



Od miesięcy odkładałem plan nauczenia się wyrażeń regularnych (tzw. regexów), ponieważ po pierwszym zetknięciu z nimi wydawały mi się dość skomplikowane, ponadto ta wiedza wydawała mi się niepotrzebna.
Dopiero po jednym z ostatnich zadań w pracy, które polegało na oczyszczeniu tytułów transakcji na potrzeby przygotowania algorytmów i modeli pod listy sankcyjne, doceniłem moc wyrażeń regularnych. Ponadto jak poznałem podstawy, wykorzystałem tę wiedzę w konkursie DataWorkshop, gdzie zająłem drugie miejsce. Mam nadzieję, że ta wiedza przyda się również Tobie!
Czym są wyrażenia regularne?
W uproszczeniu wyrażenia regularne to po prostu wzorzec, który opisuje określony tekst do wyszukania. Dodatkowo warto wspomnieć, że nie jest to żadna biblioteka czy język programowania.
Zwykle wyrażenie regularne w nazywamy „regex” lub „regexp” od skrótu angielskiego terminu: regular expressions.


Troszkę historii
Koncepcję wyrażeń regularnych sformalizował amerykański matematyk Stephen Cole Kleene w latach 50. XX wieku. Wyrażenia regularne weszły do powszechnego użytku w 1968 roku. Wykorzystywano je w dwóch celach – dopasowywanie wzorców w edytorze tekstu i analiza leksykalna w kompilatorze.
Regex’y zostały następnie przyjęte przez szeroką gamę programów, przy czym te wczesne formy zostały ujednolicone w standardzie POSIX.2 w 1992 roku. Dodatkowo w 1997 roku Philip Hazel opracował PCRE (Perl Compatible Regular Expressions), który stara się naśladować funkcjonalność wyrażeń regularnych Perla i jest używany przez wiele nowoczesnych narzędzi.
Obecnie wyrażenia regularne są szeroko obsługiwane w językach programowania i zaawansowanych edytorach tekstu. Obsługa regex jest częścią standardowej biblioteki wielu języków programowania, w tym Java i Python.
Podstawowa składnia regex, którą warto znać
Skoro już wiemy, że regex to wzorzec, który pomaga wyszukać fragment tekstu, to warto zacząć od poznania podstawowych wyrażeń regularnych.
Podzielimy je jeszcze na trzy grupy: znaki, kwantyfikatory i grupowania.
Znaki
Znaki to po prostu sposób zapisu jakiego znaku będziemy w danym ciągu szukać.
- \d – dowolna liczba
- \D – nie liczba
- \w – dowolna litera
- \W – nie litera
- \s – biały znak
- \S – nie biały znak
- . – dowolny znak
- \ – wyjściowy znak
- \b – granica słowa
- \B – nie granica słowa
- ^ – początek ciągu
- $ – koniec ciągu
Zastanawiasz się, po co te wszystkie kody i z czym to się je? Już wyjaśniam. Przygotujmy nasze pierwsze regex’y dla poniższego zdania.
Ala ma kota, a kot ma Alę.
Poniżej kilka prostych regex’ów w oparciu o powyższe podstawy:
- „a” – znajduje literkę „a”

- „^Al” – znajdzie nam ciąg znaków rozpoczynających się od „Al”

- „lę.$” – znajdzie ciąg znaków kończących się na „lę.”

- „\b” – znajduje granice słów

Kwantyfikatory
- * – 0 lub więcej
- + – 1 lub więcej
- ? – 0 lub 1
- {} – dokładna liczba znaków
- {min, max} – zakres liczby znaków
Skomplikujmy odrobinkę. Zamiast zdania popatrzmy na zlepek liter, gdzie łatwiej będzie wyjaśnić zasadę działania kwantyfikatorów:
aa, ab, abb, abbbb, ac, abcd, abbc, accd, acd, acdb, acabb
A teraz kilka kolejnych regexów:
- „ab*” – dopasowuje ciąg, w którym po „a” następuje „b” zero, jeden lub więcej razy

- „ab+” – jak wyżej, ale musi być przynajmniej jedno „b”

- „ab?” – może być pojedyncze b lub brak (ale podwójne już nie!)

- „a?b+$” – możliwe „a”, po którym następuje jedno lub więcej „b” na końcu ciągu

- „ab{2}” – szuka łańcucha gdzie po „a” są dokładnie 2 „b”

- „ab{2,4}” – szuka łańcucha gdzie po „a” jest od 2 do 4 „b”

- „^.{3}” – ciąg zaczynający się od 3 dowolnych znaków

Jak widzisz, wyrażenia regularne stają się już coraz ciekawsze i mam nadzieję prostsze 🙂.
Grupowanie
- [ ] – dopasowuje wszystkie znaki w nawiasach
- [^ ] – dopasowuje wszystkie znaki spoza nawiasów
- () – grupowanie
- | – albo
Użyjmy teraz zdania:
Wykorzystałem rabarbar do zrobienia 10 soków, 2 ciast i 8 galaretek.
I kilka zastosowań grupowań:
- ” [0-7]” – znajdź dowolną liczbę pomiędzy 0 a 7 poprzedzoną spacją.

- „a.[0-9]” – poszukaj ciąg zaczynający się od „a”, po którym następuje dowolny znak, a następnie cyfra.

- „[A-Z, ]” – znajdź wszystkie duże litery, przecinki i spacje

- „(a|b|r)* ” – ciąg, który składa się z samych liter „a” lub „b” lub „r” i kończy się spacją

Pomoc w nauce – https://regex101.com/
Ta strona posłużyła mi do stworzenia powyższych wizualizacji dla Ciebie. Jak pracuję nad nowym regexpem chętnie z niej korzystam.
Jak działa? Po pierwsze na górze (1) piszę regex’a, którego aktualnie konstruuję, a poniżej (2) mogę wpisać przypadki testowe, by sprawdzić, czy prawidłowo działa. Dodatkowo na stronie widzę (3) podpowiedzi.
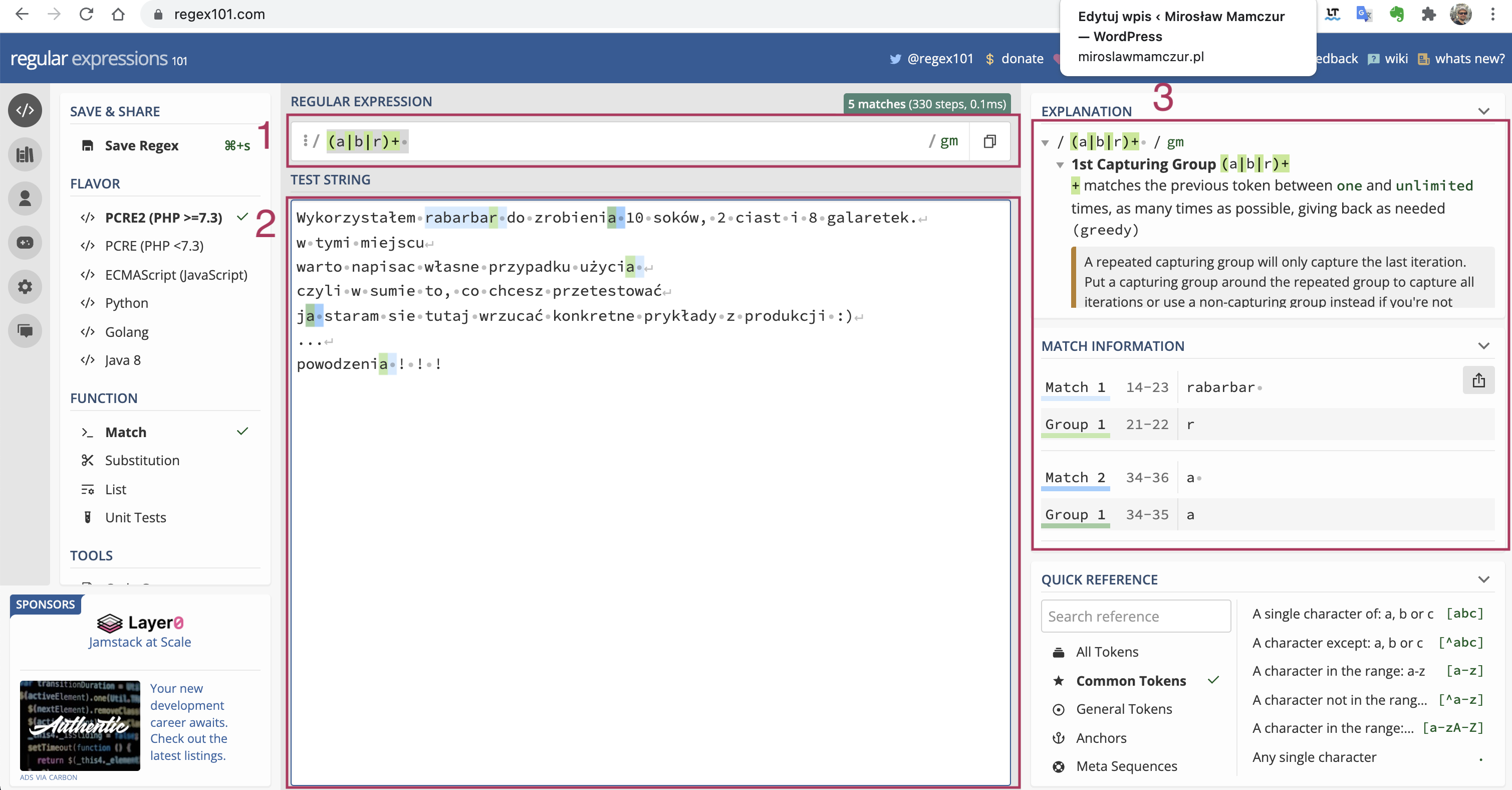
Zatem polecam Ci z całego serducha tę stronę internetową, abyś na niej potrenował lub używał do pisania lub walidacji własnych regex’ów.
Super! Znamy podstawy! Zatem teraz spróbujmy wykorzystać tę wiedzę do bardziej praktycznych przykładów, które możemy jako mistrzowie od danych napotkać w codziennej pracy. Tylko najpierw zapoznajmy się z biblioteką re w Python.
Wyrażenia regularne w Python, czyli bilbioteka re
Python ma wbudowany pakiet o nazwie re, którego można używać do pracy z wyrażeniami regularnymi. Zaimportuj moduł re:
import re
Moduł re oferuje zestaw funkcji, które pozwalają nam wyszukać odpowiedni ciąg znaków:
- findall – zwraca listę zawierającą wszystkie dopasowania,
- search – wraca obiekt Match, jeśli istnieje dopasowanie w dowolnym miejscu ciągu,
- split – zwraca listę, w której łańcuch został podzielony przy każdym dopasowaniu,
- sub – zastępuje jedno lub wiele dopasowań nowym ciągiem.
Przykład 1 – numery telefonów
Jeśli nie wymusimy na frontend sposobu wpisywania numerów telefonów, wówczas możemy doświadczyć kreatywności użytkowników. A wtedy naszą rolą jest… posprzątanie danych. I tutaj mogą nam się mocno przydać wyrażenia regularne.
Załóżmy, że mamy dane w postaci jakichś numerów telefonów. Chcemy podzielić te numery na 2 oddzielne elementy: numer kraju (pierwsze 2 cyfry) i pozostała część (9 cyfr). Jak zobaczysz poniżej przygotowane przeze mnie przykładowe dane, to wzorce liczbowe nie zawsze są spójne, tj. mają niespójne nawiasy, łączniki czy spacje. Jednak za pomocą wyrażeń regularnych możemy łatwo uchwycić grupy liczbowe.
import pandas as pd
df = pd.DataFrame(['+48 601 602 603',
'(48) 601-602-603',
'(+48)601602603',
'+48 601602603',
'+48601602603',
'48601602603',
],
columns=['phone_orig'])
phone_pattern = ".*?(\\d{2}).*(\\d{3}).*(\\d{3}).*(\\d{3})"
df['country_prefix'] = df['phone_orig'].apply(lambda x: \
re.sub(phone_pattern, r'+\1', str(x)))
df['phone'] = df['phone_orig'].apply(lambda x: \
re.sub(phone_pattern, r'\2\3\4', str(x)))
df

Wyrażenie regularne – konstrukcja:
- .*? – 0 lub 1 znak do uwzględnienia opcjonalnego otwartego nawiasu
- (\d{2}) – pierwsza grupa przechwytywania 2-cyfrowe znaki
- .* – 0 lub więcej znaków do uwzględnienia opcjonalnego nawiasu zamykającego, łącznika i spacji
- (\d{3}) druga grupa przechwytywania – 3-cyfrowe znaki
- .* – 0 lub więcej znaków do uwzględnienia opcjonalnego nawiasu zamykającego, łącznika i spacji
- (\d{3}) trzecia grupa przechwytywania – 3-cyfrowe znaki
- .* – 0 lub więcej znaków do uwzględnienia opcjonalnego nawiasu zamykającego, łącznika i spacji
- (\d{3}) czwarta grupa przechwytywania – 3-cyfrowe znaki
Przykład 2 – email
Korzystając z wiedzy, którą mamy już przyswojoną (dzięki najlepszemu blogowi na świecie 🙂 ) na temat wyrażeń regularnych, przygotujmy teraz przykład ciągów zawierających zarówno litery, jak i cyfry. Załóżmy, że mamy listę e-maili w ramce danych i chcemy je porozbijać na login, informacja o domenie i tld (top level domain).
df = pd.DataFrame(['miroslaw_mamczur@miroslawmamczur.pl',
'miroslaw.mamczur@gmail.com',
'miroslawmamczur@wp.pl',
'mm@wroclaw.com.pl',
'hmm@pwr.edu.pl',
'miroslaw123456789@ubs.com',
],
columns=['email_full'])
email_pattern = "([a-zA-Z0-9\\_\\-\\.]+)@([a-zA-Z]+).(.+)"
df['email_user'] = df['email_full'].apply(lambda x: \
re.sub(email_pattern, r'\1', str(x)))
df['email_domain_name'] = df['email_full'].apply(lambda x: \
re.sub(email_pattern, r'\2', str(x)))
df['email_tld_name'] = df['email_full'].apply(lambda x: \
re.sub(email_pattern, r'\3', str(x)))
df

Wyrażenie regularne – konstrukcja:
- ([a-zA-Z0-9\_\-\.]+) – odpowiada za użytkownika; regex pozwala na małe i duże litery, cyfry i znaki specjalne: podkreślenia, łączniki i kropki,
- @ – trzonem regexpa, ma być znak @, który rozbija nasze wyrażenie regularne na części
- ([a-zA-Z]+) – druga grupa przechwytywania (nazwa domeny) – szukamy 1 lub więcej małych i wielkich liter
- . – pojedynczy znak kropki
- (.+) – trzecia grupa przechwytywania – pozwala na 1 lub więcej znaków
Przykład 3 – sprawdzanie „silnego” hasła
Jeśli chcesz zbudować sprawdzanie jakości* hasła, to możesz w prosty sposób wykorzystać regex’y.
*w sumie ważniejsza jest moim zdaniem ilość znaków niż skomplikowanie, ale przyjmuję nazewnictwo używane przez większość
df = pd.DataFrame(['same male literki',
'123456',
'123456 i male literki',
'małe i duże LITERKI',
'małe i duże LITERKI + 123',
'M1r0sław!',
'to_Je5t Długie.H@sło;Jak+Lubię',
],
columns=['password'])
password_pattern = "(?=^.{8,}$)((?=.*\w)(?=.*[A-Z])\
(?=.*[a-z])(?=.*[0-9])(?=.*[|!@#'$%&\/\(\)\?\^\'\\\+\-\*]))^.*"
df['password_frag'] = df['password'].apply(lambda x: 'strong' if re.search(password_pattern, str(x)) else 'weak')
df

Wyrażenie regularne – konstrukcja:
- (?=^.{8}$) – odpowiada za to, aby było minimum 8 dowolnych znaków
- (?=.\w) – cokolwiek i przynajmniej jedna litera
- (?=.[A-Z]) – cokolwiek i przynajmniej jedna duża litera
- (?=.[a-z]) – cokolwiek i przynajmniej jedna mała litera
- (?=.[0-9]) – cokolwiek i przynajmniej jedna cyfra
- (?=)^.[|!@#’$%&\/()\?\^\’\+-*]) – cokolwiek i przynajmniej jeden wymieniony znak
Przykład 4. wyszukanie IP
Pracując dla cyber miałem okazję troszkę lepiej zrozumieć jak działa sieć czy routery. I okazało się, że z samego adresu IP można wywnioskować wiele ciekawych informacji (np. dostawcę internetu, czy użytkownik korzysta z VPN, przybliżoną lokalizację itp. itd.). Zatem możemy skonstruować wyrażenie regularne odpowiadające za wyszukanie IP:
df = pd.DataFrame(['0.0.0.0',
'54.239.128.212',
'256.256.256.256',
'1.a.255.255',
'A to ukryte IP w tekście (89.78.209.42).',
'Można ukryć np. dwa IP: (89.78.209.42) i 1.2.3.4'
],
columns=['ip'])
ip_pattern = "(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}\
(?:25[0-5]|2[0-4]\d|[01]?\d\d?)"
df['ip_found'] = df['ip'].apply(lambda x: re.findall(ip_pattern, str(x)))
df

Wyrażenie regularne – konstrukcja:
- (?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?).){3} – odpowiada za znalezienie liczby od 0 do 255 trzy razy podzielonych kropką
- (?:25[0-5]|2[0-4]\d|[01]?\d\d?) – odpowiada za znalezienie ostatnich 3 liczb
Życzę powodzenia w wykorzystaniu Waszych regexpów w praktyce!
Pozdrawiam serdecznie z całego serducha,

Obraz cocoparisienne z Pixabay