = 'https://miroslawmamczur.pl/'
page = requests.get(page_url)
page
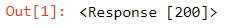
Po uruchomieniu naszego żądania otrzymujemy obiekt Response. Ten obiekt ma właściwość status_code, która wskazuje, czy strona została pomyślnie pobrana.Hura!!! Status_code równy 200 oznacza, że strona została pobrana pomyślnie. Nie będziemy tutaj w pełni zagłębiać się w kody, ale warto zapamiętać, że kod zaczynający się od 2 zwykle oznacza sukces, a kod zaczynający się od 4 lub 5 wskazuje na błąd.
Możemy wydrukować zawartość HTML strony za pomocą właściwości content:
page.content

Uaa… sporo tekstu i nic nie widać. I co teraz?
BeautifulSoup ku pomocy rozprasowania HTML’a!
BeautifulSoup to biblioteka Pythona, której nazwa pochodzi z „Alicji w Krainie Czarów”, od wiersza Lewisa Carrolla o tej samej nazwie.
Krótko mówiąc, BeautifulSoup to pakiet, który analizuje kod HTML (lub XML!) oraz pomaga organizować i formatować dane internetowe w bardziej przyjazne struktury.
Teraz wykorzystajmy bibliotekę BeautifulSoup, aby przeanalizować pobraną stronę HTML i wyodrębnić tekst ze znacznika p. Najpierw import biblioteki, a następnie należy utworzyć klasę BeautifulSoup, aby przeanalizować nasz dokument. Wyświetlmy jeszcze raz to co wyżej:
from bs4 import BeautifulSoup
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify()) #ładniejszy sposób na wyświetlenie

O wygląda już lepiej niż za pomocą samego requests. BeautifulSoup ma wiele opcji. Jeśli chcesz zgłębić go bardziej polecam zapoznać się z dokumentacją.
Teraz pokażę ci 3 najczęstsze opcje.
1. Znalezienie wszystkich tagów w BeautifulSoup
Jeśli chcemy wyodrębnić pojedynczy tag, możemy użyć metody find_all, która znajdzie wszystkie wystąpienia tagu na stronie. Poszukajmy dla przykładu wszystkich linków ze strony głównej.
list_all_p = soup.find_all('a')
print(f'znalazłem {len(list_all_p)} linków')
list_all_p[10]

A jeśli chcesz wyciągnąć po prostu wyświetlany tekst pod linkiem to możesz tak:
list_all_p[10].get_text()

Jeśli zamiast znaleźć wszystko, chcesz tylko pierwsze wystąpienie tagu, to użyj metody find, która zwróci pojedynczy obiekt BeautifulSoup.

2. Wyszukiwanie tagów według klasy lub identyfikatora
Jeśli szukasz czegoś konkretnego, na przykład powitania po prawej stronie, to najlepiej „zbadać” kod HTML na stronie i wyciągnąć konkretną klasę lub identyfikator. W przeglądarce Chrome wystarczy nacisnąć kombinację klawiszy „Crtl+Shift+l” lub kliknąć prawym klawiszem myszki i wybrać „Zbadaj„. Następnie przeglądając „Elements” po zaznaczeniu kawałka na ekranie będzie się podświetlać element, za który odpowiada dany kod HTML. W ten sposób wyszukujemy kawałek, który nas interesuje. Poniżej możecie zobaczyć jak to wygląda na przykładzie mojej strony internetowej.
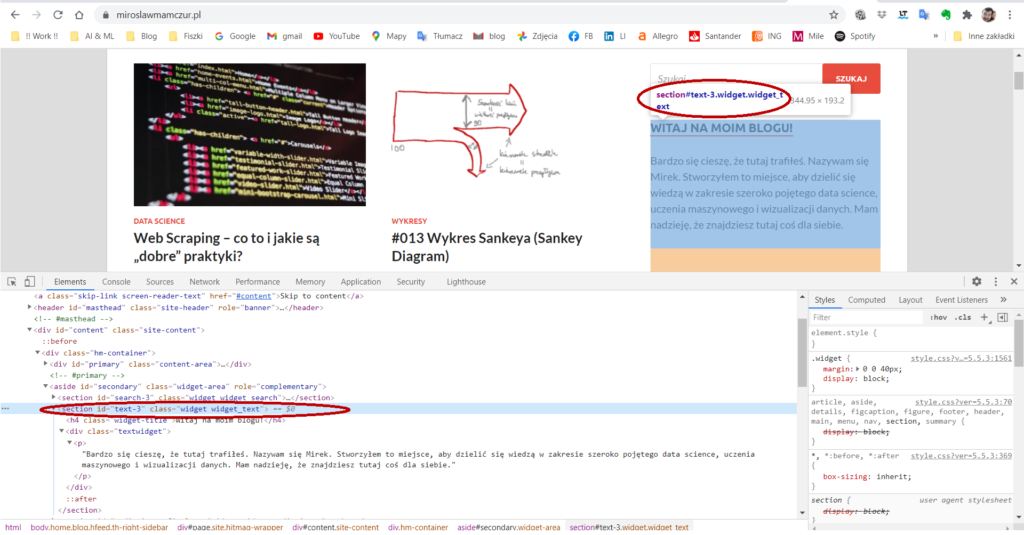
Zatem, aby się dobrać do kawałka, który postanowiliśmy wyciągnąć możemy podać identyfikator (id) elementu. I pamiętaj, aby wyświetlić ładny tekst wykorzystując get_text():
soup.find_all(id='text-3')

Super. Przeglądając dokładniej „Elements” możesz też zauważyć, że jeśli chciałbyś sam tekst (bez „Witaj…”), to możesz znaleźć wyszukanie po klasie, które to zapewnia:

soup.find_all(id='text-3')[0].get_text()

3. Szukanie po selektorach CSS w BeautifulSoup
Tak jak wcześniej wspominałem CSS odpowiada za wygląd elementów. Selektor CSS informuje przeglądarkę, które elementy HTML należy wybrać i zastosować do nich odpowiedni wygląd zgodny ze stylizacją opisaną za pomocą CSS. Przykładem może być wybór wszystkich czcionek wielkości h3 z body, a następnie wybranie z nich linków.
soup.select('body h3 a')


Pobranie wierszy polskich poetów!
Znamy podstawy, to można wrócić do naszego pierwotnego zadania. Zgodnie z tym, co opisałem w poprzednim artykule sprawdzamy, czy wszystko będzie zgodne z prawem. Nie ma nigdzie informacji, że nie można automatyczne pobierać interesującej mnie kwestii. Natomiast wątpliwość mnie naszła w przypadku dwóch punktów: prawa autorskie (w końcu pobieramy wiersze) i RODO (chciałem wiersz zapisać w folderze z imieniem i nazwiskiem autora). W związku z tym, że jest to projekt „na własny użytek publiczny” oraz „w celach dydaktycznych” to jest ok.
Krok 1 – Lista autorów
W pierwszym kroku przyjrzyjmy się stronie: https://pl.wikisource.org/wiki/Kategoria:Polscy_poeci. Widzę, że nie wszyscy poeci zmieścili się na jednej stronie. Lista wszystkich autorów wierszy znajduje się na trzech stronach.
Wobec tego utwórzmy sobie listę, aby przejść po wszystkich trzech stronach i dla nich pobrać w pierwszym kroku linki do autorów i zapisać ich do listy. Następnie pobierzmy po kolei każdego autora i wyszukajmy napisane przez niego wiersze.
import time
import requests
from bs4 import BeautifulSoup
#zczytanie wszystkich linków w zbiorach wierszy
page_list =["https://pl.wikisource.org/wiki/Kategoria:Polscy_poeci",
"https://pl.wikisource.org/w/index.php?title=Kategoria:Polscy_poeci&pagefrom=Laskowski%2C+Kazimierz%0AKazimierz+Laskowski#mw-pages",
"https://pl.wikisource.org/w/index.php?title=Kategoria:Polscy_poeci&pagefrom=Wolski%2C+Wac%C5%82aw%0AWac%C5%82aw+Wolski#mw-pages"]
url_autors = []
start = time.time()
for page_url in page_list:
#wybranie strony do szukania linków z autorami
page = requests.get(page_url)
soup = BeautifulSoup(page.content, 'html.parser')
for a in soup.find_all('a', href=True):
if a['href'][0:11]=='/wiki/Autor':
url_autors.append(a['href'])
print(f'Pobrałem {len(url_autors)} autorów w ciągu {round(time.time()-start,1)} sekund')


Wow! W 2 sekundy mamy całość. Można poczuć moc :). Zauważ, że troszkę czasu zajęło nam przygotowanie kodu, zanim otrzymaliśmy to czego chcemy. Pamiętaj, że zawsze musisz przyjrzeć się strukturze wybranej strony.
Krok 2 – lista wierszy
Zauważyłem, że każdy link z autorem zaczyna się od „/wiki/Autor„. Było tam sporo informacji o poecie i jego utworach. W trakcie rozpoznania strony zauważyłem także, że można dla danego autora wyszukać utwory z końcówki adresu: „/wiki/Kategoria:Autor„. Struktura kodu HTML jest tutaj prostsza do sczytania kolejnych linków.
Dla każdego autora działa to tak samo. Spójrz tutaj dla przykładu na Adama Asnyka:

Dodatkowo widzimy informacje, że dostępnych jest 85 stron – w tym jedna jako link do autora. Zatem ostatecznie powinniśmy pobrać 84 poematy.
Krok 3 – pobranie wierszy
Już prawie wszystko jest. Ostatni krok (jak mi się pierwotnie wydawało) – pobieramy wiersze. Zrobiłem to prosto:
- dla danego autora popieramy jego wszystkie utwory,
- następnie tworzymy folder z nazwą autora,
- przechodzimy po liście wchodząc na każdy wiersz i pobieramy pierwszy paragraf <p> (podczas reaserch zauważyłem, że tak najprościej pobrać wiersze),
- zapisujemy wiersz do folderu autora.
Było troszkę zabawy, testów i obsługi błędów, zanim powstał ostateczny kod, który zamieściłem poniżej.
import os
import re
import io
i = 1 # to iteracji kolejnych autorów
start_full = time.time()
for url_autor in url_autors[0:10]:
start = time.time()
autor = url_autor.replace('/wiki/Autor:','')
# stworzenie folderu autora jesli nie istnieje
directory = f'./data_raw/{autor}/'
if not os.path.exists(directory):
os.makedirs(directory)
url = 'https://pl.m.wikisource.org'+url_autor.replace('Autor','Kategoria') #ta zmiana daje prostszą stronę
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
try:
#znalezienie wierszy ze strony autora
poems_url = []
for a in soup.find_all('a', href=True):
if '/wiki/Autor:' not in a['href'] and '/wiki/Kategoria:' not in a['href']:
poems_url.append(a['href'])
#przycięcie do samych tekstów i wywalenie zbędnych linków
list_index_from = [idx for idx, s in enumerate(poems_url) if '&from=%C5%BB' in s][0]
poems_url = poems_url[list_index_from+1:]
poems_url = [poems for poems in poems_url if '/w/index.php?title=Kategoria:' not in poems]
list_index_to = [idx for idx, s in enumerate(poems_url) if '/wiki/' not in s][0]
poems_url = poems_url[:list_index_to]
except:
pass
# pętla do pobraniawszystkich znalezionych wierszy z url
for poem in poems_url:
title = poem.replace('/wiki/','')
try:
page = requests.get('https://pl.m.wikisource.org'+poem)
soup = BeautifulSoup(page.content, 'html.parser')
# zamiana break lines na nową linie
for br in soup.find_all("br"):
br.replace_with("\n")
#znajdowanie tekstu
text = soup.find_all('p').get_text()
#czyszczenie
clean_text = re.sub('<.*?>', '', str(text)) #usunięcie rzeczy htmlowych pomiędzy znakami < oraz >
#zapisanie pliku
with io.open(directory+title.replace('/',' ')+'.txt', "w", encoding="utf-8") as f:
f.write(str(clean_text))
except:
pass
print(f'Autor {i} z {len(url_autors)}: {autor}; pobrano {len(poems_url) -1} dzieł w ciągu {round(time.time()-start,1)} sekund')
print(url)
i = i+1
print(f'Całość zajęła {round(time.time()-start_full,1)} sekund')

Nie jest źle – w troszkę ponad minutkę pobrały się dzieła 10 autorów. No to puszczamy całość!
Uwaga! Jeśli chcesz pobrać całość w linijce „for url_autor in url_autors[0:10]:” usuń „[0:10]„. Wtedy pętelka przejdzie po całej liście autorów.
Krok 4 – dodatkowe czyszczenie
Po pobraniu całości danych zobaczyłem, że warto byłoby upiększyć jeszcze zapisane wyniki. Wszystko zależy od tego, czego oczekujesz. Ja chciałem oczyścić tekst o niepotrzebne linie czy znaki.
Niestety nie zrobiłem tego podczas ściągania, stąd ten dodatkowy krok :(. Miałem ograniczony czas i nie chciałem zbytnio znów obciążać Wikipedii pobieraniem drugi raz tych samych danych. Dlatego dorobiłem oczyszczanie „na boku” jako kolejny krok. Następnym razem postaram się w projekcie zaplanować więcej czasu na dane.
import pandas as pd
import os
import io
import random
import time
import re
FOLDER_ROW = '.\data_raw'
FOLDER_CLEAN = '.\data_clean'
#tworzenie folderu jeśli nieistnieje
def create_folder(path):
if not os.path.exists(path):
os.makedirs(path)
#oczyszczanie url z unicode na polskie znaki
from urllib.parse import unquote
def cleanup(url):
try:
return unquote(url, errors='strict')
except UnicodeDecodeError:
return unquote(url, encoding='polish-1')
def clean_poem(poem):
clean_poem =''
#usuń dziwne znaczki:
poem = re.sub("[@#$%^&*(){}„”“»«/<>|`~=_+]", "", poem) #usuń znaki specjalne
poem = poem.replace('[','').replace(']','') #usuń znaki []
poem = poem.replace('\xa0','') #usuń tabulatory
poem = re.sub(' +', ' ', poem) #usuń wielokrotne spacje
#przechodzimy linijka po linijce w stringu
for line in poem.split('\n'):
if line[0:2]==', ':
line = line[2:]
if line[0:1]==' ':
line = line[1:]
if 'Uwaga! Tekst niniejszy' in line: #Uwaga! Tekst niniejszy w języku polskim został opublikowany w ok. 1860.
line = ''
if 'Stosowane słownictwo i ortografia' in line: #Stosowane słownictwo i ortografia pochodzą z tej epoki, prosimy nie nanosić poprawek niezgodnych ze źródłem!
line = ''
if line==re.sub('[^0-9 ]', '', line): #gdy same cyfry to usuń
line = ''
if len(line.replace(" ", ""))>2:
clean_poem=clean_poem+line+'\n'
#jeśli tekst kończy się nową linią to ją usuń
if clean_poem[-1:]=='\n':
clean_poem=clean_poem[:-2]
return clean_poem
#na potrzeby testów do pisania kodu do oczyszczania losujemy wiersz
rnd_author = random.choice(os.listdir(FOLDER_ROW))
rnd_poem = random.choice(os.listdir(os.path.join(FOLDER_ROW, rnd_author)))
poem_path = os.path.join(FOLDER_ROW, rnd_author, rnd_poem)
#wczytanie pliku
with open(poem_path, 'r', encoding="utf8") as file:
poem = file.read()
#zapisanie pliku
create_folder(os.path.join(FOLDER_CLEAN,rnd_author))
# open(os.path.join(FOLDER_CLEAN,rnd_author,rnd_poem), "w", encoding="utf-8") as f:
# f.write(str(poem))
print(poem)
print(clean_poem(poem))

Uwaga! Mam świadomość, że można byłoby to zrobić lepiej i dokładniej! Jak wiesz co udoskonalić daj mi znać – chętnie się douczę :). Natomiast obracając się w „korpo świecie” powiedziałbym, że zrobiłem MVP (ang. Minimal Viable Product), czyli minimalną wartość, jakiej oczekiwałem w zakładanym czasie. Można byłoby poprawić tutaj sporo rzeczy 🙂
Podsumowanie
I super. Mamy przygotowane dane. I co z nimi można zrobić? Troszkę przeanalizować dla zabawy :):
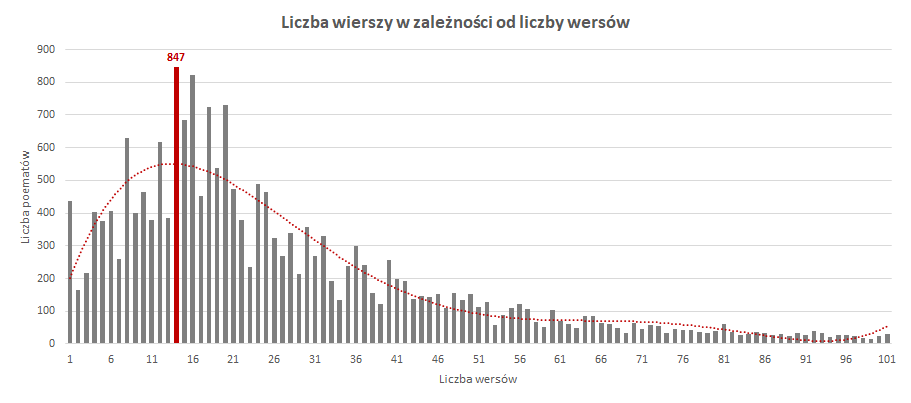

Ale o tym, co ostatecznie zrobiłem z tymi danymi napiszę już wkrótce 🙂. Jak tylko zrozumiemy dokładniej, jak działają transformery.
Do usłyszenia niebawem!
Pozdrawiam serdecznie z całego serducha,




Krok 3.3, pisze się „research”, nie „reaserch”
Witam,
Jako osobie z zerowym pojęciem na ten temat świetnie mi się czytało Pana artykuł. Dziękuję za inspirację i pozdrawiam cieplutko xD
Jakub
Dziękuję za informacje 🙂
Jedna drobna uwaga: wszystkie te migające, mrygające i ruszające się GIF-y bardzo rozpraszają podczas czytania
dzięki za info 🙂
Dlatego w najnowszych wpisach już ich nie stosuje, bo otrzymywałem więcej takich sygnałów od czytelników.
Cześć 🖐.
Bardzo fajny artykuł 👏. Spodobał mi się twój kod Mirku ☺️. Z tego co widzę to automatyczne pobieranie danych z internetu, stron www, nie jest takie trudne a może bardzo pomóc w wydajności zadań przed którymi jakiś pracownik stoi.
Wiem że jest taka biblioteka jak scrapy w Pythonie. Czy ona się różni od BeautifulSoup? Czy BeautifulSoup został stworzony tylko do web scrappingu czy ma też jakieś inne zastosowania?
Btw. Skąd bierzesz gify do swoich artykułów? Masz jakąś bazę assetów online? Przydało by mi się to do mojego bloga?
Hej 👋
Hej Mateusz,
Scrapy to po prostu duży framework do indeksowania stron internetowych, która przy zawiera wiele narzędzi ułatwiających przeszukiwanie sieci i skrobanie.
BeautifulSoup to prosta biblioteka, która przede wszystkim służy do wyciągania danych z dokumentów HTML i XML. Zauważ, że w kodzie dane pobieram poprzez prostą bibliotekę request, a potem tylko przeszukuję zawartość kodu HTML do znalezienia odpowiednich rzeczy, które mnie interesują.
Dodałbym, że BeautifulSoup to fajne i przyjazne dla początkujących, dzięki któremu nowicjusz może z nim uderzyć w ziemię. A ja dopiero uczę się scrapować na potrzeby różnych projektów 🙂
Scrapy przydaje się głównie do większych projektów. Mam plan by kiedyś też się go nauczyć i podzielić się na blogu jak się go nauczę.
Pozdrawiam,
Mirek
ps. Wszystkie GIFy biorę stąd https://giphy.com/
i wstawiam je jako media „small” by strona jak najszybciej działała.
Pingback: Polski poeta AI (GPT-2 na Google Colab) - Mirosław Mamczur
„W przypadku używania wielu tagów muszą być one zamknięte w kolejności, w jakiej zostały otwarte.”
chyba odwrotnej? zamykamy „od środka”
Masz racje! Dziękuję za czujność – już poprawiłem 😉