


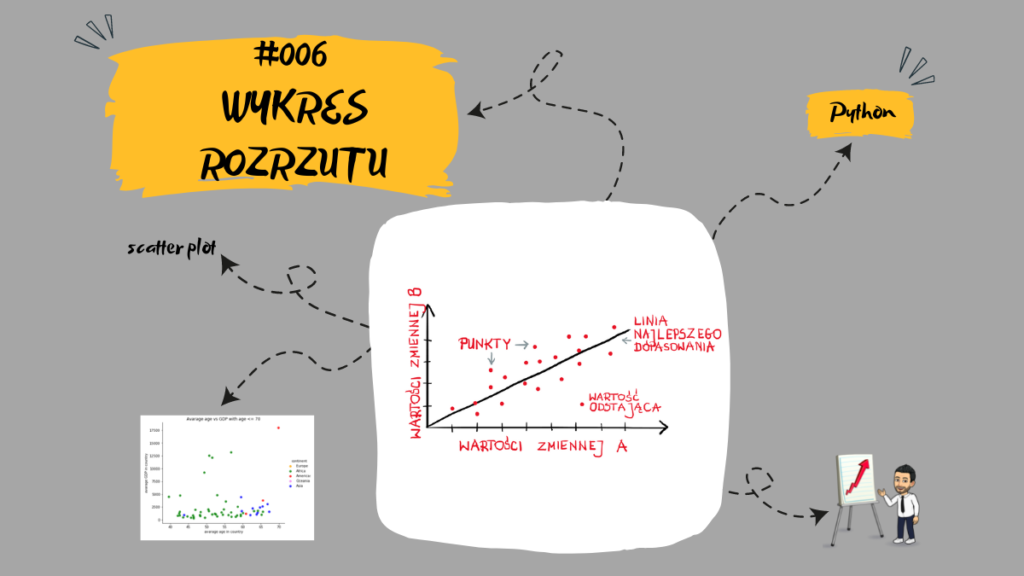
Wykres rozrzutu ma wiele nazw. Znany jest jeszcze jako: wykres punktowy, wykres X-Y, wykres rozproszenia lub „Scattergram”.
Wykres rozrzutu jest zbiorem punktów umieszczonych na współrzędnych kartezjańskich (układ osi X i Y pod kątem prostym względem siebie) do wyświetlania wartości z dwóch zmiennych. Prościej mówiąc jedna oś odpowiada wynikom dla jednej zmiennej, natomiast druga oś odpowiada wynikom drugiej zmiennej. Skala w wykresie rozrzutu zawsze odzwierciedla skalę dla danej zmiennej a każdy punkt na wykresie odpowiada poszczególnym wartościom zmiennych.
Zazwyczaj wykres ten stosuje się do porównywania zmiennych ilościowych. Niemniej jednak również można go użyć do zmiennych kategorycznych (wówczas jeśli jedna cecha ma 3 wartości kategoryczne a druga jest ciągła, to otrzymamy trzy linie). Natomiast w przypadku obu zmiennych kategorycznych (np. po 3 kategorie) otrzymamy na wykresie 9 punktów i niewiele nam to powie :).

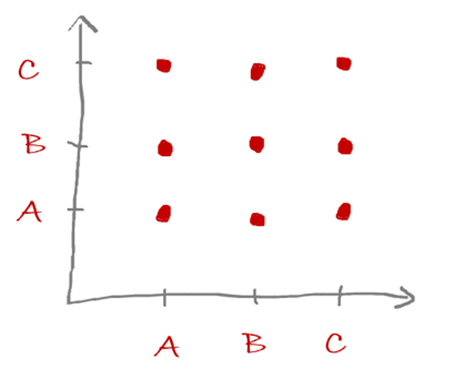
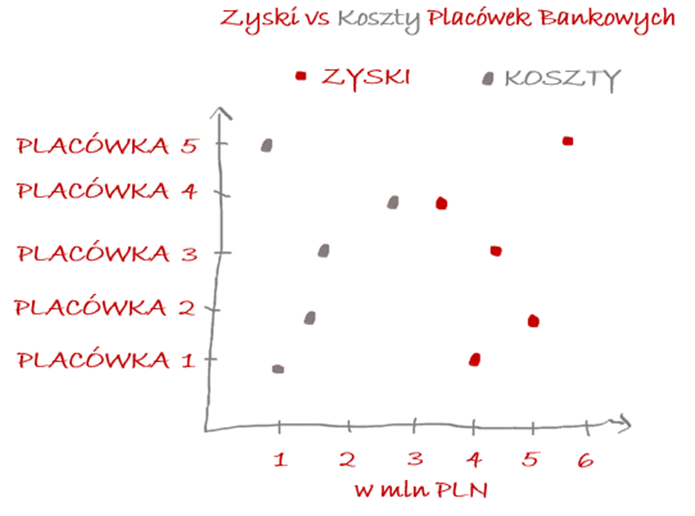
Warto pamiętać, że punkt jest najprostszym sposobem prezentacji danych! Pojedynczy punkt bardzo precyzyjnie może pokazać odległość od punktu odniesienia (np. początku układu współrzędnych) lub innych punktów. Zatem warto stosować ten wykres również do wizualizacji dla pojedynczych wartości zmiennych.

Główne zalety
Wykres rozrzutu służy do badania związku między 2 zmiennymi. Można z nich wyciągnąć informacje o trzech głównych elementach:
- Istotności zależności: silna / słaba / brak. Siła korelacji może być określona przez to, jak ściśle upakowane są punkty na wykresie.


- Rodzaj korelacji: liniowa (dodatnia lub ujemna), wykładnicza, w kształcie U, sinusoidy itp. Czyli tak naprawdę, jeśli występuje korelacja, to jaka jest zależność między zmiennymi.


- Łatwa identyfikacja czy są wartości odstające. Punkty, które kończą się daleko poza ogólnym skupieniem punktów, są znane jako wartości odstające.


Uwaga! Warto pamiętać, aby pokazać czasami różne podgrupy, dzięki czemu można ujawnić ukryte wzorce w naszych danych (np. płeć patrząc na wykres rozrzutu wiek & płeć).
Najczęstsze błędy
- Używanie wykresu do zmiennych kategorycznych – w tym przypadku wykres nie da nam zbyt wielu informacji.
- Wykorzystywanie wykresu do zbyt dużej próbki danych (overplotting). Oznacza to, że większość danych pokrywa się na wykresie i staje się on nieczytelny. Można temu przeciwdziałać na kilka sposobów:
- zmniejszyć same kropki,
- narysować dodatkowo rozkład cech,
- lub najprościej wylosować mniejszy zbiór (np. 5%).
Kod w Python
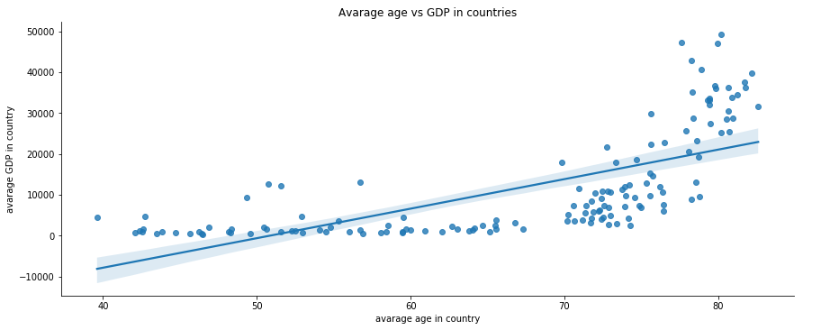
Dla przykładu wizualizacji wykresu rozrzutu wykorzystamy dwie dane: PKB (ang. GDP) kraju oraz średni wiek populacji. Dzięki temu będziemy mogli poszukać zależności.
Zacznijmy od wczytania bibliotek oraz pobrania danych:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
url = 'https://raw.githubusercontent.com/plotly/datasets/master/gapminderDataFiveYear.csv'
df = pd.read_csv(url)
df = df[df['year'] == 2007]
df.head()


Podstawową biblioteką jest matplotlib. Poniżej przykład, jak na szybko można narysować wykres rozrzutu:
plt.figure(figsize=(15,6))
plt.plot("lifeExp", "gdpPercap", data=df, linestyle='none', marker='o')
plt.xlabel('avarage age in country', fontsize='12',
horizontalalignment='center')
plt.ylabel('avarage GDP in country', fontsize='12',
horizontalalignment='center')
plt.title('Avarage age vs GDP in countries')
plt.show()


Inną biblioteką, która bardzo upraszcza rysowanie wykresów jest seaborn. Można chociażby wykorzystać wykres lmplot. Dokumentację znajdziecie tutaj: https://seaborn.pydata.org/generated/seaborn.lmplot.html
Poniżej prosty przykład, gdzie za pomocą jednego parametru mamy dodatkową przygotowaną regresję liniową.
fig = sns.lmplot(x="lifeExp", y="gdpPercap", data=df, fit_reg=True,
truncate=True, height=5, aspect=2.5)
fig.set_axis_labels("avarage age in country", "avarage GDP in country")
fig.set(title='Avarage age vs GDP in countries');

Największą zaletą jest to, że w bardzo prosty sposób można dodać inne kolory w zależności od różnych kategorii. W tym przypadku zobaczcie jak wygląda to na poszczególnych kontynentach. Widzicie od razu jakieś wnioski?
palette1 = ['blue','orange','green','red','violet',]
fig1 = sns.lmplot(x="lifeExp", y="gdpPercap", data=df, fit_reg=False,
legend=True, height=5, aspect=2.5, hue='continent',
palette=palette1)
fig1.set_axis_labels("avarage age in country", "avarage GDP in country")
fig1.set(title='Avarage age vs GDP in countries by continent');
palette2 = ['b','g','r']
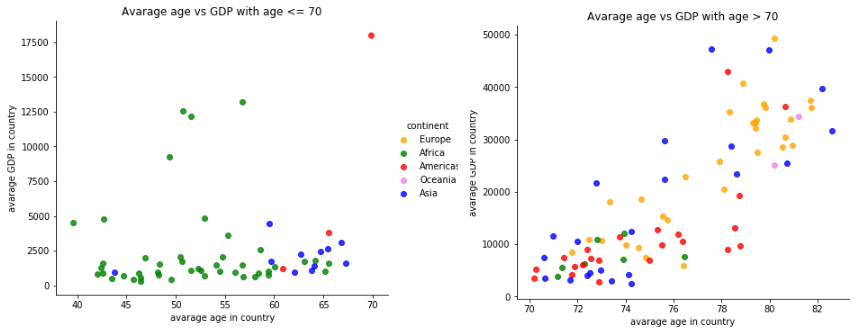
fig2 = sns.lmplot(x="lifeExp", y="gdpPercap", data=df[df['lifeExp']<=70],
fit_reg=False, legend=True, height=5, aspect=1.25,
hue='continent',palette=palette2)
fig2.set_axis_labels("avarage age in country", "avarage GDP in country")
fig2.set(title='Avarage age vs GDP with age <= 70')
palette3 = ['orange','green','red','violet','blue']
fig3 = sns.lmplot(x="lifeExp", y="gdpPercap", data=df[df['lifeExp']>70],
fit_reg=False, legend=True, height=5, aspect=1.25,
hue='continent',palette=palette3)
fig3.set_axis_labels("avarage age in country", "avarage GDP in country")
fig3.set(title='Avarage age vs GDP with age > 70');



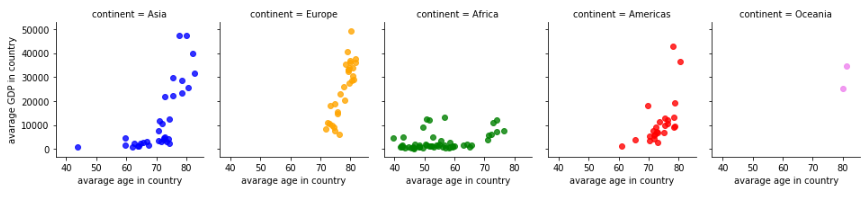
Można też za pomocą argumentu „col” zdefiniować automatycznie podział na osobne wykresy:
palette1 = ['blue','orange','green','red','violet',]
fig1 = sns.lmplot(x="lifeExp", y="gdpPercap", data=df, fit_reg=False,
legend=True, height=3, aspect=0.9, hue='continent',
palette=palette1, col='continent')
fig1.set_axis_labels("avarage age in country", "avarage GDP in country");

W przypadku dużej ilości punktów tak jak wspominałem, można narysować wykres rozrzutu wraz z rozkładem:
sns.jointplot(x=df["lifeExp"], y=df["gdpPercap"], kind='scatter');


Albo przedstawić wykres rozrzutu za pomocą podobnych wykresów 🙂
sns.jointplot(x=df["lifeExp"], y=df["gdpPercap"], kind='hex');


sns.jointplot(x=df["lifeExp"], y=df["gdpPercap"], kind='kde');


Mam nadzieję, że będziecie mieli okazję wykorzystać powyższą wiedzę 🙂
Pozdrawiam Was serdecznie,

