
W poprzednim artykule przedstawiłem Wam pokrótce czym są autoenkodery i do czego można je wykorzystać. W tym wpisie chciałem pokazać Wam przykład jak można napisać w Python własny autoenkoder do wykrywania nieuczciwych transakcji kartą kredytową (fraud). Gotowi? To zaczynamy!
Kim jest fraud?
Mówiąc krótko fraud to inaczej oszust – osoba, która podaje nieprawdziwe dane lub w nielegalny sposób stara się przywłaszczyć czyjeś mienie.
Jest wiele rodzajów fraudów w bankowości. Kilka lat temu najwięcej było oszustów podrabiających dowody i próbujący wyłudzić kredyty.
Obecnie największym problemem na rynku finansowym wśród fraudów są ataki typu fałszywych linków (phishing). Niestety nieświadomi klienci po kliknięciu w otrzymany link np. od firmy kurierskiej są proszeni o dopłatę do ciężaru paczki lub w celu uruchomienia ogłoszenia. Potem okazuje się, że z ich kont zostały zlecone nieautoryzowane przelewy i zostali okradzeni.
Dlatego nigdy w nic podejrzanego nie klikajcie!!!

Innym rodzajem są tak zwane fraudy kartowe.
Fraud kartowy
Fraudy kartowe polegają na oszustwach przy wykorzystaniu kart płatniczych, np. ściągnięcie transakcji z wypożyczalni z Włoch w sytuacji, gdy byliście tam parę miesięcy temu lub kupieniu czy przelaniu pewnej kwoty bez Waszej autoryzacji.
W raporcie Narodowego Banku Polskiego na temat funkcjonowania polskiego systemu płatniczego w I poł. 2019 r., znajdziemy informację, że działające w kraju banki od stycznia do czerwca ubiegłego roku (2019) odnotowały ponad 94,4 tys. oszustw przy wykorzystaniu kart płatniczych.
Rekordowa była także wartość fraudów, która wyniosła ponad 27 mln zł.

Czy to dużo? Raczej nie, bo w samym 2018 na całym świecie wyłudzono około 100 miliardów PLN! (źródło).

Jak działa autoenkoder przy wykrywaniu anomalii?
Zanim zaczniemy, to tylko wyjaśnijmy sobie w jaki sposób można wykorzystać autoenkoder do wykrywania anomalii. Tak jak mam nadzieję pamiętacie z wcześniejszego artykułu autoenkodery to rodzaje sieci neuronowych, które sprowadzają dane wejściowe (np. obraz czy zestaw danych) do mniejszej (lub czasami większej) liczby cech i odwraca proces odtwarzania danych wejściowych.
Weźmy na przykład autoenkodera do rekonstruowania zdjęć Spidermana.

Najpierw obraz jest kodowany do mniejszej liczby wymiarów (tutaj obrazowo 2 neuronów). Odtwarzając (dekodując) z powrotem zdjęcie zakładamy, że będzie ono podobne. Oczywiście wystąpią pewne straty („błąd rekonstrukcji”), ale mamy nadzieję, że na tyle niewielkie, że dalej rozpoznamy Spidermana.
Załóżmy teraz, że wprowadziłeś inną postać z serii Marvela do tego autokodera, np. Venom’a . W procesie kodowania a następnie dekodowania zrekonstruowana wersja zostanie mocno zmieniona (bo autoenkoder tego się nie nauczył odtwarzać). Czyli będzie duży błąd rekonstrukcji i tego będziemy szukać.
Przy używaniu autokoderów zakłada się, że oszustwo lub anomalie będą cierpieć z powodu wykrywalnego wysokiego błędu rekonstrukcji.
Pobranie i załadowanie danych
Wykorzystamy w tym celu udostępnione w konkursie Kaggle dane transakcyjne dokonane kartami kredytowymi we wrześniu 2013 przez europejskich posiadaczy kart.
Zestaw zawiera transakcje z dwóch dni, w których mamy 492 oszustw (fraud) na 284 807 transakcji. Na pierwszy rzut oka widać, że zbiór jest wysoce niezrównoważony – klasa dodatnia oszustwa (fraud) stanowią 0,172% wszystkich transakcji.
Zbiór danych można pobrać: TUTAJ.
Dane są tylko numeryczne i większość cech (od V1 do V28) są wynikiem transformacji PCA (kiedyś o tym pisałem), która została wykonana w celu zapewnienia poufności danych.
Jedynie dwie cechy nie zostały zmienione. Są to:
- Kwota – kwota transakcji w dolarach $$$,
- Czas – w sekundach, które upłynęły między każdą transakcją a pierwszą transakcją w zbiorze danych.
Wczytujemy podstawowe biblioteki i patrzymy na dane:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
SEED = 2020
pd.options.display.max_columns = 13
df = pd.read_csv('../data/creditcard.csv')
df.sample(3)

Ogólne rozpoznanie
Będziemy przewidywać czy dana transakcja była oszustwem (fraud). Kolumna opisująca nasz cel (TARGET) nazywa się „Class„.
df['Class'].value_counts()

Jak widać mamy mocno niezbalasnowane dane. Transakcje podejrzane (fraud) to ułamek całości. Na temat tego jak sobie z nimi radzić napisano niejeden doktorat i książkę 🙂 W kolejnych postach dokładniej rozpoznam ten temat i podzielę się wnioskami.
Przyglądnijmy się podstawowym informacjom o danych:
df[['Class', 'Amount', 'Time', 'V1', 'V2', 'V3', 'V4', 'V5']].describe()
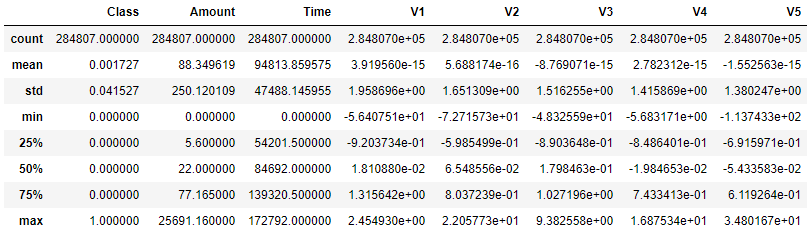
W zbiorze nie mamy żadnych wartości pustych. Z ogólnych statystyk troszkę można byłoby powiedzieć o kwotach i czasie. Natomiast pozostałe cechy od V1 do V28 tak jak było opisane w zbiorze danych wyglądają podobnie (są wynikiem PCA). W tabeli wyglądają bardzo podobnie.
Spójrzmy jeszcze na histogramy (tutaj więcej o tym typie wykresów) zmiennych w zbiorze danych:
df.hist(figsize=(20, 15), bins=50);
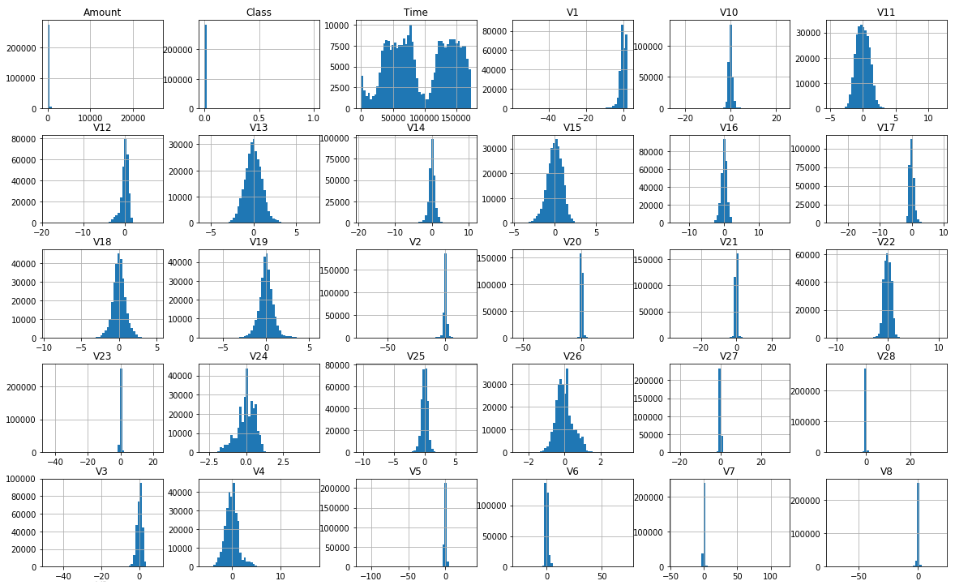
Można zobaczyć, że są dwa rodzaje cech: mające rozkład normalny (np. V11, V13, V15) lub skupione w jednym punkcie (V10, V2, V20).
Czas transakcji
Po krótkiej analizie można zauważyć, że czas podany jest w sekundach od tzw. godziny „zero”.
df['Time'] = df['Time'].apply(lambda x : x / 3600)
df['Time'].hist(bins=50, color='gray');

Widzimy, że mamy spadek transakcji po czasie w godzinach od 1 do 8 oraz w godzinach od 24 do 32. Nie trzeba być detektywem, by się domyślić, że to są zapewne godziny nocne, gdzie znacznie rzadziej wykonywane są transakcje kartami. Natomiast może warto sprawdzić hipotezę, czy to głównie w nocy są dokonywane przestępstwa kartowe (fraud).
Przygotujmy jeszcze dwa osobne zbiory transakcji normalnych oraz fraudowych, aby porównać ze sobą rozkłady i spróbować wyciągnąć kilka obserwacji dla siebie.
df_normal = df[df['Class']==0]
df_fraud = df[df['Class']==1]
def hist_norm_fraud(normal, fraud, bins=20, title='Title',
xlabel='xlabel', ylabel='ylabel'):
plt.figure(figsize=(14, 6))
plt.hist((normal), bins, alpha=0.6, density=True,
label='Normal', color=(100/255, 100/255, 100/255))
plt.hist((fraud), bins, alpha=0.6, density=True,
label='Fraud', color=(198/255, 0.0, 0.0))
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend(loc='upper right', frameon=False)
plt.show()
Przyglądając się rozkładom w podziale na transakcje normalne i fraudowe nie widać znacznych różnic. W oparciu tylko o sam czas nie zbudujemy dobrego klasyfikatora mówiącego fraud czy nie fraud.
hist_norm_fraud(df_normal['Time'], df_fraud['Time'],
bins=np.linspace(0, 50, 50),
title="% of transactions by hour",
xlabel="Transaction time from first transaction in the dataset (hours)",
ylabel="Percentage of transactions (%)")

Kwota transakcji
Jak można było wyczytać z podstawowych metryk i rozkładów, większość transakcji dotyczyła niewielkich kwot. Zapewne kawusie, piwko, bilety, drobne zakupy, itp. Spójrzmy na wyższe kwoty (transakcje dla 100$+), aby sprawdzić czy sprawdza się zasada „jak kraść to miliony„:)
hist_norm_fraud(df_normal['Amount'], df_fraud['Amount'],
bins=np.linspace(100, 1600, 100),
title="% of transactions by amount (transactions \$100 - $1600)",
xlabel="Transaction amount (USD)",
ylabel="Percentage of transactions (%)")

Wystające słupki od 800$ to tak naprawdę 1 transakcja fraudowa (pamiętajcie, że jest ich niecałe 500). Trudno byłoby odróżnić oszustwo od zwykłych transakcji według samej kwoty transakcji.
Skoro przeanalizowaliśmy czas oraz kwotę, to możemy jeszcze sprawdzić ich zależność wykorzystując wykres rozrzutu (tutaj możecie więcej o tym wykresie poczytać):
plt.figure(figsize=(14, 8))
plt.scatter((df_normal['Time']), df_normal['Amount'], alpha=0.6,
label='Normal', color=(100/255, 100/255, 100/255))
plt.scatter((df_fraud['Time']), df_fraud['Amount'], alpha=0.6,
label='Fraud', color=(198/255, 0.0, 0.0))
plt.title("Amount of transaction by hour")
plt.xlabel("Transaction time as measured from first transaction in the dataset (hours)")
plt.ylabel("Amount (USD)")
plt.legend(loc='upper left')
plt.show()

Trudno byłoby narysować linię, która oddziela transakcje fraudową od normalnej.
Korelacje
Popatrzmy jeszcze szerzej na zależności między zmiennymi, które mamy w analizowanym przez Nas zbiorze danych.
corr = df.corr()
plt.figure(figsize=(20,8))
fig = sns.heatmap(corr.round(2), cmap='coolwarm', linewidths=.5, annot=True)
fig.set(title="Correlation Matrix");

Najwyższe korelacje mamy dla zmiennych:
- Amount & V2(-0.53)
- Time & V3 (-0.42)
- Amount & V7 (+0.40)
Macierz korelacji pokazuje, że żaden ze składników PCA V1 do V28 nie ma ze sobą żadnej korelacji. Dodatkowo „Class” (czyli nasza zmienna do modelowania) ma kilka pozytywnych i negatywnych korelacji ze składnikami V, ale nie ma korelacji z czasem i kwotą.
Ale chwika…

… nasze dane są niezbalansowane. Przygotujmy może bardziej zbalansowany zbiór (np. wszystkie fraudy oraz losowa powiedzmy 3 razy więcej transakcji normalnych, bo dlaczego nie :P) i sprawdźmy jeszcze raz korelacje.
df_corrected = pd.concat([df_fraud, df_normal.sample(3*df_fraud.shape[0])])
corr_corrected = df_corrected.corr()
plt.figure(figsize=(20,8))
fig = sns.heatmap(corr_corrected.round(1), cmap='coolwarm', linewidths=.5)
fig.set(title="Correlation Matrix - Balanced data");
plt.show()

Chwilkę wcześnie mówiłem, że zmienne od V1 do V28 nie są ze sobą skorelowane. Jak widać na bardziej zbalansowanym zbiorze wnioski są inne. Dlatego pamiętajcie, by weryfikować na różne sposoby swoje hipotezy, aby nieświadomie nie wyciągnąć błędnych wniosków.
Sprawdźmy jeszcze rozkład dla cechy o największej korelacji na zbalansowanym zbiorze:
hist_norm_fraud(df_normal['V14'], df_fraud['V14'],
bins=100,
title="% of transactions by char V14",
xlabel="Characteristics V14 values",
ylabel="Percentage of transactions (%)")
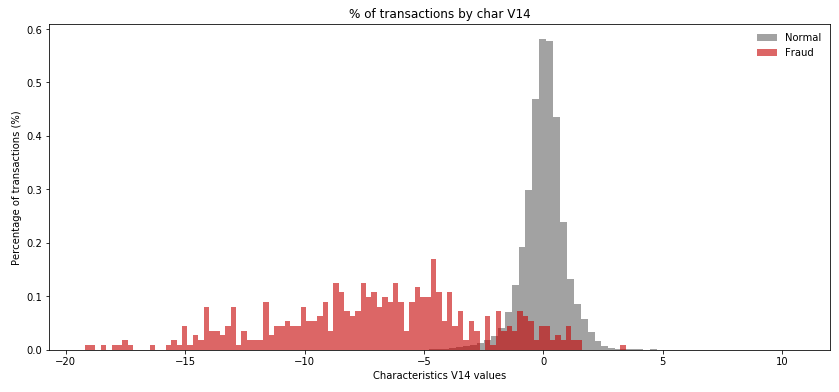
Widać różnice. Będzie można oś zamodelować.
t-SNE dla zabawy
Pamiętacie czym jest t-SNE (t-Distributed Stochastic Neighbor Embedding)? Jest to technika dekompozycji danych, która zmniejsza ich wymiar. Technika t-SNE daje intuicję w jaki sposób dane są rozmieszczone w przestrzeni. Jeśli chcecie więcej o niej poczytać zapraszam TUTAJ.
Wykorzystajmy teraz t-SNE do narysowania naszych transakcji fraudowych i normalnych w przestrzeni. Każda kropka poniżej reprezentuje transakcję. Transakcje bez oszustwa (normalne) są reprezentowane na szaro, a transakcje fraudowe na czerwono. Dwie osie są elementami wyodrębnionymi przez t-SNE.
from sklearn.manifold import TSNE
def tsne_plot(x, y):
tsne = TSNE(n_components=2, random_state=SEED)
X_t = tsne.fit_transform(x)
plt.figure(figsize=(12, 8))
plt.scatter(X_t[np.where(y == 0), 0], X_t[np.where(y == 0), 1],
marker='o', color=(100/255, 100/255, 100/255),
linewidth='1', alpha=0.6, label='Normal')
plt.scatter(X_t[np.where(y == 1), 0], X_t[np.where(y == 1), 1],
marker='o', color=(198/255, 0.0, 0.0), linewidth='1',
alpha=0.6, label='Fraud')
plt.title("t-SNE on balanced data")
plt.legend(loc='best');
plt.show();
X_tsne = df_corrected.drop(['Class','Time','Amount'], axis = 1).values
y_tsne = df_corrected['Class'].values
tsne_plot(X_tsne, y_tsne)
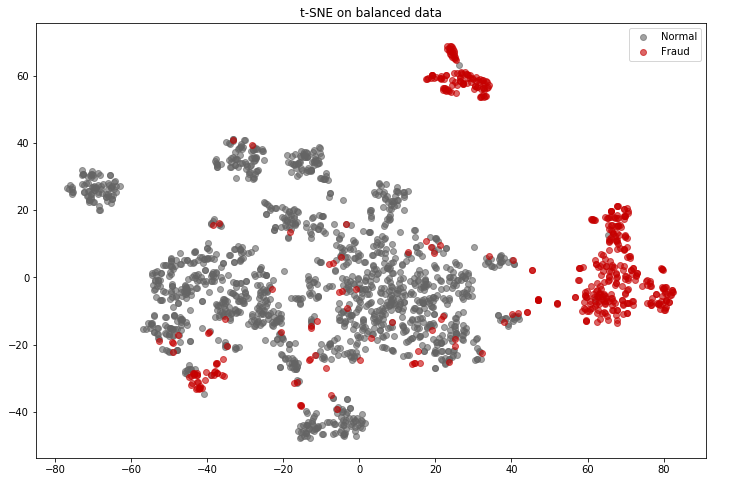
Co to nam mówi? Widać duże skupiska transakcji fraudowych wyodrębnione tylko za pomocą samych podobieństw w przestrzeni. Zatem mamy szanse zbudować fajny model.
Budowa modelu
Normalizowanie danych
Większość charakterystyk, które mamy w zbiorze są wynikiem analizy PCA, zatem są już znormalizowane. To co musimy zrobić, to również znormalizować pozostałe dane (czas i kwota), aby ich duże wartości nie wpłynęły negatywnie na trenowanie sieci.
Wykorzystamy najprościej jak się da wbudowane funkcje z biblioteki sklearn.
from sklearn.preprocessing import StandardScaler
df_norm = df.copy()
df_norm['Time'] = StandardScaler().fit_transform(df_norm['Time'].values.reshape(-1, 1))
df_norm['Amount'] = StandardScaler().fit_transform(df_norm['Amount'].values.reshape(-1, 1))
Podział na próbki
Tutaj warto podkreślić, że podział na próbki będzie odrobinę inny niż ten, do którego jesteśmy przyzwyczajeni. Zakładamy, że fraudy to są anomalie w naszych transakcjach – dziwne, niestandardowe zachowanie na karcie. Zatem, aby jak najlepiej zbudować autoenkoder, który będzie w stanie wyłapać anomalie w transakcjach, stwórzmy nasz autoenkoder tylko na transakcjach normalnych. Wobec tego nie bierzmy do zbioru treningowego fraudów.
Pamiętając o powyższym podzielmy nasz zbiór na zbiór treningowy i testowy (niech będzie 30%):
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df_norm, test_size=0.3, random_state=SEED)
X_train = df_train[df_train['Class'] == 0]
X_train = X_train.drop(['Class'], axis=1)
X_test = df_test.drop(['Class'], axis=1)
y_test = df_test['Class']
print(f'X_train shape: {X_train.shape};')
print(f'X_test shape: {X_test.shape}; y_test shape: {y_test.shape}')

Polecam Wam stosowanie zasady by wyświetlić liczności. W kilku projektach zdarzyły mi się czeskie błędy i trzeba było zawracać szukając błędu.
Wybór architektury
Poniżej proponuję Wam architekturę, którą dobrałem za pomocą prób testując:
- różną ilość warstw ukrytych,
- różną ilość neuronów w warstwach,
- różne funkcje aktywacji,
- szybkość uczenia (learning rate).
Oczywiście definiujemy też zapisywanie modelu (checkpoint) oraz metodę wczesnego zakończenia (early stopping) do nie trenowania dłużej niż jest potrzeba.
Dla przypomnienia: autoenkoder ma symetryczne warstwy gęste („Dense”) kodowania i dekodowania. W tym przypadku zastosowałem architekturę dla autoenkoderów głębokich: zmniejszam ilość danych wejściowych do mniejszej reprezentacji neuronów. Dane wejściowe mają 30 cech. W poniższej architekturze możecie zobaczyć, że najpierw zmniejszam je do 16 kolumn, a następnie do 8. Potem odkodowujemy do takiej samej liczby cech.
W najwęższym miejscu mamy 8 warstw ukrytych, czyli można pomyśleć, że kodujemy 30 cech naszego zbioru w 8 wymiarach. Zatem prawie 4 kolumny upychamy do jednej :).
Jeśli macie troszkę czasu to postarajcie się pobawić. Dajcie znać w komentarzach jaką architekturę dobraliście i o ile lepsze wyniki otrzymaliście!
import tensorflow as tf
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
print(tf.__version__)
2.1.0
learning_rate = 0.00001
input_dim = X_train.shape[1]
input_layer = Input(shape=(input_dim, ))
encoder = Dense(16, activation='elu',
activity_regularizer=regularizers.l1(learning_rate)
)(input_layer)
encoder = Dense(8, activation='relu')(encoder)
decoder = Dense(16, activation='relu')(encoder)
decoder = Dense(input_dim, activation='elu')(decoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
autoencoder.compile(optimizer='adam',
metrics=['accuracy'],
loss='mean_squared_error')
ModelCheck = ModelCheckpoint(filepath='autoencoder_check_point.h5',
monitor='accuracy', save_best_only=True,
verbose=1)
EarlyStop = EarlyStopping(monitor='accuracy', patience=5, verbose=1)
autoencoder.summary()

W artykule o zrobieniu przykładowej sieci gęstej (TUTAJ link) opisałem dwa sposoby budowania sieci w tensorflow. Tam pokazałem sposób sekwencyjny a tutaj funkcjonalny (Fuctional API). Również opisałem techniki, które tutaj stosujemy.
Trenowanie modelu
Dobra to trenujemy model! Skoro mamy „early stopping” to puśćmy przykładowo 500 epok – i tak się zatrzyma jak się już wytrenuje 🙂
history = autoencoder.fit(x=X_train, y=X_train,
epochs=500,
verbose=1,
batch_size = 256,
validation_data = (X_test, X_test),
callbacks = [EarlyStop, ModelCheck]
)

W moim przypadku sieć zatrzymała się po niecałych 50 epokach.
Wczytajmy nasz najlepszy model:
autoencoder = load_model('autoencoder_check_point.h5')
i spoglądamy na krzywą uczenia:
def draw_curves(history, key1='accuracy', ylim1=(0.8, 1.00),
key2='loss', ylim2=(0.0, 1.0)):
plt.figure(figsize=(16,4))
plt.subplot(1, 2, 1)
plt.plot(history.history[key1], "r--")
plt.plot(history.history['val_' + key1], "g--")
plt.ylabel(key1)
plt.xlabel('Epoch')
plt.ylim(ylim1)
plt.legend(['train', 'test'], loc='best')
plt.subplot(1, 2, 2)
plt.plot(history.history[key2], "r--")
plt.plot(history.history['val_' + key2], "g--")
plt.ylabel(key2)
plt.xlabel('Epoch')
plt.ylim(ylim2)
plt.legend(['train', 'test'], loc='best')
plt.show()
draw_curves(history, key1='accuracy', ylim1=(0.0, 0.95),
key2='loss', ylim2=(0.0, 0.8))

Sprawdzenie mocy modelu
Moc modelu dla każdego może oznaczać coś innego. Jest mnóstwo metryk, które można wykorzystać do oceny jak nasz model działa.
Sprawdźmy najpierw jak mocno różni się rozkład transakcji normalnych od fraudowych patrząc na błąd z rekonstrukcji
X_test_pred = autoencoder.predict(X_test)
mse = np.mean(np.power(X_test - X_test_pred, 2), axis=1)
df_error = pd.DataFrame({'Class': y_test, 'reconstruction_error': mse})
hist_norm_fraud(df_error[df_error['Class'] == 0]['reconstruction_error'],
df_error[df_error['Class'] == 1]['reconstruction_error'],
bins=50,
title="Reconstruction error histogram on test sample",
xlabel="Reconstruction error",
ylabel="Percentage of transactions (%)")

Całkiem nieźle. Większość transakcji z wysokim rozrzutem to rzeczywiście transakcje fraudowe.
Sprawdźmy jeszcze moją ulubioną krzywą ROC:
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(df_error['Class'],
df_error['reconstruction_error'])
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(12, 6))
plt.plot(fpr, tpr, color=(198/255, 0.0, 0.0),
label='AUC = %0.4f'% roc_auc, linewidth=3)
plt.plot([0,1],[0,1], color='black', linestyle =':', label='Random value')
plt.title('Receiver Operating Characteristic curve (ROC)')
plt.legend(loc='lower right', frameon=False)
plt.xlim([-0.001, 1])
plt.ylim([0, 1.001])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show();

Można jeszcze dorobić mnóstwo innych metryk. Niemniej jednak najważniejsze jest jak model będzie wykorzystywany i przez kogo.
Polityka użycia
Jest to ostatni krok, gdzie tak naprawdę zaczyna się sztuka. W tym miejscu należałoby wziąć decydenta lub decydentów i wspólnie przy stole podyskutować co robimy. Warto byłoby omówić:
- czy chcemy użyć modelu (AUC >0.95 to naprawdę już świetne różnicowanie i rzadko na danych rzeczywistych udaje mi się taki wynik osiągnąć),
- jakie mamy możliwości, aby po zablokowaniu transakcji zadzwonić on-line do klienta czy to na pewno jego transakcja,
- czy nie warto zwiększyć liczby blokowanych transakcji kosztem np. wysłania wiadomości SMS z możliwością odpowiedzi zwrotnej przez klienta (np. 1-blokuj, a jak nie wyśle to po godzinie transakcja wyjdzie),
- czy transakcji powyżej jakiegoś progu automatycznie nie kierować do ręcznego przeglądu w celu monitorowania większych zagrożeń dla Banku i klientów,
- … itp. itd.
Często podczas burzy mózgów i dyskusji rodzą się nowe pomysły.
Porównując wyniki dla różnych przyjętych progów można byłoby powiedzieć np. na postawie przyjętego kosztu transakcji podejrzanej i możliwości kontaktu z klientami „Obcinajmy dla błędów rekonstrukcji większych niż 3„:
treshold=3
fig, ax = plt.subplots(figsize=(14, 8))
ax.plot(df_error[df_error['Class'] == 0].index,
df_error[df_error['Class'] == 0]['reconstruction_error'],
marker='o', linestyle='', color=(100/255, 100/255, 100/255),
label= 'Normal')
ax.plot(df_error[df_error['Class'] == 1].index,
df_error[df_error['Class'] == 1]['reconstruction_error'],
marker='o', linestyle='', color=(198/255, 0.0, 0.0),
label= 'Fraud')
ax.hlines(treshold, ax.get_xlim()[0], ax.get_xlim()[1],
colors="black", zorder=100, label='Threshold')
ax.legend()
plt.title("Reconstruction error for test sample")
plt.ylabel("Reconstruction error")
plt.xlabel("Data point index")
plt.show();

Wynik takiej decyzji można zauważyć przykładowo w tak zwanej confusion matrix (ang):
from sklearn.metrics import confusion_matrix
y_pred = [1 if e > treshold else
0 for e in df_error['reconstruction_error'].values]
conf_matrix = confusion_matrix(df_error['Class'], y_pred)
plt.figure(figsize=(5, 5))
sns.heatmap(conf_matrix, xticklabels=['Normal','Fraud'],
yticklabels=['Normal','Fraud'], annot=True,
fmt="d", cmap='coolwarm');
plt.title('Confusion matrix')
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()

Przy takiej polityce można zablokować 1144+109 transakcji, z czego transakcjami podejrzanymi byłoby 8.7%. Na pozostałym zbiorze widzimy, że zostałoby tylko 25 transakcji podejranych (czyli mniej niż 19% z wszystkich transakcji). Oczywiście jeśli byłyby to transakcje na milionowe kwoty to pewnie w ramach dyskusji z decydentami wybralibyśmy optymalne parametry.
Podsumowanie
Nie był to oczywisty projekt. Wykorzystaliśmy wiedzę o autoenkoderach by wyłapać nieuczciwe transakcje. Model zbudowaliśmy tylko na „czystych” danych bez transakcji podejrzanych. Po odrobinie dokręcania architektury nasz model wydaje się super wyłapywać transakcje fraudowe. Dodatkowo wspólnie z szefami i szefowymi wspólnie zaakceptowaliśmy po „ciężkich” dyskusjach model i można wdrażać 🙂
BRAWO MY!
Pozdrawiam serdecznie,

Image by Gerd Altmann from Pixabay



Przy tak niezbalansowanych klasach korzystanie z ROC-AUC jest bezsensowne i tylko wprowadza ludzi w błąd. Jeśli nie rozwiążemy problemu dysproporcji przed trenowaniem i chcemy korzystać z AUC to tylko PR-AUC, albo F1-score, albo Matthew’s correlation. Wtedy możemy mówić o jakiejkolwiek skuteczności.
ew. Youden J Index
Hej Krystian!
dzięki za informacje! Masz racje – dla niezbalansowanego zbioru można byłoby dodatkowo pokazać dodatkowe metryki o których wspomniałeś – wtedy byłby większy obraz całości.
Niemniej jednak nie zgadzam się z Tobą, że ROC jest bezsensowne. Gdyby model poprawnie nie różnicował klientów wówczas ROC byłoby znacznie niższe niższy.
Niezależnie od metryk jakie są pokazywane to i tak najważniejsza jest polityka użycia, dzięki czemu widać jak na dłoni jak będzie model działał 🙂 Moim zdaniem ten tutaj jest całkiem rozsądny ;P
Pozdrawiam serdecznie,
Mirek
Jest bezsensowne bo to jest metryka wrażliwa na dysproporcje klas. ROC faworyzuje większą populację klasy dlatego wyszedł ci tak wysoki wynik (zobacz ilość false positive), to ta sama sytuacja co z używaniem R^2 w regresji mając ogromną ilość zmiennych (R^2 z każdą kolejną zmienną będzie rosnąć).
Bardzo fajny wpis, ale w kwestii oceny na bazie ROC zgadzam się z Krystianem.
https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics
Przykładowo:
import numpy as np
import pandas as pd
from sklearn.metrics import classification_report
values_true = np.zeros(10000)
values_true[0] = 1 # only one positive case
values_preds = np.zeros(10000) # model predicts every case as 0
pd.DataFrame(classification_report(values_true,
values_preds,
output_dict=True))
Zerknij, co dzieje się z macro avg.
Zdrowia!
Dzięki Adam! Postaram się doczytać o metrykach dla mocno niezbalansowanych zbiorów zgodnie z Waszymi radami i postaram się podzielić nimi w jakimś kolejnym wpisie jak je lepiej poznam 🙂 Do usłyszenia!
Świetny artykuł.
Dla takich warto regularnie przeglądać Twojego bloga.
Dzięki za miłe słowa! 🙂