
– Tatusiu, poczytasz nam wiersze na dobranoc? – zapytała Jagódka.
– Oczywiście Skarbie. A czyje wiersze mam Wam poczytać?
– Hmm… Może tego pisarza, który najwięcej razy użył słowo Otylka w swoich wierszach?
– Ojej, nie mam pojęcia kto to może być. Ale jeśli chcecie to jutro spróbujemy poskrobać strony w internecie.
– A co znaczy, że poskrobiemy?
– Nic innego, niż to, że napiszemy program, który sam ściągnie wszystkie wiersze, jak my będziemy robić naleśniki!
– Hura! Nalekiki ! – krzyknęła Otiś z radością na myśl o jutrzejszej przygodzie…
Czasami potrzebujemy wydobyć informacje zapisane na stronach internetowych. Jeśli dana witryna internetowa nie udostępnia API, to na ratunek przychodzi web scraping (skrobanie stron).
Często obijało mi się o uszy, że jest to troszkę taka szara strefa. Pamiętajmy jednak, że firma Google oparła swoją działalność na ciągłym pobieraniu i indeksowaniu innych treści. Prawda jest taka, że web scraping nie ma w sobie nic nielegalnego! Ale nie oznacza to, że możesz zeskrobać dowolną witrynę. To, w jaki sposób to robisz i co zrobisz z danymi może czasami być już nielegalne!
W tym wpisie podam Ci zestaw kilku wskazówek, których warto moim zdaniem trzymać się podczas skrobania stron w internecie. Zaczynajmy!
Co to jest web scraping?
Web Scraping to technika wyodrębniania danych ze stron internetowych, która zastępuje ręczne, powtarzalne wpisywanie lub kopiowanie i wklejanie. Dodatkowo pozyskane dane często są przechowywane w ustrukturyzowanym formacie. Obecnie skrobanie stron internetowych jest szeroko stosowane i ma wiele zastosowań, m.in.:
- firmy mogą pobierać informacje odnoście produktów swojej konkurencji,
- można pobierać informacje o potencjalnych klientach (osoby fizyczne lub inne firmy),
- porównywanie cen w celu znalezienia najtańszej oferty (ceneo.pl),
- portale agregujące oferty o prace mogą pobierać informacje o nowych ofertach pracy z innych źródeł,
- portale o nieruchomościach mogą pobierać dane o nowo powstałych projektach inwestycyjnych,
- itd.

Czym web scraping różni się od indeksowania (ang. web crawling)?
Indeksowanie sieci to czynność polegająca na automatycznym pobieraniu danych ze strony internetowej i wyodrębnianiu zawartych w niej hiperłączy potocznie zwanych linkami. Pobrane dane są zwykle przechowywane w indeksie lub bazie danych, aby można je było łatwo przeszukiwać.
Było to pierwotnie podstawowe zadanie wyszukiwarki Googla :). Zatem przy samym scrapowaniu stron często w pierwszym kroku wyodrębnia się linki, z których można następnie pobierać konkretne dane.
Więc jak działa web scraping?
Skrobiąc (choć wolę z angielskiego mówić „skrapując”) stronę tak naprawdę piszemy kod, który wysyła żądanie do serwera, na którym znajduje się wskazana przez nas strona. Ogólnie nasz kod co napisaliśmy pobiera kod źródłowy strony, dokładnie tak samo jak robiłaby to przeglądarka. Zamiast jednak wyświetlać stronę, filtruje ją w poszukiwaniu elementów HTML, które określiliśmy, i wyodrębnia zawartość, którą poleciliśmy wyodrębnić.
Na przykład, gdybyśmy chcieli pobrać wszystkie tytuły zawarte w tagach H3 (np. ten tytuł „Więc jak działa web scraping” ma taką wielkość) z tej strony z artykułem, moglibyśmy napisać odpowiedni kod. Nasz kod zażądałby zawartości witryny z serwera i ją pobrał. Następnie przeszukiwał kod HTML strony w poszukiwaniu tagów H3. Za każdym razem, gdy znalazł tag H3, kopiował tekst znajdujący się wewnątrz tagu i wyświetlał go w dowolnym określonym przez nas formacie.
Pamiętaj o tym, że z punktu widzenia serwera żądanie strony za pomocą scrapingu jest tym samym, co załadowanie jej w przeglądarce internetowej. Kiedy używamy kodu do przesyłania tych żądań, najczęściej otwieramy strony znacznie szybciej niż zwykły użytkownik, a tym samym szybko możemy pochłaniać zasoby serwera właściciela witryny.

Dlaczego web scraping często jest postrzegany negatywnie?
Reputacja skrobania stron internetowych znacznie się pogorszyła w ciągu ostatnich kilku lat. Wynika to głównie z tego, że głównym celem jest uzyskanie przewagi konkurencyjnej i zarobieniem dodatkowych $$$ na cudzych danych.
Niestety często lekceważy się prawa autorskie czy ogólne warunki korzystania z usługi (Term of Service – ToS). Ponadto często użytkownicy wysyłają zbyt dużo żądań na sekundę powodując w ten sposób nieoczekiwane obciążenie witryn internetowych.

Więc czy jest to legalne czy nielegalne?
Skrobanie i przeszukiwanie sieci nie jest same w sobie nielegalne. Zawsze przecież bez problemu możesz zeskrobać lub przeszukać własną witrynę internetową, prawda? Natomiast troszkę należy uważać pobierając dane z innej strony internetowej.
Jeśli będziesz trzymał się poniższego punktu 2, 3, 4 oraz 6 to w 99% to, co zrobisz będzie legalne!

7 „dobrych” praktyk!
1. Wykorzystuj API
Nie ma sensu wyważać otwartych drzwi. Jeśli dana strona czy usługa udostępnia API do pobrania danych to wykorzystuj ją! Dla przykładu tutaj dokumentacja API Allegro.
2. Przestrzegaj zapisów z robots.txt
Pierwszą rzeczą, którą należy sprawdzić, zanim zaczniesz web scraping danej strony internetowej, jest sprawdzenie pliku robots.txt. Plik ten służy do komunikacji z robotami internetowymi i informuje robota internetowego, które obszary witryny nie powinny być przetwarzane ani skanowane.
Plik robots.txt powinien zawsze znajdować się w katalogu głównym hierarchii witryn internetowych, na przykład:

Plik robots.txt określa również, co jest uważane za dobre zachowanie na danej witrynie internetowej i może mówić o ograniczeniach częstotliwości odpytywania.
Jak go czytać? Patrząc na „Disallow” możesz zobaczyć, jakich podstron nie można scrapować. Dla przykładu:
Disallow: /
oznacza, że nie masz prawa nic scrapować!
Pamiętaj! Jak nie ma pliku to nie znaczy, że można scrapować do woli! Ważne są jeszcze pozostałe punkty i przede wszystkim zdrowy rozsądek. Dzięki za zwrócenie uwagi: Adrianowi & Michałowi z grupy Data Science PL!
3. Przestrzegaj warunków korzystania z usługi
Drugą rzeczą, którą warto wykonać jest przejrzenie warunków korzystania z usługi (ang. Term of Service – TOS) czy portalu. Moim zdaniem plik robots.txt i „Warunki użytkowania” witryny (czy czasami usługi) powinny być ze sobą spójne. Dlaczego? Najczęściej żadny robot nie analizuje „Warunków korzystania” (jeszcze, bo GPT-3 może rozwiązać w pewnym aspekcie ten problem :)).
Zobacz dla przykładu, że w warunkach map Googla wprost napisane, by nie kopiować treści i pobierać masowo danych!
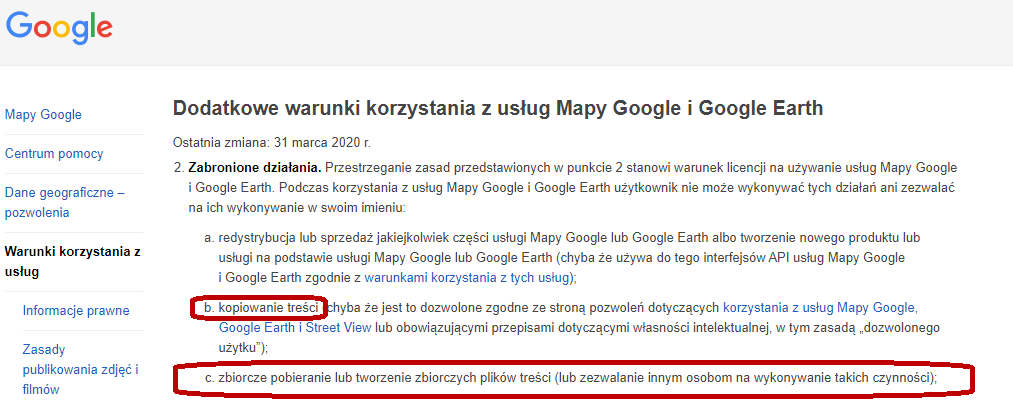
4. Nie naruszaj RODO!
Mieszkamy w Polsce należącej do Unii Europejskiej. Zatem należy również zachować zgodność z rozporządzeniem o ochronie danych UE zwanym potocznie RODO. Jeśli nie scrapujesz danych osobowych, RODO nie ma żadnego zastosowania.
Dane osobowe to wszelkie dane, które mogą zidentyfikować osobę:
- Imię i nazwisko,
- E-mail,
- Numer telefonu,
- Adres,
- Nazwa użytkownika (np. loginy),
- Adres IP,
- Informacje o numerze karty kredytowej czy debetowej,
- Dane medyczne lub biometryczne.
O ile nie masz „legalnego powodu”, aby scrapować i przechowywać te dane, to naruszasz RODO! W przypadku web scrapingu występują najczęściej dwa powody do przechowywania takich danych:
a) uzasadniony interes – w tym przypadku musimy udowodnić, że przetwarzanie jest niezbędne do celów wynikających z naszego prawnie uzasadnionego interesów, jednak nie dotyczy to sytuacji, w których nadrzędny charakter wobec tych interesów mają interesy lub podstawowe prawa i wolności osoby, której dane chcemy przetwarzać. Wydaje mi się, że ciężko zwykłej firmie byłoby uzasadnić ten cel (jak znasz taki przypadek to daj znać a podzielimy się nim tutaj!)
b) zgoda klienta – aby była prawnym powodem do pobierania i zbierania danych osobowych, to musisz mieć zgodę tej osoby na pobieranie, przechowywanie i wykorzystywanie jej danych w sposób, w jaki zamierzasz i w celu, w jakim chcesz te dane przetwarzać. Mówiąc wprost powinieneś uzyskać taką zgodę od konkretnej osoby, której dane chcesz przetwarzać. Troszkę ciężkie 🙂
Ciekawostka! RODO to rozporządzenie dla krajów Unii Europejskiej. Zatem nie ma zastosowania, jeśli pobierasz dane osobowe mieszkańców innych krajów: na przykład USA, Afganistanu czy Japonii. Te kraje mają swoje przepisy, ale pewnie nie tak restrykcyjne jak RODO.

Pamiętaj! Każdy projekt to inna sytuacja. Jeśli masz wątpliwości wówczas skonsultuj się z prawnikiem!
5. Nie szkodź stronie!
Twoja ilość i częstotliwość zapytań nie powinna obciążać serwerów serwisu ani zakłócać normalnego działania strony. Zwróć uwagę, że większe serwery, które mają mnóstwo zapytań w ciągu sekundy. Wtedy możesz spokojnie potraktować go wieloma zapytaniami (np. stronę Wikipedii). Natomiast, gdybyś chciał np. scrapować mój blog, to przy większej częstotliwości niż kilkaset zapytań w sekundę strona zostanie mocno spowolniona.
Aby nie szkodzić to:
- możesz skarpować stronę w nocy jak jest znacznie mniejszy ruch,
- dla mniejszych serwisów ogranicz liczbę równoczesnych żądań do tej samej witryny z jednego adresu IP,
- a dla bardzo wolnych stron zrób drobne opóźnienie między każdym zapytaniem.
Oczywiście, jeśli bardzo zależy Ci na ściągnięciu danych i jesteś blokowany to możesz wykorzystać różne tricki (np. losowe opóźnienia, zmiany adresów IP itp.). Jednak ja takich metod nie pochwalam i nie będę ich opisywał :P.
6. Nie naruszaj praw autorskich!
Prawa autorskie definiuje się jako wyłączne prawo do fizycznego dzieła takiego jak artykuł, zdjęcie, film, utwór, itp. Jeśli je stworzysz, jesteś jego właścicielem. Zatem prawa autorskie są bardzo istotne dla web scrapingu, bo jak widzisz wiele danych w internecie to dzieła chronione prawem autorskim (np. ten artykuł:P).
Istnieją jednak wyjątki, w których można scrapować do woli, a następnie legalnie wykorzystywać dane bez naruszania praw autorskich, np.:
- na własny użytek publiczny,
- w celach dydaktycznych lub w celu prowadzenia działalności naukowej,
- w ramach prawa do cytatu.
A gdybyś chciał konkrety, to najlepszy prawnik, jakiego znam (moja siostra Natalia) powiedziała, że podstaw prawnych należy przede wszystkim szukać w Ustawie o prawie autorskim i prawach pokrewnych, jednak każdy przypadek jest inny, zależy od źródła danych, ich charakteru, sposobu wykorzystania, zakresu rozpowszechniania.
Ciekawostka! W różnych krajach obowiązują różne wyjątki od praw autorskich!
7. Nie ukrywaj się
Moim zdaniem dobrą praktyką jest identyfikowanie się, gdy jest to możliwe. Na przykład korzystając z pakietu Scrapy można zdefiniować to poprzez podanie w zmiennej USER_AGENT swojego adresu mailowego. Dzięki temu administrator strony w razie problemów może Cię o tym poinformować.

Podsumowanie
Zamiast tych wszystkich zasad mogłem napisać tak naprawdę jeden punkt: zdrowy rozsądek! Mam nadzieję, że nigdy Ci go nie zabraknie.
Pozdrawiam serdecznie,

Image by James Osborne from Pixabay



Pingback: 30 miliardów zdjęć z FB przekazanych policji przez AI
Hmm, właśnie szukam „legalnego” sposobu na scrapowanie pewnych treści i w regulaminie allegro (https://developer.allegro.pl/rules/) jest punkt. 4.1 e, który jednoznacznie zabrania scrapowania. Więc udostępnianie REST API nie pozwala na to jednoznacznie, niestety 🙁
No niestety:(. W sumie w dzisiejszych czasach najcenniejszą rzeczą oprócz czasu jest informacja i dane. Więc rozumiem, dlaczego większe firmy starają się ich strzec 🙂
„Googla wprost napisane, by nie kopiować treści i pobierać masowo danych”
Google, i inni, moga sobie wiele mówic. Kazdy regulamin ktory definiuje wiecej niz prawo, mozna zawiesic w toalecie.
Jesli cos jest publiczne, mozesz to pobrac nawet jak ktos sobie umiesci „w regulaminie” ze nie mozna.
Hej, zgadzam się że jest możliwość pobrania. Jednak w żaden sposób nie możesz tych danych zmonetynować w legalny sposób 🙂
Pingback: Oszustwo na InPost dostawę - Logistyka po prostu
Bardzo dobrze napisane, jasno i do rzeczy!
A jeśli ktoś jest zainteresowany detalami od strony prawnej, polecam ten artykuł (niestety po angielsku): https://discoverdigitallaw.com/index.php/2021/05/22/is-web-scraping-legal-short-guide-on-scraping-under-the-eu-jurisdiction/ .
Cześć 🖐 ,
Bardzo fajny artykuł 👏. Dużo dobrej i potrzebnej wiedzy. A czy Ceneo scrapuje dane z innych witryn?
Wydaje mi się że tak ponieważ Ceneo to taka porównywarka i wyszukiwarka najniższej ceny za dany produkt więc jak by mieli inaczej pozyskać te dane jak nie poprzez web scrapping.
Napisałeś, Mirku, że pobieranie danych o produktach, ich cech, atrybutów itp. jest legalne i można to robić. Wydaje mi się że masz rację. Skoro program web scrappingu pobiera stronę internetową w ten sam sposób jakby robił to człowiek poprzez przeglądarkę to nie wiedzę tu żadnego problemu.
Dane o produkcie nie są chronione prawem autorskim ani żadnym innym. Czy mam rację 🧐?
Btw. Od kiedy stosuje się w ogóle techniki web scrappingu? Kiedy to powstało? Wiem że Google istnieje od 199x- któregoś więc być może to Google wymyśliło te techniki, ale nie wiem. Jak to jest?
Pozdrawiam 👋.
Hej Mateusz!
Dziękuję 🙂 Również uważam jak Ty, że tak działa Ceneo. Natomiast zawsze można wyszukać kogoś na LinkedIn i spytać wprost 😀
Odnośnie danych o produkcie to wydaje mi się, że nie są chronione. Natomiast zdjęcia już mogą jak najbardziej być!
A odnośnie pierwszego scrapera to angielska Wiki pisze, że „first web robot,[1] World Wide Web Wanderer, was created in June 1993„. Zatem ślicznie trafiłeś 😀
Pozdrawiam serdecznie,
Mirek
Ceneo w żadnym wypadku nie scrapuje danych – dane są udostępniane w plikach przesyłanych przez sprzedawców – powód?
Ceneo pobiera pieniądze za każde kliknięcie powodujące przekierowanie do danego sklepu.
Więc jest to nic innego, a nie żeli zwykły biznes.
Pingback: BeautifulSoup, czyli jak prosto scrapować HTML - Mirosław Mamczur