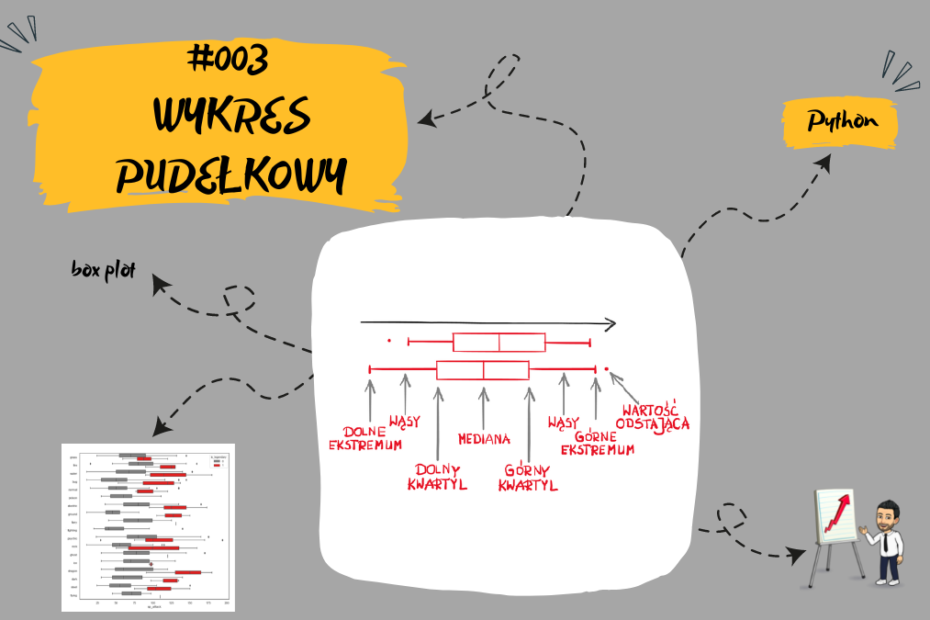
Wykres pudełkowy / skrzynkowy (ang. box plot) jest ciekawą formą wizualnej prezentacji rozkładu danych (przez ich kwartyle).
Wykres pudełkowy tworzy się rysując prostokąt (pudełko / skrzynkę). Jego lewy lub dolny bok (zależy czy wykres prezentujemy w postaci pionowej lub poziomej) wyznaczony jest przez pierwszy kwartyl zaś przeciwny bok przez trzeci kwartyl. Natomiast wewnątrz prostokąta znajduje się linia określająca medianę. Linie rozciągające się równolegle od skrzynek nazywane są „wąsami”, które są używane do wskazania zmienności poza dolnym i górnym kwartylem. Standardowo wąsy mają długość półtorej wartości rozstępu ćwiartkowego. A tutaj co to oznacza w nawiązaniu gdyby nasza cecha, którą badamy miała rozkład normalny:

W najprostszej formie lewy/dolny koniec lewego/dolnego odcinka wyznacza najmniejszą wartość w zbiorze, natomiast przeciwległy to wartość największa.
Wartości odstające są czasami wykreślane jako pojedyncze kropki, które są zgodne z wąsami.
Główne zalety
Chociaż wykresy pudełkowe mogą wydawać się prymitywne w porównaniu do wykresu histogramu lub wykresu gęstości, to ich zaletą jest, że zajmują mniej miejsca. Jest to przydatne przy porównywaniu rozkładów między wieloma grupami lub zestawami danych.
Dodatkowo łatwo z nich wyczytać takie informacje jak:
- dolny / górny kwantyl,
- mediana,
- czy dane są symetryczne,
- jak ściśle są pogrupowane dane,
- ile jest wartości odstających i jakie mają wartości,
- jaka jest skośność danych i w którym kierunku.
Główne wady
W przypadku osób, które nie są za pan brat z matematyką na wstępie należy wyjaśnić pojęcia takie jak mediana, dolny / górny kwartyl oraz zakres wąsów.
Moim zdaniem najprościej można zobrazować to przykładem: załóżmy, że mamy 1.000 osób poustawianych w kolejności od najmniejszych do największych. Dolny kwartyl to osoba numer 250. Mediana to osoba numer 500, górny kwartyl to osoba 750. Wąsy w tym przypadku kończyłyby się na 4 osobie od początku i od końca.
Kod w Python
Nie wiem czemu ale najbardziej do tego rodzajów wykresów upodobałem sobie bibliotekę seaborn (pewnie dlatego, że najprościej :)).
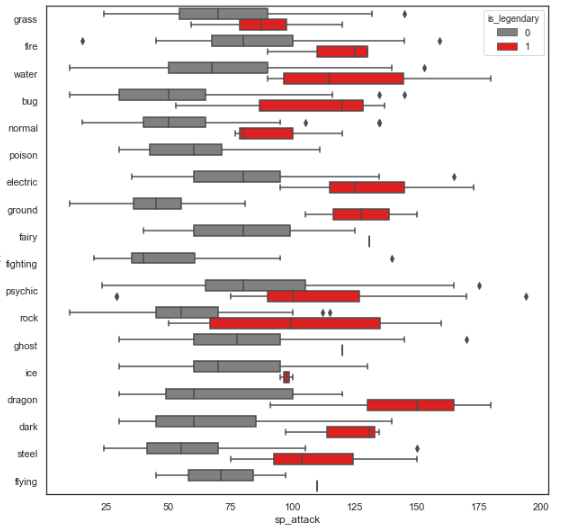
Przykładowe wykresy zaprezentuję na podstawie zbioru Pokemonów, gdzie możemy spojrzeć w podziale na rodzaj pokemona na ich siłę:
import pandas as pd
import seaborn as sns
pd.options.display.max_columns = 100
Wczytanie danych:
#https://www.kaggle.com/rounakbanik/pokemon#pokemon.csv
df = pd.read_csv('../data/pokemon.csv')
df.head()

sns.set(rc={'figure.figsize':(10,10)})
sns.set_style("white")
ax = sns.boxplot(x="sp_attack", y="type1", data=df, orient='h', color = 'gray')

Od razu rzuca się w oczy, że:
- najmniejsza mediana jest dla pokemonów typu „fighting”
- natomiast najmniejszy kwartyl jest dla bug”
- największy rozrzut pomiędzy kwartylami jest dla typu „dragon”
- najsilniejszy pokemon jest „psychic” (widać go jako obserwację odstającą).
- jeśli chciałbym losowo trafić na pokemona silniejszego od reszty to chciałbym losować go z puli pokemonów typu „psychic” lub „flying” ponieważ mają najwyższą medianę wyższą niżz pozostałe grupy..
A Wy dostrzegacie coś jeszcze co warto dopisać? Jeśli tak zostawcie proszę informację w komentarzach 🙂
A tutaj jeszcze przykład jak łatwo dodać jeszcze podział do wcześniejszego wykresu po kolejnym wymiarze: czy pokemon jest legendarny (1) czy nie (0):
ax = sns.boxplot(x="sp_attack", y="type1", data=df, orient='h', palette = ['gray','red'], hue = 'is_legendary')
Pozdrawiam serdecznie,




Pingback: #025 Swarm plot (swarmplot) - influencer AI
Pingback: #025 Wykres roju (swarmplot) - Mirosław Mamczur
Pingback: #019 Wykres świecowy (Candlestick Chart) - Mirosław Mamczur