
Wykres kolumnowy (ang. bar plot/ bar chart / column graph) jest jednym z najczęściej używanych wykresów na całym świecie. Służy głównie do porównania wartości między kategoriami.
Jedna oś wykresu pokazuje porównywane kategorie, druga oś reprezentuje skalę wartości i odpowiada na pytanie „ile?” dla każdej kategorii.
Wykresy kolumnowe stosujemy zazwyczaj w sytuacjach, gdy chcemy:
- podkreślić różnice,
- pokazać trendy i wartości odstające,
- przedstawić historyczne minima i maksima.
Ponadto wykresy te są szczególnie przydatne, kiedy chcemy pokazać jednocześnie kilka kategorii, np. ilość zjadanych warzyw czy procent wydatków w różnych obszarach.
Wykresy kolumnowe są podobne do histogramów, ale różnią się od nich tym, że nie wyświetlają ciągłych zmian w przedziale.
Jedną z wad wykresów kolumnowych jest to, że etykietowanie staje się problematyczne w przypadku występowania dużej liczby kolumn. Wówczas wykres może stać się nieczytelny.
Również powszechnym błędem jest nadużywanie wykresów kolumnowych do pokazywania średniej wartości każdej grupy. W przypadku zróżnicowanych danych lepszym rozwiązaniem może okazać się wykorzystanie wykresu pudełkowego (boxplot) .
Kolumny można rysować pionowo oraz poziomo (horyzontalny). Zazwyczaj poziome ułożenie kolumn stosuje się w przypadku dłuższych etykiet danych, dzięki czemu wykresy są bardziej czytelne.
Kod w Python
Wykres ten jest na tyle popularny, że występuje we wszystkich bardziej znanych bibliotekach do wizualizacji: matplotlib, seaborn, bokeh, plotly.
Poniżej przykładowe wykresy na podstawie biblioteki matplotlib.
import numpy as np
import matplotlib.pyplot as plt
a) wykres kolumnowy
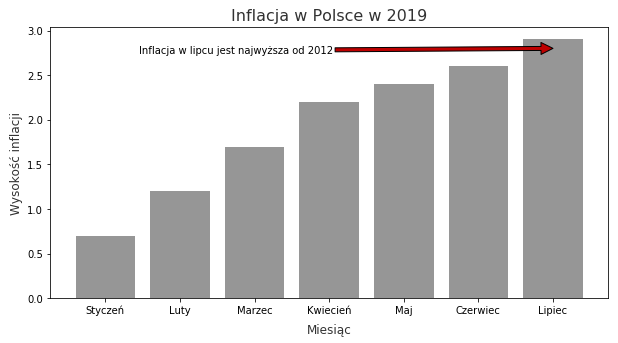
Dane do przykładowego wykresu pochodzą z Głównego Urzędu Statystycznego i dotyczą inflacji w Polsce w 2019 roku.
# Make a dataset:
height = [0.7, 1.2, 1.7, 2.2, 2.4, 2.6, 2.9]
bars = ('Styczeń', 'Luty', 'Marzec', 'Kwiecień', 'Maj', 'Czerwiec', 'Lipiec')
y_pos = np.arange(len(height))
#Figsize
plt.figure(figsize=(10,5))
# Create bars
plt.bar(y_pos, height, color = '#969696')
# Create names on the x-axis
plt.xticks(y_pos, bars)
plt.xlabel('Miesiąc', fontsize=12, color='#323232')
plt.ylabel('Wysokość inflacji', fontsize=12, color='#323232')
plt.title('Inflacja w Polsce w 2019', fontsize=16, color='#323232')
plt.annotate('Inflacja w lipcu jest najwyższa od 2012', xy=(6, 2.8), xytext=(0.45, 2.75),
arrowprops=dict(facecolor='#be0000'),
)
# Show graphic
plt.show();
b) horyzontalny wykres kolumnowy
W tym przypadku wykorzystałem dane o liczbie klientów bankowości korzystających z aplikacji mobilnych na podstawie raportu PRnews.
# Make a dataset:
height = [49666,76768,99330,132818,139376,149168,210744,301938,1059000,1288936,1514563,1835000,2009455,2910247,]
bars = ('Plus Bank','TMUB','ex-Raiffeisen (BNP Paribas)','eurobank','Credit Agricole','Citi Handlowy','BNP Paribas',
'Alior Bank','Bank Millennium','Bank Pekao','Santander Bank Polska','ING Bank Śląski','mBank','PKO BP')
y_pos = np.arange(len(height))
#Figsize
plt.figure(figsize=(10,10))
# Create bars
plt.barh(y_pos, height, color = '#969696')
# Create names on the x-axis
plt.yticks(y_pos, bars)
plt.xlabel('Liczba użytkowników logujących się minimum raz w miesiącu', fontsize=12, color='#323232')
plt.title('Liczba użytkowników bankowości mobilnej – I kw. 2019', fontsize=16, color='#323232')
# Show graphic
plt.show();

c) dwie serie danych
Chciałem Wam jeszcze pokazać, jak można przedstawić dwie nakładające się serie danych, aby się przez siebie przenikały. Wykorzystałem dane z jednego modelu z pracy, abyście mieli możliwość zobaczenia, jak różnicowani są klienci na dobrych i złych.
procent_bads = [0.201,0.158,0.126,0.108,0.084,0.068,0.058,0.043,0.035,0.028,0.024,0.018,0.013,0.011,0.009,0.006,0.004,0.003,0.002,0.001]
procent_goods = [0.008,0.020,0.029,0.034,0.041,0.045,0.048,0.052,0.054,0.056,0.057,0.059,0.060,0.061,0.061,0.062,0.063,0.063,0.063,0.064]
bars = (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20)
plt.figure(figsize=(15, 7))
plt.bar(bars, procent_bads, color = 'red', alpha=0.5, label = 'Bads')
plt.bar(bars, procent_goods, color = 'green', alpha=0.5, label = 'Goods')
plt.xticks(bars, bars)
plt.legend(frameon=False)
plt.xlabel('Populacja równolicznie podzielona na 20 grup')
plt.ylabel('% klientów')
plt.title('Rozkład procentowy bad vs good na próbce walidacyjnej');

Pozdrawiam serdecznie,




Pingback: #007 Histogram - Mirosław Mamczur
Wykres dot. inflacji w tej chwili mógłby być jeszcze ciekawszy 😀
Teraz to w ogóle by był ciekawy XDD
A na początku 2025 taki wykres byłby jeszcze bardziej ciekawy
Pingback: #021 Wykres lizakowy (Lollipop chart) - Mirosław Mamczur
Pingback: #017 Wykres kołowy (Pie Chart) - Mirosław Mamczur
Pingback: #015 Wykres Gantta (Gantt chart) - Mirosław Mamczur
Pingback: #013 Wykres Sankeya (Sankey Diagram) - Mirosław Mamczur
Pingback: #012 Wykres bąbelkowy (bubble chart) - Mirosław Mamczur
Pingback: #10 Wykres radarowy - Mirosław Mamczur
Pingback: #007 Histogram (histogram) - Mirosław Mamczur