
– Tato, co dzisiaj robiłeś?
– Starałem się lepiej zrozumieć model, który zbudowaliśmy w pracy.
– A po co? – spytała Jagódka
– By rozumieć dlaczego podejmuje taką decyzję a nie inną.
– Ale po co to zgłębiać skoro działa?
– Ponieważ chciałem umieć wyjaśnić jego decyzje i czy nie podejmuje ich na przykładzie niezrozumiałych elementów. Hmm… – zastanowiłem się jakby to wyjaśnić Jagódce – Twoja siostrzyczka Otylka nie może jeść pszenicy, prawda?
– Zgadza się. Na przykład mąki, albo ciasteczek. Ale może czekoladę – uśmiechnęła się Jagoda.
– Aha. A gdy idziemy do restauracji zawsze proszę o informacje o składzie dania. Nawet jakby kucharz i kelnerzy w restauracji mówili, że danie jest przepyszne, każdemu smakuje i nikt nigdy na nie nie narzekał i tak chciałbym poznać skład dań by wiedzieć, czy nie zaszkodzę Otylce. Po to właśnie chcę zrozumieć modele Kochanie.
Zastanawialiście się kiedyś czy Wasz model jest łatwy do zrozumienia (jest interpretowalny)?
Na co dzień pracując w banku Santander chcę dobrze rozumieć skomplikowane algorytmy uczenia maszynowego nazywane przez wiele osób „czarnymi skrzynkami”. Oprócz tego, że model bardzo dobrze działa na różnych podpopulacjach i jest stabilny w czasie warto wiedzieć co kryje się w środku. Tak jak w powyższej historii można to porównać do składu jedzenia jakiegoś dania. Jak wszystkim smakuje to super, ale czasami warto wiedzieć co jest w środku i czy nikomu nie szkodzimy. Tym jest dla mnie interpretowalność modeli.
Jest wiele bibliotek, które zapewniają nam lepsze zrozumienie modeli drzew, lasów, gradient boostingów czy sieci. Jednymi z takich bibliotek są:
- SHAP: https://github.com/slundberg/shap
- LIME: https://github.com/marcotcr/lime
- ELI5: https://github.com/TeamHG-Memex/eli5
W tym artykule wyjaśnię Wam czym jest wartość Shapleya oraz jak możecie wykorzystać bibliotekę SHAP.
Czym jest wartość Shapley’a?
Nie tak dawno temu, za siedmioma górami i siedmioma morzami żył sobie amerykański matematyk Lloyd Shapley. Zajmował się przede wszystkim teorią gier. W 2012 dostał nagrodę Nobla w dziedzinie ekonomii choć sam mówił o sobie, że jest matematykiem i na ekonomii się nie zna :). Niemniej jednak w 1953 roku w ramach teorii gier wymyślił wartość, która została nazwana jego imieniem.
Wartość Shapley’a to metoda przypisywania zysku pomiędzy graczy w zależności od ich wkładu w całkowitą grę. Gracze współpracują ze sobą w koalicji i czerpią z niej pewien zysk. Intuicyjnie można powiedzieć, że wartość Shapley’a mówi ile dany gracz powinien spodziewać się zysku z całości biorąc pod uwagę jaki średnio ma wkład w grze w danej koalicji.
Jak ją prosto zrozumieć?
Załóżmy, że Mirek, Jagoda i Otylka idą jeść do restauracji (to chyba dopiero za kilka lat, bo sam bez żony w knajpce bym ich nie okiełznał :)).

Załóżmy, że mamy poniższe możliwości. Gdyby
- Mirek jadł sam zapłaciłby 80 pln
- Jagoda jadła sama zapłaciłaby 25 pln
- Otylka jadła sama zapłaciłaby 20 pln
- razem Mirek & Jagoda wydaliby 100 pln
- razem Mirek & Otylka wydaliby 85 pln
- jedząc razem Otylka & Jagoda wydałyby 60 pln
- Wszyscy razem: 100 pln.
Zamawiamy wspólnie jedząc zapłacilibyśmy równo 100 pln. Ale ktoś zjadł więcej, ktoś mniej więc jak ustalić ile kto powinien zapłacić za jedzenie ze swojej kieszeni (w sumie tata wszystko, ale dodajmy kolejne założenie, że dziewczynki mogą same zapłacić :))?
Zatem zgodnie z teorią Shapley’a bierzemy kolejno wszystkie permutacje uczestników i patrzymy na przyrostową wypłatę. Gdybyśmy płacili najpierw w kolejności (Mirek, Jagoda, Otylka) to najpierw Mirek płaci 80 pln. Następnie para (Mirek, Jagoda) płaci 100, czyli Jagoda dorzuca 20 pln do puli. Zapłaciliśmy za całość, więc Oti płaci 0 pln.
Powtarzamy to ćwiczenie dla wszystkich permutacji otrzymując wyniki:
- (Mirek, Jagoda, Otylka) = (80, 20, 0)
- (Mirek, Otylka, Jagoda) = (80, 5, 15)
- (Jagoda, Otylka, Mirek) = (25, 35, 40)
- (Jagoda, Mirek, Otylka) = (25, 75, 0)
- (Otylka, Mirek, Jagoda) = (20, 65, 15)
- (Otylka, Jagoda, Mirek) = (20, 40, 40)
Wartość Shapley’a to wartość średnia, czyli odpowiednio dla:
- Mirka: (80+80+40+75+65+40)/6 = 63.333
- Jagódki: (20+15+25+25+15+40)/6 = 23.333
- Oti: (0+5+35+0+20+20)/6 = 13.333
W sumie daje to razem 100 pln!!

Jak wykorzystać wartość Shapley’a w uczeniu maszynowym?
Jak to się ma do uczenia maszynowego? Tak naprawdę naszą grą jest predykcja naszego modelu dla danych wejściowych. Wypłatą jest różnica z predykcji modelu i wartości średniej. Gracze to charakterystyki (cechy) modelu. A koalicja to zestaw charakterystyk.
Dla lepszego zrozumienia przygotujmy przykład. Załóżmy, że zbudowaliśmy model, który przewiduje cenę mieszkania we Wrocławiu na podstawie kilku cech: metraż, rok budowy, dzielnica.

Niech model dla danych: 40m2, roku budowy 1920 i dzielnicy „Stare miasto” zwróci cenę 500.000. Średnia cena dla wszystkich mieszkań w próbie wynosi 450.000. Widać, że cena jest o 50.000 wyższa od średniej. Naszym celem jest właśnie wyjaśnienie skąd wynika ta różnica 50.000.
Odpowiedzią mogłoby być, że rok budowy wpłynął na minus -20.000 natomiast dzielnica na + 70.000, a metraż bez wpływu.
Szukając wartości dla charakterystyki szukamy wszystkich podzbiorów nie zawierających tej cechy. Następnie dodajemy tą charakterystykę do każdego podzbioru i sprawdzamy wpływ dodania cechy do modelu. Sumując wyniki otrzymujemy coś na kształt wartości Shapley’a. Na szczęście całość została już przygotowana i opisana dość szczegółowo w bibliotece SHAP.
Biblioteka SHAP
SHAP (SHapley Additive exPlanations) jest biblioteką wykorzystującą w praktyczny sposób podejście z teorii gier do wyjaśnienia wyniku dowolnego modelu uczenia maszynowego. Scott Lunberg (https://github.com/slundberg) udostępnił pierwszą wersję w 2016. Scott z zespołem opracował optymalną metodę alokacji kredytu wykorzystującą klasyczne wartości Shapley’a z teorii gier i powiązanych z nimi rozszerzeń (wszystkie szczegółowe informacje i cytowania znajdują się w dokumentacji biblioteki) do wyjaśniania modeli.

Przykład w Python
Teraz pokażę Wam jak łatwo można wykorzystać bibliotekę SHAP. Najpierw musimy przygotować dane i zbudować szybko model.
Rozpocznijmy od wczytania bibliotek:
import pandas as pd
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as mse
Dane
Jako dane wykorzystamy ceny nieruchomości z Bostonu. Dane możecie pobrać z Kaggle albo wpisując w Google: „boston dataset”.
Wczytajmy najpierw zbiór i zobaczmy jak wygląda:
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df = pd.read_csv('../data/housing.csv', header=None, delimiter=r"\s+", names=column_names)
df.head(3)

Zbiór składa się z 14 zmiennych:
- CRIM – wskaźnik przestępczości na mieszkańca według miasta
- ZN – część działki pod zabudowę mieszkaniową pod działki o powierzchni ponad 25 000 stóp kwadratowych
- INDUS – odsetek niedetalicznych akrów biznesowych na miasto.
- CHAS – zmienna zmienna Charles River (1, jeśli trasa ogranicza rzekę; 0 w przeciwnym razie)
- NOX – stężenie tlenków azotu (części na 10 milionów)
- RM – średnia liczba pokoi na mieszkanie
- AGE – odsetek jednostek zajmowanych przez właścicieli wybudowanych przed 1940 r
- DIS – ważone odległości do pięciu centrów zatrudnienia w Bostonie
- RAD – indeks dostępności do radialnych autostrad
- TAX- pełna stawka podatku od nieruchomości od 10 000 USD
- PTRATIO – stosunek liczby uczniów do nauczycieli według miasta
- B – 1000 (Bk – 0,63) ^ 2, gdzie Bk to odsetek czarnych według miasta
- LSTAT -% niższy status populacji
- MEDV – Mediana wartości domów zajmowanych przez właścicieli w tysiącach dolarów
Narysujmy kilka przykładowych wykresów by odrobinkę rozpoznać dane. Zacznijmy od wykresów pudełkowych:
fig, axs = plt.subplots(ncols=7, nrows=2, figsize=(10, 5))
index = 0
axs = axs.flatten()
for k,v in df.items():
sns.boxplot(y=k, data=df, ax=axs[index])
index = index + 1
plt.tight_layout()

Od razu można zauważyć, które kolumny mają wartości odstające. Spójrzmy w podobny prosty sposób jeszcze na wykresy gęstości (rozkłady):
fig, axs = plt.subplots(ncols=7, nrows=2, figsize=(10, 5))
index = 0
axs = axs.flatten()
for k,v in df.items():
sns.distplot(v, ax=axs[index])
index = index + 1
plt.tight_layout()
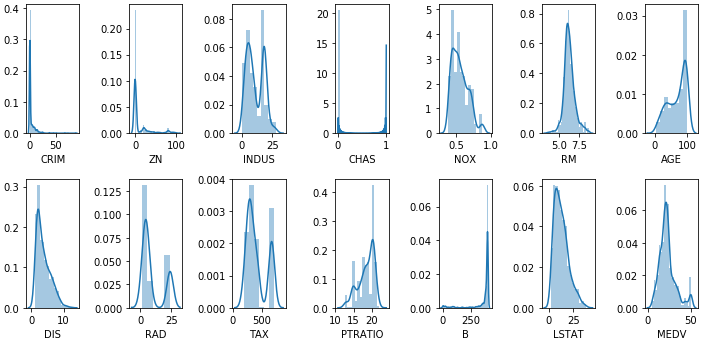
Rozkłady pokazują istnieją kolumny (CRIM, ZN, B), które mają bardzo”ukośne” [LINK] rozkłady. Nasza zmienna celu (MEDV) wygląda że ma w miarę rozkład normalny. Pozostałe cechy również wydają się mieć rozkład normalny lub bimodelny (z wyjątkiem CHAS która jest dyskretny).
Budowa modelu
Zbudujmy teraz prosty model służący do przewidywania cen. Oczywiście model może być znacznie lepszy, niemniej celem tego wpisu jest wyjaśnienie jak go zinterpretować, więc nie koncentrowałem się na przygotowaniu odpowiednio na pracy nad charakterystykami, wybraniu najlepszego zestawu cech czy dobraniu optymalnego modelu z hiperparametrami.
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=1, test_size=0.25)
model = xgb.XGBRegressor(max_depth=3, n_estimators=250, colsample_bytree=0.75, seed=2020)
model.fit(X_train, y_train)
y_pred_val = model.predict(X_val)
y_pred_train = model.predict(X_train)
print(f'Błąd na próbce val: {mse(y_val, y_pred_val)}. Na train: {mse(y_train, y_pred_train)}')

Wczytanie biblioteki SHAP
Wczytujemy bibliotekę:
import shap
a teraz wystarczy utworzyć obiekt, który pomoże wyliczyć wartości Shapley’a:
explainer = shap.TreeExplainer(model)
Zwróćcie proszę uwagę, że w powyższym kodzie stworzyliśmy wartości SHAP na podstawie odwołania się do modeli drzewiastych poprzez funkcję shap.TreeExplainer (i tutaj nasz model). Ale pakiet SHAP zawiera wyjaśnienia dla prawie każdego typu modelu.
- shap.DeepExplainer – działa z modelami Deep Learning,
- shap.KernelExplainer – działa ze wszystkimi modelami, ale kosztem tego, że jest wolniejszy niż pozostałe „Explainers” i oferuje przybliżenie wartości Shapley’a.
Teraz obliczmy wartości shap_values dla wszystkich wartości naszego zbioru. W poniższym przykładzie wyliczyłem dla wartości zbioru walidacyjnego by na nim zinterpretować jak działają charakterystyki. UWAGA! poniższy kod może długo się przeliczać dla dużych zbiorów.
shap_values = explainer.shap_values(X_val)
print(f'Shape: {shap_values.shape}')
pd.DataFrame(shap_values).head(3)

Powyżej widzicie, że dla każdego wiersza (obserwacji) i charakterystyki (cechy) zostały wyliczone wartości shap (analogicznie jak w przykładzie z restauracją i moimi córeczkami). Teraz spróbujmy przygotować kilka wykresów i je zinterpretować.
Ogólna interpretowalność – wykres istotności
Pierwszym wykresem jest wykres z globalną interpretowalność. Sumaryczne wartości SHAP mogą pokazać, w jakim stopniu każda cecha przyczyniła się do przewidywania zmiennej docelowej.
Wykres ważności zmiennych zawiera listę najbardziej znaczących zmiennych w porządku malejącym. Górne charakterystyki wnoszą najwięcej do modelu. Im niżej tym słabsza cecha i mają mniejszą moc predykcyjną.
shap.summary_plot(shap_values, X_val,plot_type='bar')

Zatem dwoma najmocniejszymi zmiennymi w naszym modelu są LSTAT oraz RM a najsłabszymi ZN oraz CHAS.
Powyższy wykres można narysować pokazując dodatkowo pozytywne i negatywne relacje wartości ze zmienną docelową.
shap.summary_plot(shap_values, X_val)

Zwróćcie uwagę na to, że zachowana jest ta sama kolejność zmiennych na wykresie. On również pokazuje od najmocniejszej cechy do najsłabszej w modelu.
Każda kropka na wykresie reprezentuje jedną obserwacje na zbiorze danych (w moim przypadku walidacyjny). Ten wykres składa się ze wszystkich kropek w danych pociągu. Pokazuje następujące informacje:
- Kolor: pokazuje czy zmienna przyjmuje wysokie wartości (czerwony) czy niskie (niebieski) dla tej obserwacji.
- Położenie w poziomie: informuje czy wpływ tej wartości jest związany z wyższą prognozą czy niższą (wszystko na lewo od 0 wpływa negatywnie a wszystko na prawo pozytywnie).
- Rozkład kropek: dodatkowo można odczytać uproszczony rozkład zmiennej. Dużo kropek w jednym miejscu oznacza, że większość obserwacji jest w tym jednym miejscu.

Teraz zinterpretujmy LSTAT. Od razu można zwrócić uwagę , że niska wartość LSTAT ma duży pozytywny wpływ na wycenę nieruchomości. Wartość „HIGH” na wykresie przechodzi z czerwonego na niebieski.
Natomiast RM można powiedzieć, że jest odwrotnie skorelowane z ceną nieruchomości: im wyższa wartość tym wyższą cenę przewiduje model.
Pamiętajcie: wszystkie wartości po lewej stronie reprezentują obserwacje, które przesuwają przewidywaną wartość w kierunku ujemnym (czyli tutaj obniżają wartość nieruchomości), podczas gdy punkty po prawej stronie przyczyniają się do przesunięcia prognozy w kierunku dodatnim (tutaj zwiększają wycenę nieruchomości).
Ogólna interpretowalność – wykres zależności
Spójrzmy teraz na tzw. wykres zależności, który pokazuje czy istnieje jakiś związek między celem a obiektem, tzn. czy jest liniowy czy bardziej złożony. Powyższe wykresy dają nam zbiorcze ogólne informacje a wykresy zależności dają bardzo precyzyjną informację dla pojedynczej charakterystyki.
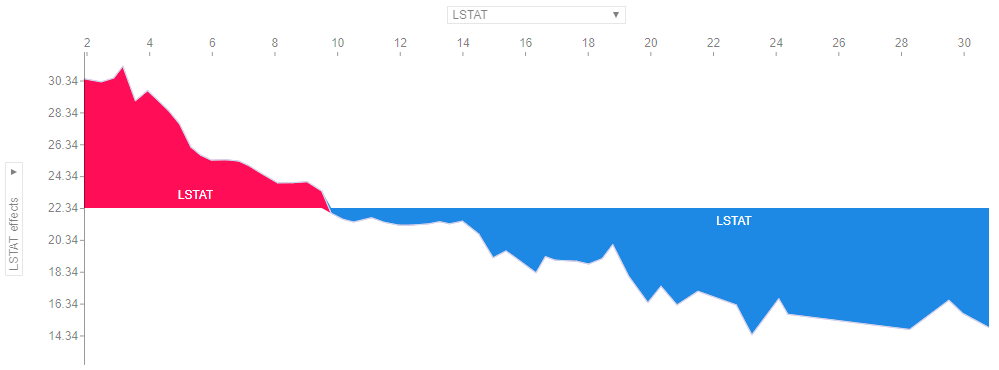
shap.dependence_plot('LSTAT', shap_values, X_val)
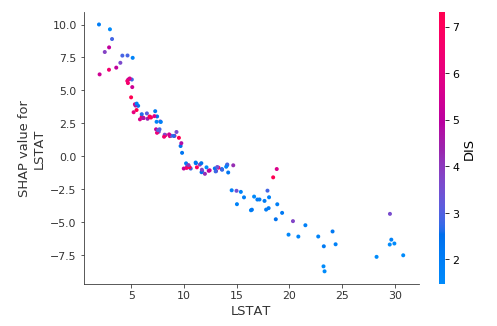
Każda kropka reprezentuje rząd danych. Położenie w poziomie to rzeczywista wartość z zestawu danych, a położenie w pionie pokazuje, co ta wartość miała dla prognozy. Fakt, że pochyla się w dół oznacza, że im wyższa wartość LSTAT to tym niższa wartość nieruchomości. I prosto można odczytać liniową zależność cechy LSTAT od zmiennej przewidywanej.
Dodatkowo automatycznie w tym przypadku dobierana jest inna zmienna najbardziej skorelowana z LSTAT. W tym przypadku jest to DIS. Kolory tutaj też odpowiadają za wartość obserwacji – tutaj zmiennej dobranej. Widzimy, że wyższe wartości zmiennej DIS są dla mniejszych wartości LSTAT.
Sprawdźmy jak wygląda druga najmocniesza cecha RM:
shap.dependence_plot('RM', shap_values, X_val)

Również tutaj zależność jest dość widoczna.
Lokalna interpretowalność – wykres dla pojedynczej obserwacji
Podczas przeliczania każda obserwacja otrzymała swój własny zestaw wartości SHAP. Dzięki temu dla każdej obserwacji możemy sprawdzić jak każda zmienna z modelu wpłynęła i w jakim stopniu na podjęcie takiej decyzji przez model. Możemy w prosty i przejrzysty sposób wyjaśnić, dlaczego model zwrócił taką prognozę. Lokalna interpretowalność pozwala nam określić i sprawdzić wpływ każdego z czynników.
W pierwszym kroku należy zainicjować przeliczenia w Jupyter Notebooku (bez tego dostaniemy błędy przy próbie wywołania poniższych wykresów):
shap.initjs()
i wyświetlmy wynik dla naszej pierwszej obserwacji (przypominam, że wiersze są iterowane od wartości zero):
shap.force_plot(explainer.expected_value, shap_values[0], X_val.iloc[0])

Opiszmy co widać na wykresie (pierwszy raz jak zobaczyłem to nie wiedziałem co się na nim dzieje 🙂 ):
- output value – jest to wartość prognozowana dla naszej obserwacji przez nasz model. W tym przypadku wynosi ona 30.06 i jest wyższa niż średnia dla obserwacji.
- base value – jest to średnia wartość predykcji zwracana dla naszych obserwacji. Możesz to prosto sprawdzić:

- Kolory: zmienne (cechy) podnoszące prognozę (w tym przypadku zwiększające cenę nieruchomości) są pokazane na czerwono, a te, które zmniejszają prognozę na niebiesko (mniejsza cena mieszkania). Cechy są poustawiane w kolejności które najbardziej wpłynęły odpowiednio na plus i minus.
- Dla tego przykładu najbardziej na wzrost ceny ma wpływ wartość cechy RM = 6.8, następnie TAX = 222 a potem LTAT = 7.53.
Popatrzmy na obserwację 17, 23, 54:
print('Obserwacja nr: 17')
shap.force_plot(explainer.expected_value, shap_values[17], X_val.iloc[17])
print('Obserwacja nr: 23')
shap.force_plot(explainer.expected_value, shap_values[23], X_val.iloc[23])
print('Obserwacja nr: 54')
shap.force_plot(explainer.expected_value, shap_values[54], X_val.iloc[54])
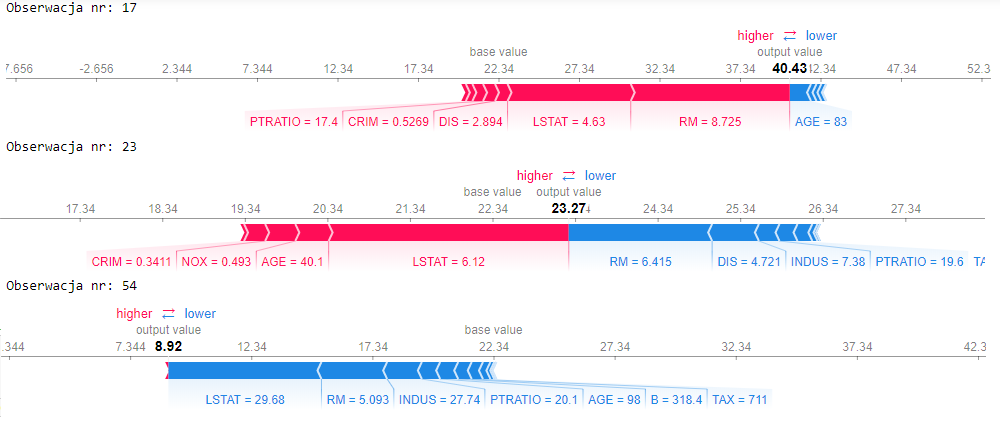
Jak widzicie można popatrzeć na każdą obserwację i wyjaśnić która cecha wpłynęła na model. O tyle jest to istotne w dziedzinie modelowania ryzyka dla bankowości, że są odpowiednie regulacje ustanowione przez KNF(Komisja Nadzoru Finansowego) dające każdemu klientowi możliwość spytania się wprost Banku: „Hej Bank, dlaczego nie dostałem kredytu i co sprawiło, że mnie tak oceniłeś„.
Wyjaśnienie całego zbioru
SHAP daje nam jeszcze jedną super (moim zdaniem) funkcjonalność. Powyżej mieliśmy zestawienie dla pojedynczej obserwacji. Natomiast jeśli weźmiemy wiele wyjaśnień, takich jak to pokazane powyżej, obrócimy je o 90 stopni, a następnie ułóżymy je poziomo to możemy zobaczyć wyjaśnienia dla całego zestawu danych (w notatniku ten wykres jest interaktywny):
shap.force_plot(explainer.expected_value, shap_values, X_val)
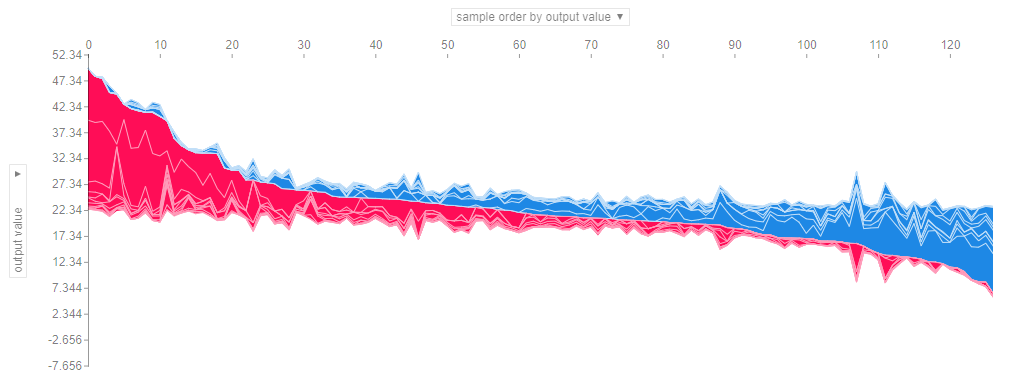
Wykres jest interaktywny i najbardziej lubię go za to, że można spojrzeć osobno na każdą zmienną odpowiednio wybierając po obu stronach osi tą samą cechę:

Spójrzcie na wyniki, które można łatwo interpretować kiedy wartość cechy wpływa na plus a kiedy na minus:


Szczerze mówiąc wykresy w miarę przypominają mi analizę WoE (Weight of Evidence) o którym postaram się napisać jeszcze w tym roku.
Podsumowanie
Interpretowalność jest bardzo ważnym aspektem uczenia maszynowego i sztucznej inteligencji. Mam nadzieję, że ten artykuł pokazuje Wam, że można zrozumieć wszelkie modele i mamy odpowiednie narzędzia, które bardzo mogą ułatwić nam pracę.
I pamiętajcie, że możecie wykorzystać bibliotekę również do interpretacji Waszych sieci opartych o chociażby zdjęcia.

Pozdrawiam serdecznie,




Dzięki za Twoją pracę. Właśnie robię projekt na studia i miałem problem z interpretacją wykresów Shapley. Już na pierwszy rzut oka wydaje mi się, że dzisiejszy wieczór z Twoją stroną pozwoli opanować ten problem. Pozrdrawiam, Maciek
Mirek, a jak podchodzisz do problemu wartości Shapleya w przypadku modeli „opakowanych” w Pipelines, gotowych do produkcji? Są z tym problemy:
https://github.com/slundberg/shap/issues/1373
https://github.com/ing-bank/probatus/issues/128
Równoległe „agnostic approach” i wykres z notebooka, gdzie cały preprocessing robimy zdalnie? Trochę overkill, ale czego się nie robi dla zaprezentowania interpretacji zmiennych…
Hej Adam.
Jeszcze przed takim problemem nie miałem okazji stanąć.
Wydaje mi się, że jeśli pipeline preprocessingu napisałeś porządnie, to nie bedzie to bardzo pracochłonne by podejść tak jak zaproponowałeś. Ja w pierwszym kroku tak bym do tego podszedł – ewentualnie poświęcił 1 dzień na reaserch i wrzucenie pytania w kilku miejscach na grupy dyskusyjne i ktoś może by pomógł 🙂
Super wpis! Konkrety napisane przystępnym językiem 💪💪
dziękuję 🥰
Kolejny świetny wpis, dzięki!
Dzięki!
Bardzo przydatny i intuicyjny wpis.
Pozdrawiam,