
– Tato, co tam robisz na komputerze? – zapytała Jagódka.
– Wybieram optymalne zmienne do modelu i muszę troszkę przy tym pomysleć – odpowiedziałem.
– Heeee??? – dziwnie spojrzała się na mnie Otylka.
– Wyobraźcie sobie, że pakujemy się na wakacje i możecie zabrać ze sobą jakieś zabawki (a same wiecie, że macie ich bardzo dużo). Macie różne opcje to wyboru. Możecie na przykład spakować zabawki do małego plecaczka, który weźmiecie ze sobą do samolotu.
– Ale tam się zmieści mało zabawek! – szybko zauważyła Jagódka.
– Zgadza się. Jest ich mało i po jakimś czasie wszystkie mogą Wam się znudzić, więc nie będziecie miały się czym bawić, ale za to łatwo je przewieźć. Możecie też spakować większą dodatkową torbę, ale za to trzeba będzie zapłacić i wtedy na miejscu kupimy mniej słodyczy. Oti się skrzywiła słysząc, że na wakacjach mogłoby mieć mniej słodyczy.
– Możecie też wziąć wszystkie zabawki, ale wtedy zamiast samolotem pojedziemy autkiem i podróż, zamiast trwać dwa filmy o krainie Lodu może zająć cały dzień i całą noc! A poza tym na miejscu i tak nie będziecie miały czasu wszystkim się bawić!
– O nie! To my idziemy pomyśleć, co będzie najlepsze. Chodź Oti, idziemy wybierać zabawki na wyjazd.
Wybór zmiennych to jedna z podstawowych koncepcji w uczeniu maszynowym, która ma ogromny wpływ na wydajność modelu. Każdy z nas budując model stanął przed problemem jak wybrać cechy do modelu.
W tym poście pokażę Ci najróżniejsze techniki, które możesz wykorzystać do wyboru modelu. Mam nadzieję, że nie rozczaruję Cię mówiąc, że nie ma złotego środka. Natomiast daję Ci ten arsenał, abyś z niego korzystał i eksperymentował.
Czym jest Feature Selection (wybór zmiennych)?
Wybór zmiennych (lub cech) to proces, w którym wybieramy te cechy w naszych danych, które mają największy wpływ na zmienną przewidywaną. Posiadanie nieistotnych zmiennych w danych może zmniejszyć dokładność wielu modeli, zwłaszcza algorytmów liniowych, takich jak regresja liniowa i logistyczna.
Innymi słowy, feature selection to proces wybierania podzbioru zmiennych z wszystkich przygotowanych dostępnych danych, aby uzyskać jak najlepszy model.
Dlaczego to jest ważne?
Oczywiście możesz się zatrzymać i zadać sobie proste pytanie: dobra, ale dlaczego nie przeliczać modelu na wszystkich danych? Przecież dobierzemy hiperparametry i model sobie poradzi.

Jest kilka istotnych powodów, dlaczego nie warto tego robić w ten sposób:
- Overfitting – jeśli okaże się, że mamy stosunkowo dużo cech w stosunku do liczby obserwacji, to model bardzo prosto będzie w stanie idealnie dopasować się na danych treningowych do funkcji celu. Natomiast takie podejście nie da nam uogólnionego modelu, a to jest naszym celem.
- XAI – im więcej zmiennych w modelu tym trudniej będzie nam wyjaśnić biznesowi, jak działa dany model. Jeśli możemy sobie pozwolić, zamiast 500 cech wdrożyć jedynie 20 kosztem niewielkiego spadku mocy, to pomyśl jak to ułatwi zrozumienie modelu!
- Większa dokładność – tutaj działa jedna z moich ulubionych zasad: „Shit in shit out”. Jeśli budując zmienne wykorzystamy automatyczne narzędzia jak np. featuretool, to większość stworzonych zmiennych nie będzie niosła żadnej informacji do modelowanego zagadnienia. A niska jakość danych wejściowych spowoduje powstanie modelu o niskiej jakości. Zatem pamiętaj: mniej mylących danych oznacza lepszą dokładność modelowania!
- Skraca czas treningu – bez zbędnej filozofii: mniej danych oznacza, że algorytmy trenują szybciej.
- Ułatwia wdrożenie i utrzymanie – często zapominamy, że sama budowa to jedno, ale wdrożenie i utrzymanie modelu to drugie. Im mniej cech tym ten proces będzie prostszy.
Mam nadzieję, że również czujesz, że wybór zmiennych to ważny temat i nie warto go pomijać!
Jak podzielić algorytmy do feature selection?
Istnieje wiele sposobów na wybór zmiennych (przekonasz się o tym w dalszej części wpisu). Natomiast większość tych metod możemy podzielić na trzy główne kategorie:
A. Oparte na filtrach (Filter methods)
Ostateczną listę charakterystyk filtrujemy na podstawie przyjętej metody. Może to być np. współczynnik korelacji Pearsona zmiennej z przewidywaną wartością. Metody te opierają się na cechach danych i nie używają algorytmów uczenia maszynowego. Zwykle są one szybsze kosztem niższej wydajności względem pozostałych metod.

B. Oparte na osadzeniach (embedded methods)
Metody osadzone wykorzystują algorytmy, które mają wbudowane metody wyboru funkcji. Metody te są iteracyjne. Chodzi o to, że dbają o każdą iterację procesu uczenia modelu i starannie wyodrębniają te cechy, które najbardziej przyczyniają się do uczenia dla określonej iteracji.
Często metody osadzone wprowadzają dodatkowe ograniczenia do optymalizacji algorytmu predykcyjnego, który skłania model w kierunku mniejszej złożoności (mniej współczynników).
Najpopularniejszymi przykładami tych metod są regresja LASSO i las losowy, które mają wbudowane funkcje wyboru cech.
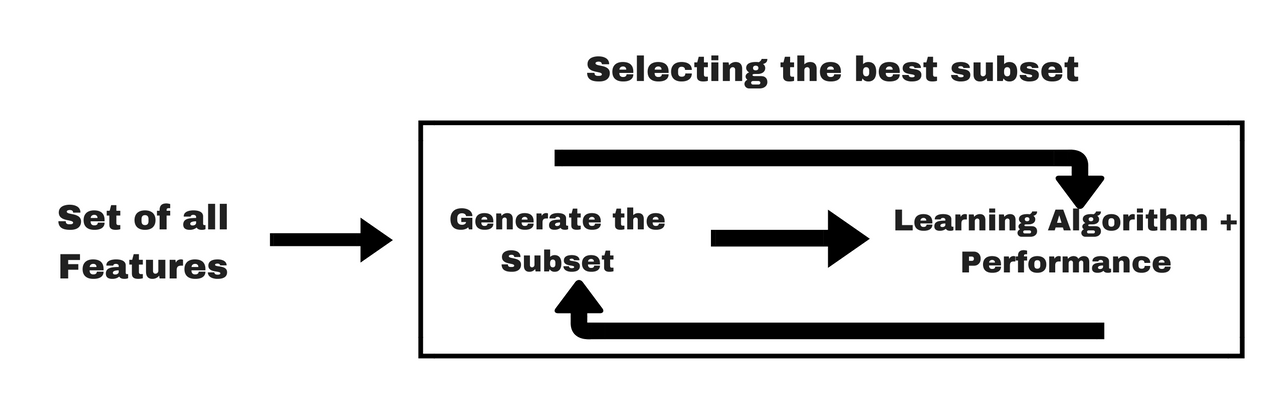
C. Oparte na wrapperach (Wrapper methods)
Są to metody, które traktują wybór zmiennych jako problem wyszukania. Proces wyboru cech opiera się na określonym algorytmie uczenia maszynowego, który staramy się dopasować do danego zbioru danych szukając optymalnego zestawu cech.
Na podstawie wniosków wyciągniętych z poprzedniego modelu decydujemy o dodaniu lub usunięciu funkcji z podzbioru. Może to być na przykład rekursywna eliminacja cech. Metody te są zwykle bardzo kosztowne obliczeniowo.
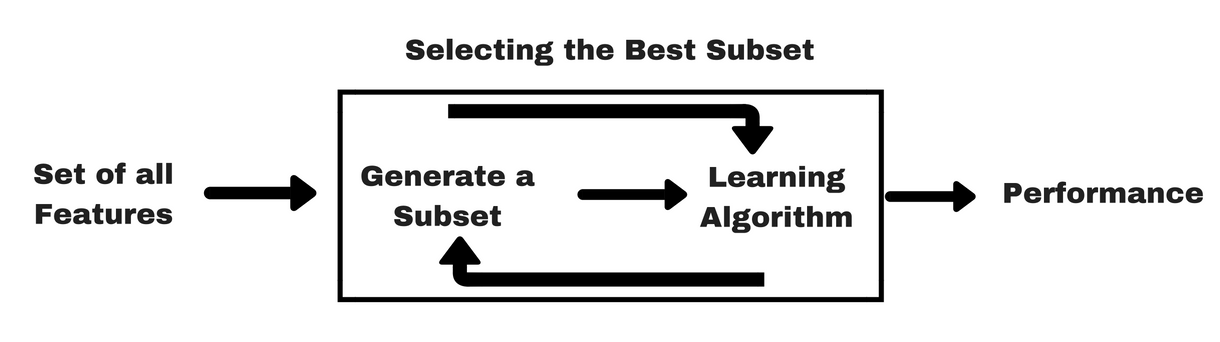
D. Metody hybrydowe (hybrid methods)
Są to po prostu metody, które łączą kilka wcześniej opisanych.
Jestem przekonany, że jeśli przeczytasz poniższe metody, to zainspirujesz się i sam/sama stworzysz własne rozwiązanie hybrydowe!
Która metoda jest najlepsza?
Jeśli zobaczysz artykuł, gdzie będzie informacja o najlepszej metodzie do wszystkich problemów, to … uciekaj!
Nie ma najlepszej metody wyboru funkcji.

Tak jak nie ma najlepszego zestawu zmiennych wejściowych ani najlepszego algorytmu uczenia maszynowego. Zamiast tego musisz odkryć, co najlepiej sprawdza się w Twoim konkretnym problemie, używając wielu eksperymentów.
Wypróbuj kilka metod selekcji zmiennych aby odkryć, co najlepiej sprawdza się w przypadku Twojego konkretnego problemu. Wraz z doświadczeniem i kolejnymi projektami zdobędziesz lepszą intuicję.
Eksperyment!
Nie jestem zwolennikiem samej teorii. Zatem przedstawię Ci wszystkie metody na jednym i tym samym przykładzie danych, abyś zobaczył, jak można zastosować je w praktyce.

Kwartał temu opuściłem mój ukochany polski bank Santander, w którym miałem okazję stawiać pierwsze kroki i poznawać świat AI oraz uczenia maszynowego. Z przyjemnością posłużę się danymi, które Santander opublikował na Kaggle. Dane możesz pobrać TUTAJ.
Jest to zbiór danych zawierający dużą liczbę zmiennych numerycznych. Kolumna „TARGET” to zmienna do przewidzenia – jest równa 1 dla niezadowolonych klientów i 0 dla zadowolonych klientów. Przyjrzyjmy mu się bliżej.
Wczytanie i przygotowanie danych
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from sklearn import __version__ as sklearn_version
from matplotlib import __version__ as matplotlib_version
print(f'pandas version: {pd.__version__}')
print(f'numpy version: {np.__version__}')
print(f'matplotlib version: {matplotlib_version}')
print(f'seaborn version: {sns.__version__}')
print(f'sklearn version: {sklearn_version}')

Jak widzisz podaję od razu biblioteki, których użyłem, aby ułatwić Ci powtórzenie eksperymentu.
df_train_orig = pd.read_csv('../data/santander-customer-satisfaction/train.csv')
df_train_orig = df_train_orig.drop(columns=['ID'])
print(f'train shape: {df_train_orig.shape}; TARGET=1: {df_train_orig.TARGET.sum()}')
df_train_orig.sample(5)

Mamy sporo danych. Traktuję je jako eksperyment do pokazania Ci najróżniejszych metod. W związku z tym, aby przyśpieszyć wyliczenia, przygotuję mniejszy zbalansowany zbiór danych w podziale na:
- zbiór treningowy – będę na nim wybierał cechy, a następnie trenował modele dla mniejszego zestawu cech,
- zbiór testowy – za jego pomocą będę ostatecznie sprawdzał predykcję.
from sklearn.model_selection import train_test_split
df = pd.concat([df_train_orig[df_train_orig['TARGET']==1].sample(3000),
df_train_orig[df_train_orig['TARGET']==0].sample(3000)
], axis=0).sample(frac=1)
df_train, df_test = train_test_split(df,
train_size=2/3,
stratify=df['TARGET'])
print(f'train shape: {df_train.shape}; TARGET=1: {df_train.TARGET.sum()}')
print(f'test shape: {df_test.shape}; TARGET=1: {df_test.TARGET.sum()}')

Model podstawowy
Na początku zbudujmy model podstawowy na wszystkich cechach. Będzie służył nam do porównania, o ile nam spadła lub wzrosła moc modelu zbudowanego na podstawie 369 zmiennych!
from sklearn.ensemble import RandomForestClassifier
def get_feats(df, feats=[''], exclude_feats=True):
if exclude_feats:
final_feats = [f for f in df.columns if f not in feats]
else:
final_feats = [f for f in df.columns if f in feats]
return final_feats
def get_X(df, feats=[''], exclude_feats=True, output_df=True):
if output_df:
return df[ get_feats(df, feats, exclude_feats=exclude_feats) ]
else:
return df[ get_feats(df, feats, exclude_feats=exclude_feats) ].values
X_train = get_X(df_train, 'TARGET', exclude_feats=True)
y_train = get_X(df_train, 'TARGET', exclude_feats=False)
X_test = get_X(df_test, 'TARGET', exclude_feats=True)
y_test = get_X(df_test, 'TARGET', exclude_feats=False)
Aby wyniki były porównywalne, będę wykorzystywał bardzo prosty zestaw hiperparametrów. Bibliotekę pomocniczą utils, gdzie umieściłem kilka funkcji pomocniczych do przeliczenia metryk, możesz pobrać TUTAJ.
from utils import calculating_metrics
rf_user_param ={
"max_depth": 6,
"n_estimators": 250,
"n_jobs":-1
}
model_rf = RandomForestClassifier(**rf_user_param)
model_rf.fit(X_train ,y_train)
calculating_metrics(model_rf, X_train, y_train, X_test, y_test)

Dane są zbalansowane (po 50% dla obu klas), więc wszystkie metryki są intuicyjne.

Normalizacja
Niektóre z użytych metod będą wymagać, aby dane były nieujemne i najlepiej znormalizowane. Dlatego wykorzystajmy proste metody zaszyte w sklearn.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# perform a robust scaler transform of the dataset
trans = StandardScaler()
X_train_t = trans.fit_transform(X_train)
X_test_t = trans.transform(X_test)
scaler = MinMaxScaler()
X_train_t = pd.DataFrame(scaler.fit_transform(X_train_t), columns=X_train.columns)
X_test_t = pd.DataFrame(scaler.transform(X_test_t), columns=X_train.columns)
a następnie przeliczmy jeszcze raz model:
model_rf_t = RandomForestClassifier(**rf_user_param)
model_rf_t.fit(X_train_t ,y_train)
calculating_metrics(model_rf_t, X_train_t, y_train, X_test_t, y_test)

W tym przypadku operacja była bez wpływu na moc modelu.
Uwaga! Zauważ, że korzystając z StandardScaler i MinMaxScaler skorzystałem z funkcji fit_transform na zbiorze treningowym, a tylko z transform na zbiorze testowym. Chodzi o to, że zbiór testowy traktujemy jakby to były nowe dane produkcyjne i nigdy nie możemy na nim nic trenować.
Dobrze, mamy sporo zmiennych w modelu – aż 369. Pewnie nie trzeba wykorzystywać wszystkich zmiennych do przewidywania klientów. Popatrz, jakich metod możemy użyć.

A. Feature selection – metody oparte na filtrach
Zacznijmy od najprostszych, ale często również dość skutecznych metod. Warto jednak podkreślić, że te najprostsze metody powinny głównie posłużyć do nie do wyboru najlepszych zmiennych, a głównie do odrzucenia tych kiepskich.
1. Variance Threshold (próg wariancji)
Cechy stałe to takie, które wykazują tylko jedną wartość dla wszystkich obserwacji zbioru danych. To jest ta sama wartość dla wszystkich wierszy zestawu danych. Te funkcje nie dostarczają żadnych informacji, które umożliwiają modelowi uczenia maszynowego rozróżnianie lub przewidywanie celu.
I tutaj z pomocą przychodzi nam próg wariancji, który jest prostym i podstawowym podejściem do wyboru cech. Usuwa wszystkie cechy, których wariancja nie osiąga pewnego zadanego progu. Implementacja w sklearn domyślnie usuwa wszystkie cechy o zerowej wariancji, tj. cechy, które mają taką samą wartość we wszystkich próbkach. Zakładamy, że cechy o większej wariancji mogą zawierać więcej przydatnych informacji, ale zauważmy, że nie bierzemy pod uwagę związku między zmiennymi cech lub zmiennymi cech a zmiennymi docelowymi, co jest jedną z wad metod filtrowania.
from sklearn.feature_selection import VarianceThreshold
def selectionVarianceThreshold(df, variance_threshold=0.0):
sel = VarianceThreshold(threshold=variance_threshold)
sel_var=sel.fit_transform(df)
sel_loc_index = sel.get_support(indices=True)
if len(sel_loc_index)==0:
return None
else:
return list(df.columns[sel_loc_index])
variance_threshold = 0.0005
feats_to_include_VT = selectionVarianceThreshold(X_train_t,
variance_threshold=variance_threshold)
Dodajmy jeszcze funkcje do przeliczenia podstawowego modelu na mniejszym zbiorze danych
def model_new_feats_calculation(X_train, y_train, X_val, y_val, feats_to_include, model, prnt=True):
X_train_tmp = get_X(X_train, feats_to_include, exclude_feats=False)
X_val_tmp = get_X(X_val, feats_to_include, exclude_feats=False)
if prnt:
print(f'Experiment for {len(feats_to_include)} features!')
print(f'X_train shape: {X_train_tmp.shape}, y_train shape: {y_train.shape}')
print(f'X_val shape: {X_val_tmp.shape}, y_val shape: {y_val.shape}')
model_tmp = model.fit(X_train_tmp, y_train)
return calculating_metrics(model_tmp, X_train_tmp, y_train, X_val_tmp, y_val), model_tmp
df_summary, model_VT = model_new_feats_calculation(
X_train_t, y_train, X_test_t, y_test,
feats_to_include=feats_to_include_VT,
model=RandomForestClassifier(**rf_user_param))
df_summary
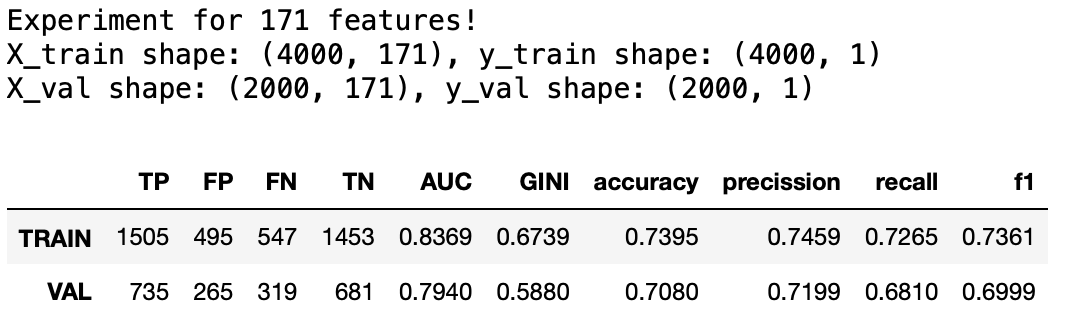
Wow. 200 cech mniej a metryki takie same.
Ale spokojnie, to dopiero początek. Jestem przekonany, że uda nam się ten wynik przebić. A wiesz dlaczego? Bo na pewno są tam jeszcze zmienne, które są szumem i zaburzają możliwość nauki modelu.
Aby kolejnym metodom ułatwić ich zadanie zapiszmy sobie te 171 zmiennych i będą one dla nas punktem wyjściowym w kolejnych metodach.
X_train = X_train_t[feats_to_include_VT]
X_test = X_test_t[feats_to_include_VT]
print(f'X_train:{X_train.shape}; X_test:{X_test.shape}')

Uwaga! Podobnie może być z cechami, które uzupełnione są dla mniej niż np. 1% populacji. Choć tutaj warto zapoznać się z wiedzą domenową! Dlatego powinniśmy być ostrożni przy usuwaniu tego typu funkcji i najlepiej przedyskutować wątpliwości z ekspertem domenowym.
2. Chi squared (Chi kwadrat)
Ta metoda wyboru zmiennych polega na przetestowaniu związku między cechami w zbiorze danych a zmienną docelową. Obliczamy chi-kwadrat między każdą cechą a celem i wybieramy pożądaną liczbę cech z najlepszymi wynikami chi-kwadrat.
W teorii mówi się, że test chi-kwadrat jest używany głównie dla cech kategorialnych w zbiorze danych. Natomiast w praktyce możesz także użyć go na danych, które mamy. Możecie sami sprawdzić, że wynik jest ten sam zmieniając nasze dane (wartości miedzy 0 a 1) na kategoryczne. Na przykład podmieniając X_train na (10*X_train).astype(int).
from sklearn.feature_selection import SelectKBest, chi2
chi_best_k = SelectKBest(chi2, k=10).fit((10*X_train).astype(int), y_train) #(10*X_train).astype(int)
ch_best_feats = [feat for feat in list(chi_best_k.get_support()*X_test.columns) if feat !='']
ch_best_feats

df_summary, model_VT = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=ch_best_feats,
model=RandomForestClassifier(**rf_user_param))
df_summary

Niestety sami podajemy parametr k (liczbę zmiennych). Ale to nie problem, zawsze można dodać pętle i zobaczyć krok po kroku jak będzie wzrastała moc modelu przy zwiększaniu liczby cech:
df_chi= pd.DataFrame(columns=['k','AUC','f1'])
for k in range(1,100):
chi_best_k = SelectKBest(chi2, k=k).fit(X_train, y_train)
ch_best_feats = [feat for feat in list(chi_best_k.get_support()*X_test.columns) if feat !='']
df_summary, model_VT = model_new_feats_calculation(X_train,
y_train, X_test, y_test, prnt=False,
feats_to_include=ch_best_feats,
model=RandomForestClassifier(**rf_user_param))
df_chi.loc[len(df_chi)] = [k, df_summary.loc['VAL']['AUC'], df_summary.loc['VAL']['f1']]
sns.set_style("whitegrid")
plt.figure(figsize=(15,6))
sns.lineplot(data=df_chi, x="k", y="AUC", label="AUC").set_ylabel("AUC / f1")
sns.lineplot(data=df_chi, x="k", y="f1", label="f1");

Ciekawy wynik. Zatem moglibyśmy dobrać z tej metody około 40 zmiennych. Mnie osobiście zainteresowałby ten mocny wzrost – pewnie to jest jedna z lepszych cech, którą mamy w zbiorze.
Hint! Przy wielu metodach możesz skorzystać z tego podejścia, aby wyliczyć kilka możliwości i optymalnie dobrać liczbę cech.
Dodatkowo, zamiast SelectKbest można wybrać na przykład SelectPercentile, który wybiera cechy zgodnie z percentylem najwyższych wyników.
3. ANOVA F-value For Feature Selection
W przypadku cech ilościowych możemy obliczyć wartość f-Anova między każdą cechą a wektorem docelowym. Wyniki wartości F sprawdzają, czy gdy grupujemy cechę liczbową według wektora docelowego, średnie dla każdej grupy są znacząco różne.
from sklearn.feature_selection import f_classif
fvalue_selector = SelectKBest(f_classif, k=10)
kbest_anova = fvalue_selector.fit(X_train, y_train)
anova_feats = [feat for feat in list(kbest_anova.get_support()*X_test.columns) if feat !='']
anova_feats

df_summary, model_anova = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=anova_feats,
model=RandomForestClassifier(**rf_user_param))
df_summary

Tak jak poprzednio możemy zobaczyć jak to wygląda w przedziale wyboru od 1 do 100 cech:
df_anova= pd.DataFrame(columns=['k','AUC','f1'])
for k in range(1,100):
fvalue_selector = SelectKBest(f_classif, k=k)
kbest_anova = fvalue_selector.fit(X_train, y_train)
anova_feats = [feat for feat in list(kbest_anova.get_support()*X_test.columns) if feat !='']
df_summary, model_VT = model_new_feats_calculation(X_train,
y_train, X_test, y_test, prnt=False,
feats_to_include=anova_feats,
model=RandomForestClassifier(**rf_user_param))
df_anova.loc[len(df_anova)] = [k, df_summary.loc['VAL']['AUC'], df_summary.loc['VAL']['f1']]
sns.set_style("whitegrid")
plt.figure(figsize=(15,6))
sns.lineplot(data=df_anova, x="k", y="AUC", label="AUC").set_ylabel("AUC / f1")
sns.lineplot(data=df_anova, x="k", y="f1", label="f1");

4. Information gain (zysk informacji)
Zysk informacji oblicza zmniejszenie entropii z transformacji zbioru danych. Można go użyć do wyboru cech, oceniając zysk informacyjny każdej zmiennej w kontekście zmiennej docelowej. Zdobywanie informacji lub wzajemne informacje mierzą, jak obecność/brak danej cechy przyczynia się do prawidłowego przewidywania celu.
Information gain mierzy jak bardzo znajomość jednej zmiennej zmniejsza niepewność co do zmiennej przewidywanej. Na przykład, jeśli waga i wzrost są niezależne, to znajomość wagi nie daje żadnych informacji o wzroście i odwrotnie. Ich wzajemne informacje wynoszą zero. Z drugiej strony, jeśli informacje przekazywane przez wzrost są współdzielone z wagą, to wzajemna informacja jest taka sama jak niepewność zawarta w jednej ze zmiennych.
from sklearn.feature_selection import mutual_info_classif
importances = mutual_info_classif(X_train, y_train)
feature_info = pd.Series(importances, X_train.columns).sort_values(ascending=False)
feature_info.head(5)

df_gain= pd.DataFrame(columns=['k','AUC','f1'])
for k in range(1,100):
df_summary, model_infoG = model_new_feats_calculation(X_train,
y_train, X_test, y_test, prnt=False,
feats_to_include=feature_info.head(k).index,
model=RandomForestClassifier(**rf_user_param))
df_gain.loc[len(df_gain)] = [k, df_summary.loc['VAL']['AUC'], df_summary.loc['VAL']['f1']]
sns.set_style("whitegrid")
plt.figure(figsize=(15,6))
sns.lineplot(data=df_gain, x="k", y="AUC", label="AUC").set_ylabel("AUC / f1")
sns.lineplot(data=df_gain, x="k", y="f1", label="f1")
df_summary, model_infoG = model_new_feats_calculation(X_train,
y_train, X_test, y_test, prnt=False,
feats_to_include=feature_info.head(10).index,
model=RandomForestClassifier(**rf_user_param))
df_summary

Bardzo ciekawy wynik. W tym przypadku bardzo szybko osiągamy wynik metryki f1 na poziomie 72%, a dokładając kolejne cechy zaczyna on się zmniejszać.
5. Correlation Coefficient (współczynnik korelacji)
Logika stojąca za wykorzystaniem korelacji do wyboru cech polega na tym, że dobre zmienne są silnie skorelowane ze zmienną prognozowaną. Dodatkowo, w przypadku niektórych metod takich jak regresja logistyczna, warto zadbać, aby cechy nie były skorelowane z innymi cechami.
df_train_transform = pd.concat([X_train.reset_index(drop=True), y_train.reset_index(drop=True)], axis=1)
corr_matrix = df_train_transform.corr()
target_corr = corr_matrix['TARGET'].abs().sort_values(ascending=False)
target_corr.head(10)

Oczywiście zmienna sama ze sobą wszystko wyjaśnia i wówczas korelacja przyjmuje wartość 1. Jak w powyższym przykładzie zmienna „TARGET” sama ze sobą daje taką wartość.
df_summary, model_corr = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=target_corr.iloc[1:11].index,
model=RandomForestClassifier(**rf_user_param))
df_summary

I tak jak wspomniałem powyżej, można użyć tej metody do usunięcia zmiennych skorelowanych samych ze sobą:
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# Find index of feature columns with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(upper[column] > 0.95)]
plt.figure(figsize=(8,6))
a = sns.heatmap(upper.iloc[0:10,0:10], square=True, annot=True,
linewidths=0.5, cmap="YlGnBu")
a.set_xticklabels(a.get_xticklabels(), rotation=30)
a.set_yticklabels(a.get_yticklabels(), rotation=30)
plt.show()

6. Fisher score
Skala Fishera jest metodą chętnie wykorzystywaną do selekcji cech. Oblicza statystyki chi-kwadrat między każdą nieujemną cechą i klasą. Algorytm, którego użyjemy, zwraca rangę zmiennej na podstawie wyniku Fisher’a w kolejności malejącej. Następnie możemy wybrać zmienne zgodnie z rangą.
from skfeature.function.similarity_based import fisher_score
ranks = fisher_score.fisher_score(X_train.to_numpy(), y_train.values.ravel())
feature_ranks = pd.Series(ranks, X_train.columns).sort_values()
feature_ranks

df_summary, model_fish = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=feature_ranks.head(20).index,
model=RandomForestClassifier(**rf_user_param))
df_summary

7. Information Value (IV)
Mam sentyment do tej metryki. Od kiedy zacząłem pracę w bankowości w 2008 roku przez kolejną dekadę służyła osobom budującym modele predykcyjne dotyczące ryzyka jako główna metryka mówiąca o mocy danej cechy.
Wartość informacyjna (IV) jest użyteczną techniką wyboru ważnych zmiennych, która pomaga uszeregować zmienne na podstawie ich ważności. Opowiem o niej więcej przy okazji artykułu o regresji logistycznej i modelowaniu ryzyka kredytowego, który planuje napisać w najbliższym czasie.
Ogólna zasada jest taka, że jeśli IV jest:
- < 0,02 – cecha nie jest przydatna do modelowania,
- 0,02 do 0,1 – zmienna ma tylko słabą relację z ilorazem szans dobra/złe,
- 0,1 do 0,3 – predyktor ma średnią relację siły do ilorazu szans dobra/złe,
- 0,3 do 0,75 – wtedy predyktor ma silny związek ze stosunkiem szans dobra/złe,
- > 0,75 bardzo mocna i warto sprawdzić czy nie jest to jakaś zmienna wróżka (data leak)!
from utils import count_iv_for_df
iv_res = count_iv_for_df(df_train, 'TARGET', percentage_thres=5, no_buckets=6)
iv_res.head(10)

df_summary, model_iv = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=iv_res['feature'].head(10).values,
model=RandomForestClassifier(**rf_user_param))
df_summary


B. Feature selection – metody oparte
na osadzeniach
8. Lasso Regularization (regularyzacja Lasso)
Regularyzacja polega na dodaniu kary do różnych parametrów modelu uczenia maszynowego w celu zmniejszenia swobody modelu, tj. uniknięcia nadmiernego dopasowania. W regularyzacji modelu liniowego kara jest nakładana na współczynniki, które mnożą każdy z predyktorów. Z różnych typów regularyzacji, Lasso lub L1 ma właściwość, która jest w stanie zmniejszyć niektóre współczynniki do zera. Dlatego tę funkcję można usunąć z modelu.
Techniki regularyzacji pomagają zmniejszyć ryzyko nadmiernego dopasowania i pomagają nam uzyskać optymalny model. Regularyzację można wykorzystać na dziesiątki sposobów. Jednym z nich jest wykorzystanie regularyzacji Lasso do nakładania kar na współczynniki, co powoduje zerowanie zmiennych w modelu.
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso
lasso = SelectFromModel(Lasso(alpha=0.001))
lasso.fit(X_train, y_train)
lasso_feats = [feat for feat in list(lasso.get_support()*X_test.columns) if feat !='']
df_summary, model_rfecv = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=lasso_feats,
model=RandomForestClassifier(**rf_user_param))
df_summary

9. Random Forest Importance
Lasy losowe to jeden z najpopularniejszych algorytmów uczenia maszynowego. Są bardzo skuteczne, ponieważ zapewniają ogólnie dobrą wydajność predykcyjną, niski overfitting i łatwą interpretację istotności zmiennych. Innymi słowy, łatwo jest obliczyć, w jakim stopniu każda zmienna przyczynia się do podjęcia decyzji.
Lasy losowe składają się z dziesiątek, setek lub tysięcy drzew decyzyjnych, z których każde zbudowane jest na podstawie losowego wyboru obserwacji ze zbioru danych i losowej ilości zmiennych. Żadne drzewo nie widzi wszystkich danych i cech, co gwarantuje, że drzewa są mniej podatne na nadmierne dopasowanie.
Każde drzewo jest również sekwencją pytań tak-nie opartych na jednej zmiennej, np. „czy klient zarabia mniej niż 5.000 pln?”. W każdym pytaniu (węźle drzewa) dzielą zbiór danych na 2 segmenty, z których każdy zawiera obserwacje, które są między sobą bardziej podobne i różnią się od tych z drugiego segmentu. W przypadku klasyfikacji miarą zanieczyszczenia jest zanieczyszczenie Giniego lub entropia. Dlatego podczas trenowania drzewa można obliczyć, o ile każda cecha zmniejsza zanieczyszczenie. Im bardziej dana cecha zmniejsza zanieczyszczenie, tym ważniejsza jest to cecha. W lasach losowych spadek zanieczyszczenia z każdej cechy można uśrednić między drzewami, aby określić ostateczne znaczenie zmiennej.
Mówiąc prościej, zmienne wybrane na wierzchołkach drzew są ogólnie ważniejsze niż cechy wybrane na końcowych węzłach drzew. Dzieje się tak, ponieważ górne podziały prowadzą do większego przyrostu informacji.
model = RandomForestClassifier(n_estimators=1000, max_depth=10)
model.fit(X_train, y_train)

importances = model.feature_importances_
df_rf_importance = pd.concat([pd.DataFrame(X_train.columns, columns=['feat']),
pd.DataFrame(importances, columns=['importance'])
], axis=1).sort_values(by='importance', ascending=False)
df_rf_importance.head(10)

df_summary, model_rf_imp = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=df_rf_importance.head(30)['feat'].to_list(),
model=RandomForestClassifier(**rf_user_param))
df_summary

C. Feature selection – metody oparte
na wrapperach
10. Forward Feature Selection
Idea metody jest bardzo prosta. Jest to metoda iteracyjna, w której zaczynamy od najlepiej działającej zmiennej względem celu. Następnie wybieramy kolejną zmienną, która daje najlepszą wydajność w połączeniu z pierwszą wybraną zmienną. Proces ten trwa aż do osiągnięcia zadanego kryterium.
Taki typ selekcji nazywamy również metodami zachłannymi, ponieważ oceniają wszystkie możliwe kombinacje pojedynczych, podwójnych, potrójnych i tak dalej cech. Dlatego jest dość kosztowna obliczeniowo!
W implementacji mlxtend jako kryterium zatrzymania jest arbitralnie ustawiona liczba cech. Tak więc wyszukiwanie zakończy się, gdy osiągniemy pożądaną liczbę wybranych funkcji. Ja ustawiłem parametr na „best”.
Dodatkowo specjalnie dałem o wiele mniejszy las losowy (tylko 10 estymatorów i głębokość 5) i ustawiłem parametr walidacji krzyżowej cv=2 w celu przyśpieszenia obliczeń. Zwróć uwagę, że w tak prostym przypadku i przy tak małej liczbie obserwacji, obliczenia trwały 4 minuty.
from mlxtend.feature_selection import SequentialFeatureSelector
from sklearn.ensemble import RandomForestClassifier
model_rf_small = RandomForestClassifier(n_estimators=10, max_depth=5)
forward_sfs = SequentialFeatureSelector(model_rf_small,
k_features='best',
forward=True,
cv=2,
verbose=1,
n_jobs=-1)
%time forward_sfs.fit(X_train, y_train.values.ravel())

W powyższym kodzie dodałem w Jupyter Notebook tzw. magiczną komendę %time, która dodatkowo zróciła informacje o czasie wykonywania.
df_summary, model_forward_sfs = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=list(forward_sfs.k_feature_names_),
model=RandomForestClassifier(**rf_user_param))
df_summary

11. Backward Feature Elimination
Ta metoda to tak jakby brat bliźniak powyższej metody. Działa dokładnie odwrotnie do metody Forward Feature Selection.
Zaczynamy od wszystkich zmiennych i budujemy model. Następnie usuwamy z listy cech zmienną, która daje najlepszą wartość miary oceny. Proces ten jest kontynuowany aż do osiągnięcia zadanego kryterium.
backward_sfs = SequentialFeatureSelector(model_rf_small,
k_features='best',
forward=False,
cv=2,
verbose=1,
n_jobs=-1)
%time backward_sfs.fit(X_train, y_train.values.ravel())

df_summary, model_backward_sfs = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=list(backward_sfs.k_feature_names_),
model=RandomForestClassifier(**rf_user_param))
df_summary

12. Exhausive Feature Selection
Jest to najbardziej zachłanny i kosztowny obliczeniowo algorytm z całej tej listy! Ponadto jest to typowe rozwiązanie „brute-force” – próbuje każdą możliwą kombinację zmiennych i zwraca najskuteczniejszy podzbiór.
Zatem, jeśli chcemy zbudować model SVM i mamy zbiór składający się dla przykładu tylko z 4 cech (wiek, wzrost, waga, płeć), to algorytm przetestuje model na zbiorze 15 kombinacji:
- 1 zmiennej: np. wiek,
- 2 zmiennych, np. wiek+płeć,
- 3 zmiennych, np. wiek+wzrost+płeć,
- 4 zmiennych: wiek+wzrost+waga+płeć,
i wybierze tę kombinację zmiennych, która zapewnia najlepszą wydajność (np. dokładność klasyfikacji) dla wybranego modelu.
Niestety mój komputer nie chciał w miarę szybkim czasie przeliczyć zbiorów powyżej kilku cech 🙂 Dlatego poniżej przykład z wybraniem do 2 zmiennych.
from mlxtend.feature_selection import ExhaustiveFeatureSelector
efs = ExhaustiveFeatureSelector(model_rf_small,
min_features=1,
max_features=2,
print_progress=True,
cv=2,
n_jobs=-1)
efs.fit(X_train, y_train.values.ravel())
df_summary, model_efs = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=list(efs.best_feature_names_),
model=RandomForestClassifier(**rf_user_param))
df_summary

13. Recursive Feature Elimination
Jest to kolejny zachłanny algorytm optymalizacji, którego celem jest wybieranie cech poprzez rekurencyjne uwzględnianie coraz mniejszych zestawów cech.
Metoda RFE wielokrotnie tworzy modele i odkłada na bok najlepszą lub najgorszą funkcję w każdej iteracji. Konstruuje następny model z pozostałymi cechami, aż wszystkie cechy zostaną wyczerpane. Następnie klasyfikuje cechy na podstawie kolejności ich eliminacji.
from sklearn.feature_selection import RFE
rf = RandomForestClassifier(n_estimators=50, max_depth=5)
rfe = RFE(rf, n_features_to_select=1)
rfe.fit(X_train, y_train)
df_rfe = pd.concat([pd.DataFrame(X_train.columns, columns=['feat']),
pd.DataFrame(rfe.ranking_, columns=['rank'])
], axis=1).sort_values(by='rank')
df_rfe

df_summary, model_rfe = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=df_rfe.head(10)['feat'].to_list(),
model=RandomForestClassifier(**rf_user_param))
df_summary

W najgorszym przypadku, jeśli zbiór danych zawiera N cech, RFE wykona chciwe wyszukiwanie 2N kombinacji cech.
14. Recursive Feature Elimination with Cross Validation
Jest to kolejna metoda z sklearn. Metoda ta jest modyfikacją wcześniejszej metody poprzez dodanie do niej techniki walidacji krzyżowej.
from sklearn.feature_selection import RFECV
rfecv = RFECV(rf, cv=2)
rfecv.fit(X_train, y_train)
df_rfecv = pd.concat([pd.DataFrame(X_train.columns, columns=['feat']),
pd.DataFrame(rfecv.ranking_, columns=['rank'])
], axis=1).sort_values(by='rank')
df_rfecv

df_summary, model_rfecv = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=df_rfecv.head(20)['feat'].to_list(),
model=RandomForestClassifier(**rf_user_param))
df_summary

D. Feature selection – metody hybrydowe
15. Random Forest Importance + random values
Wcześniej opisałem metodę lasu losowego. Tam na wyjściu dostaliśmy listę zmiennych poszeregowanych od najbardziej istotnych cech do mniej istotnych.
Do tej metody zacząłem używać pewnej sztuczki:
- do mojej listy zmiennych dodaję nowe stworzone zmienne, które są losowymi zmiennymi (np. 20 takich nowych cech),
- buduję model lasu losowego na tym rozszerzonym zbiorze danych,
- wyliczam średnią moc (importance) na zmiennych losowych,
- wybieram tylko te cechy, których importance jest powyżej wartości z punktu 3.
Dzięki temu bardzo szybko otrzymuję fajną listę cech, które wnoszą coś dodatkowego do modelu.
def add_random_variables(dataset, num_rand_vars=10):
rand_vars_names = ['random_' + str(i) for i in range(num_rand_vars)]
random_vars = pd.DataFrame(np.random.rand(len(dataset), num_rand_vars),
columns=rand_vars_names)
random_cols = random_vars.columns
return pd.concat([dataset, random_vars.set_index(dataset.index)], axis=1), list(random_cols)
def selectionRandomForestThreshold(X_train, y_train, num_rand_vars=20, user_rf_params = {'n_estimators': 500, 'max_depth': 6}):
X_train_tmp, random_cols = add_random_variables(X_train, num_rand_vars=num_rand_vars)
model_rf = RandomForestClassifier(**user_rf_params)
model_rf.fit(X_train_tmp, y_train)
features = pd.concat([pd.DataFrame(model_rf.feature_importances_), pd.DataFrame(X_train_tmp.columns)], axis = 1)
features.columns = ['importance', 'char_name']
features = features.sort_values(by='importance', ascending = False)
importance_cut_off = features[features['char_name'].isin(random_cols)]['importance'].mean()
return list(features[(features['importance'] >= importance_cut_off) & (~features['char_name'].isin(random_cols))]['char_name'])
feats_rf_treshold = selectionRandomForestThreshold(X_train, y_train)
df_summary, model_rf_tresh = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=feats_rf_treshold,
model=RandomForestClassifier(**rf_user_param))
df_summary

16. Boosting + Shap + Forward group selection
A tutaj inna metoda, którą zacząłem stosować w ubiegłym roku i która daje mi często bardzo zadowalające wyniki. Czas wyliczeń jest dłuższy niż wcześniejsza metoda, ale fajnie mieć alternatywę.
Sposób działania wygląda tak:
- wybieram któryś z modeli opartych na boostingu (np. XGBoost, LightGBM lub CatBoost),
- buduję model,
- wyliczam moc cech uszeregowanych za pomocą wartości shapley’a,
- tworzę zbiór ze zmiennymi szeregując od najmocniejszych do najsłabszych,
- buduję kolejne modele biorąc top X kolejnych zmiennych tak długo, aż po dodaniu kolejnych zmiennych nie widzę wzrostu mocy modelu.
import catboost as ctb
import shap
model_ctb = ctb.CatBoostClassifier(logging_level='Silent')
model_ctb.fit(X_train, y_train)
explainer = shap.TreeExplainer(model_ctb)
shap_values = explainer.shap_values(X_train)
shap.summary_plot(shap_values, X_train,plot_type='bar')

def select_top_features(model, X, n_chars=1):
try:
features = pd.concat([pd.DataFrame(model.feature_importances_), pd.DataFrame(X.columns)], axis = 1)
features.columns = ['importance', 'char_name']
features = features.sort_values(by='importance', ascending = False)
features_short = features['char_name'][0:n_chars].to_list()
except:
features_short=None
return features_short
def selectionCatBoostTopX(X_train_, y_train_, n_step=5):
X_train, X_val, y_train, y_val = train_test_split(X_train_, y_train_,
train_size=0.75)
model_all = ctb.CatBoostClassifier(logging_level='Silent').fit(X_train, y_train)
#shap importance
explainer = shap.TreeExplainer(model_ctb)
shap_values = explainer.shap_values(X_train)
df_shap = pd.concat([pd.DataFrame(X_train.columns, columns=['feat']),
pd.DataFrame(abs(shap_values).mean(axis=0), columns=['shap'])
], axis=1).sort_values(by='shap', ascending=False)
if X_train.shape[0] >= n_step:
i = 1
metric_champion = 0
feats_champion = ['']
while X_train.shape[0] >= n_step*i:
feats = df_shap.head(n_step*i)['feat'].to_list()
summary_challenger, model_challenger = model_new_feats_calculation(X_train, y_train, X_val, y_val, feats_to_include=feats, model=ctb.CatBoostClassifier(logging_level='Silent'))
metric_challenger = summary_challenger.loc['VAL']['f1']
if metric_challenger > metric_champion:
metric_champion = metric_challenger
feats_champion = feats
else:
break
i = i+1
else:
print('brak tylu zmiennych')
return feats_champion
feats_ctb_tresh = selectionCatBoostTopX(X_train, y_train, n_step=5)

df_summary, model_ctb_tresh = model_new_feats_calculation(X_train,
y_train, X_test, y_test,
feats_to_include=feats_ctb_tresh,
model=RandomForestClassifier(**rf_user_param))
df_summary

Podsumowanie
Uff… dobrnęliśmy do końca. Jeśli jesteś tutaj, to gratuluję Ci przejścia przez wszystkie metody dla „feature selection”. Mam prośbę, jeśli znasz metodę, której nie opisałem, to dopisz ją w komentarzu. Postaram się za jakiś czas wrócić do artykułu i dopisać kolejne inspiracje od Was – czytelników bloga!
Pozdrawiam serdecznie z całego serducha,

Obraz Gerd Altmann z Pixabay



Pingback: How does random forest work? - influencer AI
Mirku, rewelacyjny wpis!
Jestem przekonany, że kolejne MasterClass u Vladimira będę kończył z wyższymi wynikami po tej lekturze 🙂
To co cieszy mnie najbardziej i co doceniam to przede wszystkim Twoje praktyczne podejście – dzielisz się wiedzą i praktycznym doświadczeniem.
Pozdrawiam.
dziekuje za miłe słowa 🙂
ps powodzenia na kolejnym MasterClass!
Łał, kawał samego mięsa i to po polsku!
Twój blog na staż w zespole ML jak znalazł dla mnie. 🙂
Wstępy z rozmów z córkami są świetne! Znakomity pomysł. Tym bardziej trafia do mnie, bo sam niedawno zostałem tatą. 🙂 Chętnie będę tu wpadał częściej.
Pozdrawiam
Dziękuję! 🙂
Jak mogę pobrać?
„Aby wyniki były porównywalne, będę wykorzystywał bardzo prosty zestaw hiperparametrów. Bibliotekę pomocniczą utils, gdzie umieściłem kilka funkcji pomocniczych do przeliczenia metryk, możesz pobrać TUTAJ”.
Hej Łukasz!
Przepraszam, zapomniałem podlinkować. Dziękuję, że to zauważyłeś. Już poprawiłem.
A byś nie musiał szukać tutaj też specjalnie dla Ciebie załączam link do poprania:
https://miroslawmamczur.pl/wp-content/uploads/2022/03/utils.py_.zip
Pozdrawiam,
Mirek
Pingback: Newsletter Dane i Analizy, 2022-03-07 | Łukasz Prokulski
Ogrom przydatnych informacji ! 😀
Dziękuję :*
Wiele metod selekcji zmiennych dla procesu klasyfikacji można znaleźć w publikacji „Modelowanie dla biznesu” cz II. Czytam Twój opis i jedyne co widzę to straszny chaos. W transformerach metoda fit stosowana jest tylko dla zbioru treningowego – jak sama nazwa wskazuje fit służy do znalezienia parametrów transformatora . Na zbiorze testowym wykonuje się już metodę transform – bo tu musisz przetransformować rzeczy zgodnie z tym na czym się uczyłeś (to samo ma się do wszystkich imputacji i innych transformacji) . W naszej publikacji podzieliliśmy metody na dotyczące pojedynczych zmiennych (lokalne) oraz dotyczące większej ilości + rekurencyjne. Większość metod, które opisałeś na początku kompletnie nie nadają się do automatycznego procesu wyboru zmiennych . Wyjśnianie overfittingu przez liczbę kolumn i wierszy ? to chyba jednak nie o to chodzi. Większość z tych metod może posłużyć nie do wyboru najlepszych zmiennych ale do odrzucenia kiepskich. Co w przypadku gdy masz dwie takie same zmienne, bądź identyczne na poziomie 90% ? takie IV (które bazuje na wyborze lokalnym – jedna zmienna i target) wybiorą obie jako najlepsze – a gdzie sprawdzenie współliniowości lub korealcji ? Metoda Branch and Bound nie pojawia się ? . Dużo tu zawiłości i zależności chociażby od sposobu przygotowania danych i ich transformacji . Fajnie, że ruszony temat ale jednak trzeba go jeszcze przemyśleć. A co z PCA lub autoenconderami ? itd itp 🙂
https://wydawnictwo.sgh.waw.pl/produkty/profilProduktu/id/1236//MODELOWANIE_DLA_BIZNESU._METODY_MACHINE_LEARNING_MODELE_PORTFELA_CONSUMER_FINANCE_MODELE_REKURENCYJNE_ANALIZY_PRZEZYCIA_MODELE_SCORINGOWE_Redakcja_naukowa_Karol_Przanowski_Sebastian_Zajac/
Hej Sebastian!
Dzięki za komentarz.
– Metod branch & bound nie kojarzyłem. Dziękuję za info to o nich doczytam 🙂
– odnośnie fit i transform zgadzam się z Tobą i moim zdaniem mówimy o tym samym.
– „Większość metod, które opisałeś na początku kompletnie nie nadają się do automatycznego procesu wyboru zmiennych” – dodałem tą informację by to podkreślić. Choć nie mówiłem, by nimi automatycznie wybierać cechy. Wręcz kilka razy zachęcam by testować kilka różnych i je łączyć.
– odnośnie IV i sprawdzenie współliniowości lub korelacji ma znaczenie przy prostych modelach jak np. regresja logistyczna. Natomiast to sprawdza tylko liniowe zależności, a problemy co rozwiązujemy najczęściej są nieliniowe. Kilka razy widziałem już, że w przypadku metod jak boostingi nie warto usuwać wszystkich skorelowanych zmiennych, bo niektóre z nich potrafią polepszyć znacząco model.
– Autoenkodery głównie wykorzystywałem do redukcji wymiarów (np. 100 cech zamienić na 20 kolumn – tylko, że tracę przy tym biznesową interpretowalność), a nie do wyboru cech. Podzielisz się linkiem z przykładem jak wykorzystać autoenkoder do wyboru cech nie tracąc interpretowalności?
Pozdrawiam serdecznie
Mirek
ps. I przepraszam Cię, że odebrałeś artykuł jako straszny chaos. Starałem się jak mogłem to poukładać. Widać, że muszę jeszcze popracować 🙂
Ale torpeda! Super wpis i tony cennej wiedzy.
Z czystej ciekawości – sprawdzałeś jak w 9. wypada permutation importance vs feature_importances? Po lekturze https://explained.ai/rf-importance/#corr_collinear w zasadzie już ich nie używam, stąd pytanie. 🙂
Zdrowia!
Hej!
Nie sprawdzałem. Ale zanotowałem sobie i jak będę wkrótce robił kolejny model w pracy to chętnie przetestuję i od razu dopisze potem obserwacje do artykułu 🙂
Pozdrawiam serdecznie,
Mirek