
Wykres Sankeya (często również nazywany diagramem Sankeya lub wykresem strumieniowym) to jedna z technik wizualizacji, która umożliwia wyświetlenie przepływów i ich wielkości proporcjonalnie do siebie.
A dlaczego wykres ten nazwano Sankeya?
Nazwa została zaczerpnięta od nazwiska kapitana Matthew Sankey’a (1853-1925), który był irlandzkim mechanikiem i kapitanem w Corps of Royal Engineers. Prowadził on badania nad zwiększeniem sprawności silników parowych. I właśnie w artykule z 1898 roku na temat sprawności zostały po raz pierwszy zamieszczone wykresy strumieniowe.
Natomiast warto wspomnieć, że według niektórych źródeł twórcą wykresu strumieniowego był Charles J. Minard! Podobno w 1869 roku stworzył podobny wykres prezentujący zmiany liczebności armii Napoleona w czasie.

Na czym polega wykres Sankeya?
Szerokość strzałek służy do zaprezentowania wielkości danych. Czyli im szersza strzałka, tym większa wielkość przepływu. Strzałki lub linie przepływu mogą łączyć się ze sobą lub rozdzielać na każdym etapie procesu.
Dodatkowo można bawić się kolorami w celu podzielenia diagramu na różne kategorie lub aby pokazać przejścia z jednego stanu procesu do drugiego.
Poniżej przykład jak wygląda przepływ (pozyskanie do dystrybucji) energii:

Najczęstsze błędy:
- Nie pokazuj wykresu dla wielu małych liczności. Zbyt wiele danych sprawi, że Twój wykres będzie mało czytelny.
- Super, jeśli liczba skrzyżowań między łączeniami będzie jak najmniejsza. Na szczęście w pakiecie plotly jest to zoptymalizowane!
- W przypadku małej liczby grup rozważ inne wykresy, jak na przykład prosty wykres kolumnowy per każda grupa jak wygląda przepływ.
Kod w python!
Sam wykres w języku Python przy wykorzystaniu pakietu plotly jest prosty do zaimplementowania. Natomiast przy pierwszym jego stworzeniu wyzwaniem było dla mnie przygotowanie danych.
Dlatego specjalnie dla Ciebie przyszykowałem je w ten sposób, by łatwiej było zrozumieć, jak należy je przygotować! Możesz pobrać je TUTAJ.
Dane przedstawiają przepływ klientów z grup ryzyka (czyli jaka jest szansa, że klient nie spłaci kredytu) w kolejnych miesiącach. Dla uproszczenia miesiąc ustawiłem w nawiasie, np. (1) oznacza po 1 miesiącu. Ponadto możecie zauważyć, że dla pierwszego miesiąca jest tylko jedna grupa „Very High Risk„, Wynika to z tego, że celem jest spojrzenie jak wygląda przepływ klientów w tej grupie w czasie.
import pandas as pd
import plotly.graph_objs as go
df_sankey = pd.read_csv('sankey_example.csv', sep=";")
df_sankey.head()
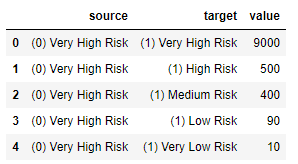
Dane są przygotowane w trzech kolumnach:
- source – jest to początek przepływu (strzałki),
- target – to jest koniec przepływu (strzałki), który wystartował z punktu „source„,
- value – jest to wartość przepływu, czyli jaka będzie końcowa wartość przepływu po dotarciu z punktu „source” do „target„.
Mam nadzieję, że struktura danych jest dla Ciebie w miarę jasna. Teraz musimy jedynie zamienić opis pola w liczby, gdyż w ten sposób przekazujemy dane w plotly.
label_list = ['(0) Very High Risk',#kolumna 1 (czyli miesiąc 0)
'(1) Very High Risk', '(1) High Risk', '(1) Medium Risk', '(1) Low Risk',
'(1) Very Low Risk', #kolumna 2, czyli miesiąc -1
'(2) Very High Risk', '(2) High Risk', '(2) Medium Risk', '(2) Low Risk',
'(2) Very Low Risk' ] #kolumna 3, czyli miesiąc -2
# przypisanie odpowiednich ID, by wykres wiedział jak narysować przepływ
df_sankey['sourceID'] = df_sankey['source'].apply(lambda x:
label_list.index(x))
df_sankey['targetID'] = df_sankey['target'].apply(lambda x:
label_list.index(x))
# sortowanie
df_sankey.sort_values(by = ['source','target'])
df_sankey.head()

Teraz dla ładniejszego efektu zdefiniujmy jeszcze listę kolorów:
#słownik kolorów 5 miar ryzyka, który lubię stosować :)
COLORS_DICT = {
'risk_grade': {'Very High Risk':'rgb(190,0,0)',
'High Risk':'rgb(255,190,0)',
'Medium Risk':'rgb(255,255,0)',
'Low Risk':'rgb(140,200,80)',
'Very Low Risk':'rgb(0,175,80)',
},
}
#tworzymy listę kolorami :)
color_list = [COLORS_DICT['risk_grade'][col[4:]] for col in label_list]
i możemy stworzyć wykres!
data=[go.Sankey(
node = dict(
pad = 10,
thickness = 50,
line = dict(color = "black", width = 0.5),
label = label_list,
color = color_list
),
link = dict(
source = df_sankey['sourceID'],
target = df_sankey['targetID'],
value = df_sankey['value']
))]
layout = go.Layout(title={'text': f"""<b>Przepływ klienów do grupy
wysokiego ryzyka kredytowego </b>
<br> (dane spreparowane :P)""", 'y': 0.9, 'x': 0.5})
fig = go.Figure(data=data, layout=layout)
fig.add_annotation(text="2020 wrzesień", x=-0.05, y=-0.1, showarrow=False)
fig.add_annotation(text="2020 sierpień", x=0.5, y=-0.1, showarrow=False)
fig.add_annotation(text="2020 lipiec", x=1.0, y=-0.1, showarrow=False)
fig.show()

I to wszystko! Miłego rysowania przepływów 🙂
Pozdrawiam serdecznie,




Pingback: #022 Wykres sunburst - Mirosław Mamczur