


– Cześć tato! Co dzisiaj robiłeś w pracy?
– Hej dziewczyny! Ha! Napisałem mój pierwszy autoenkoder!
– Autoco? A co to?
– Hmm… ostatnio już nauczyliśmy się wszystkich cyferek, prawda?
Wziąłem kartkę i napisałem dwa ciągi liczb. Następnie zapytałem Jagódki:
– Który zestaw cyfr jest łatwiejszy do zapamiętania?


– Ten pierwszy, ponieważ jest mniej cyfr.
– A Tobie Otylko, co łatwiej zapamiętać?
– Piciu.
– Tato! Oti ma dopiero dwa latka, nie męcz jej – powiedziała Jagódka.
– Ok, a gdybyś zobaczyła pewną regułę, że do co drugiej cyfry dodajemy jeden, a co druga cyfra to na zmianę 4 i 5?

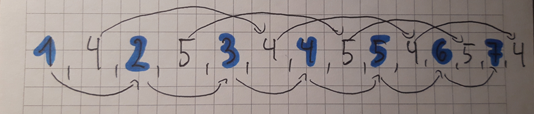
– Ojej. Rzeczywiście.
– I to jest jedno z wielu zastosowań autoenkoderów. Pomaga nam znajdować pewne wzorce.
W rzeczywistości, gdyby wkuwanie „na blachę” było łatwe, to możliwe, że autoenkodery* nie zostałyby tak szybko wymyślone. Choć obecnie mają już o wiele szersze zastosowania niż tylko ułatwienie wkuwania 😛
*) Zauważyłem, że w języku polskim wymienne stosowane są nazwy autoenkoder i autokoder. Bliższa jest mi dłuższa nazwa (jak w języku angielskim) i ją będę stosował.
Czym są autoenkodery?
Autokodery (ang. autoenkoders) patrzą na dane wejściowe, przekształcają je w pewną reprezentację wewnętrzną, a potem odtwarzają wynik przypominający dane otrzymane na wejściu.
Dokładniej, to autoenkoderami nazywamy sieci neuronowe zdolne do uczenia się reprezentacji danych wejściowych (kodowań).
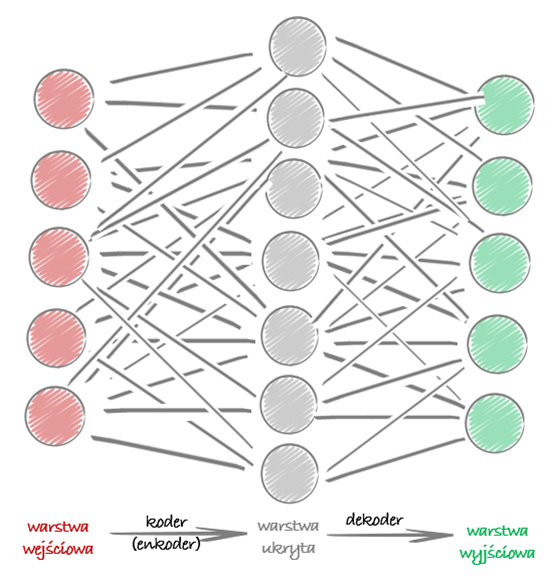
Autoenkodery zawsze składają się z dwóch elementów:
- kodera (ang. encoder), który przekształca dane wejściowe do postaci reprezentacji,
- dekodera (ang. decoder), który przekształca dane z postaci reprezentacji do danych wyjściowych.


Powyższy przykład pokazuje, że mając 5 cech (warstwa wejściowa) przekształcamy je w 3 (warstwa ukryta), a następnie odkodujemy znów 5 (warstwa wyjściowa). Dane na wyjściu też czasami nazywa się rekonstrukcjami, gdyż dekoder stara się je odtworzyć (zrekonstruować).
Funkcja straty (nazwana też stratą rekonstrukcji) ma za zadanie karać, jeśli rekonstrukcje zbyt mocno różnią się od danych wejściowych. Zarówno w przykładzie z rozmowy z Jagodą jak i tutaj dobrze widać, że aby zmieścić informacje z tych 5 cech tylko w 3 neuronach ukrytych, to trzeba poszukać jakichś wzorców. Dobra reprezentacja pośrednia może nie tylko wychwycić ukryte zmienne, ale także zapewnia pełny proces dekompresji.
Zauważcie, że autoenkodery mają podobną architekturę do MLP (ang. Multi Layer Perceptron, czyli perceptronu wielowarstwowego), która na wyjściu ma taką samą liczbę warstw jak na wejściu.
W przypadku zaimplementowania niepełnego autoenkodera (kodera bez dekodera) otrzymujemy sposób na redukcję wymiarów.
Jakie są rodzaje autoenkoderów?
Najczęściej wyróżnia się dwa rodzaje autoenkoderów:
- niedopełniony (undercomplete) – ma strukturę jak powyżej, czyli liczba warstw ukrytych jest mniejsza niż danych wejściowych. Wymusza to na nim, że nie może po prostu skopiować danych i przekazać ich dalej, a musi poszukać jakiegoś sposobu, aby mimo wszystko odtworzyć dane na wyjściu.
- przepełniony (overcompleted) – a czy może być więcej warstw ukrytych niż wejściowych? Dlaczego nie! Dzięki temu możemy uzyskać więcej cech. Natomiast trzeba oszukać autoenkoder, bo mając więcej warstw ukrytych mógłby się nauczyć, aby zawsze przekazywać wartość do kolejnego węzła ukrytego a kilka pozostawić pustych. Z tego powodu nie będzie żadnym dodatkowym „feature extraction”.

Pamiętajmy, że autoenkodery, które potrafią w 100% zrekonstruować dane uczące nie nauczą się żadnej przydatnej reprezentacji danych.
Jak działają autoenkodery?
Osoby, które nie do końca rozumieją jak działa sieć neuronowa odsyłam do wcześniejszego artykułu na ten temat. Z tamtą wiedzą niewiele trzeba będzie tutaj tłumaczyć.
Dane na wejściu (warstwa wejściowa) przechodzą przez warstwy ukryte i na wyjściu mamy taki sam rozmiar. Enkoder w tym przypadku koduje dane do mniejszej liczby warstw po to, aby wyłapać pewne zależności a następnie dekoduje do warstwy wyjściowej o tym samym rozmiarze.
W kolejnym kroku liczony jest błąd (różnica pomiędzy daną wejściową, a tym co otrzymaliśmy) i wykorzystując algorytm propagacji wstecznej poprawiane są wagi w sieci.


Tak naprawdę w autoenkoderach nie interesuje nas aż tak bardzo wyjście, ponieważ jest ono repliką danych wejściowych, ale warstwa ukryta, która powinna zawierać wystarczającą ilość informacji, by móc odtworzyć dane wejściowe.


Jakie są główne zastosowania autoenkoderów?
- redukowanie wymiarowości – tak jak pewnie zauważyliście na wcześniejszym obrazku, gdy liczba neuronów w warstwie ukrytej jest mniejsza niż liczba danych wejściowych, to sieć musi jakoś informacje upchać w mniejszej liczbie neuronów. Zatem jest to jeden ze sposobów na redukcję wymiarów, o której pisałem już wcześniej.
- do klasyfikacji – możemy jako dane wejściowe wrzucić dane tylko z jednej klasy, aby nauczyć autoenkoder rekonstruować daną klasę. Następnie możemy sprawdzać jak mocno błąd wynikający z rekonstrukcji różni się od danych wejściowych, aby sprawdzać, czy to jest dana klasa.
- wykrywanie anomalii – anomalie z definicji występują bardzo rzadko. Zatem trenując autoenkoder na całym zbiorze danych nie powinien nauczyć się rekonstruować anomalii i można je prosto wykryć.


- generowanie nowych cech – można stworzyć autoenkoder z większą liczbą warstw ukrytych, z których można uzyskać więcej cech,
- generowanie nowych danych przypominających zbiory danych uczących – dodając np. odpowiednio szumy losowe w środkowej warstwie ukrytej,
- systemy rekomendacyjne – ucząc się reprezentacji jak klienci np. oceniali dane filmy,
- i wiele innych… 🙂
Najbardziej znane autoenkodery
Autoenkodery stosowe lub głębokie
Autoenkodery tak jak sieci mogą składać się z wielu warstw ukrytych. Celem dodawania kolejnych warstw jest wyuczenie się bardziej skomplikowanych zależności czy kodowań.
Autoenkodery składające się z dwóch warstw ukrytych nazywamy stosowymi:


Natomiast autoenkodery składające się z więcej niż 3 warstw ukrytych nazywamy głębokimi.


W przypadku głębokich autoenkoderów najczęściej stosuje się symetryczną architekturę tzw. „kanapkę” zmniejszając kolejną liczbę warstw ukrytych o połowę.
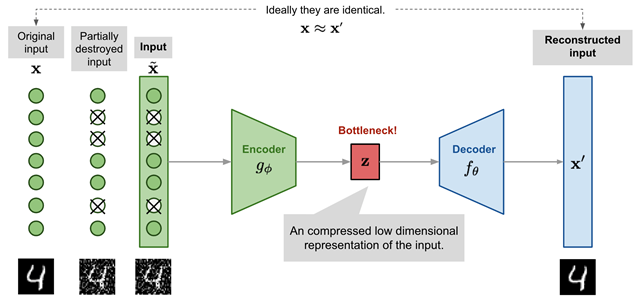
Autoenkodery odszumiające (ang. denoising autoencoders)
Inną ciekawą metodą do wydobywania cech i aby uniknąć nadmiernego dopasowania autoenkodera do danych jest dodanie szumu lub zamaskowanie niektórych wartości wektora wejściowego w sposób stochastyczny. Następnie model jest trenowany do odzyskiwania oryginalnych danych wejściowych (uwaga: tych nie uszkodzonych bez dodanego szumu). Pierwsze koncepcje wykorzystywania autoenkoderów do odszumiania sięgają lat 80. Natomiast bardziej znana jest praca naukowa Pascala Vincenta z uniwersytetu w Montrealu w Kanadzie, który pokazał w 2008 roku, że autoenkodery są super narzędziem do wydobywania.

Autoenkodery rzadkie (ang. sparse autoencoders)
Rzadkie autoenkodery nakładają ograniczenie w funkcji aktywacji warstw ukrytych, aby uniknąć nadmiernego dopasowania i poprawić odporność. Ten rodzaj autoenkodera pozwala jedynie na aktywację tylko niewielkiej liczby ukrytych jednostek w tym samym czasie. Mówiąc inaczej jeden ukryty neuron powinien być nieaktywny przez większość czasu.
Po co to jest robione? Wymuszając, aby w warstwie ukrytej występowało np. tylko 5% aktywnych neuronów powodujemy, że warstwy kodowania uczą się wykrywać tylko najprzydatniejsze cechy. To tak jakbyśmy w ciągu tygodnia mogli powiedzieć do swoich dzieci tylko 7 słów – musiałyby być bardzo ważne 🙂
Działają mniej więcej w ten sposób, że najpierw oblicza się średnią aktywację każdego neuronu (czyli dla wszystkich naszych danych ile razy został włączony). Następnie nakładana jest kara na zbyt aktywne neurony poprzez dodanie straty rzadkości (ang. sparcity loss) do funkcji straty. To czy dodać tę stratę mierzy się za pomocą dywergencji Kullbacka-Leiblera (KL). Za pomocą hieperparametru β kontroluje się siłę kary, jaką chcemy nałożyć na utratę rzadkości. Jeśli kara będzie za duża, to model będzie blisko wartościom rzadkim, ale jednocześnie nie będzie umiał rekonstruować danych wejściowych, poprzez co może stać się bezużyteczny.
Autoenkodery kurczliwe (ang. contractive autoencoders)
Podobnie jak rzadki autoenkoder modyfikuje funkcję straty, tylko w ten sposób, aby ukarać reprezentację zbyt wrażliwą na dane wejściowe. Tym samym poprawia odporność na małe zaburzenia wokół punktów danych treningowych.
Mówiąc inaczej – dwa podobne do siebie przykłady wejściowe muszą mieć podobne kodowania.
Autoenkodery wariacyjne (ang. variational autoencoders)
Idea stojąca za autoenkoderami wariacyjnymi (w skrócie VAE) została opisana w 2014 przez Diederika Kingma oraz Max Welling (link do pracy naukowej).
VAE należą do klasy autoenkoderów generatywnych, czyli takich, które umieją tworzyć nowe dane przypominające te w zbiorze uczącym.
Dodatkowo VAE są autoenkoderami probabilistycznymi, czyli generują częściowo losowe wyniki nawet po wyuczeniu modelu.
Powiedziałbym, że mają standardową architekturę autoenkoderów: po koderze składającym się często z kilku warstw ukrytych mamy dekoder. Natomiast mamy tutaj drobną zmianę: koder nie generuje bezpośrednio naszych danych wejściowych. VAE koduje dane wejściowe na dwie części: wartość średnia – μ i odchylenie standardowe – σ przetworzonych danych wejściowych. Następnie próbkują, aby utworzyć próbkowany wektor kodowania, który jest przekazywany do dekodera.
Inaczej można powiedzieć, że standardowy autoencodera daje wektor, który „wskazuje” zakodowaną wartość w utajonej przestrzeni, podczas gdy VAE tworzy wynik wskazujący na „obszar”, w którym zakodowana wartość może być przedstawiona. Średnia wartość kontroluje punkt, w którym znajduje się środek kodowania, a odchylenie standardowe określa „obszar”, w którym kodowanie może różnić się od średniej.


Autoenkodery antagonistyczne (ang. adversarial autoencoders)
Autoenkoder zaproponowany przez Alireza Makhazani w 2016 roku. Idea polega na tym, że jedna sieć jest uczona rekonstruowania danych wejściowych, a jednocześnie druga sieć uczy się wyszukiwać dane, których pierwsza sieć nie jest w stanie poprawnie rekonstruować. Dzięki temu pierwsza sieć będzie uczyć się różnych kodowań.
… i to jeszcze nie wszystkie.


Mam nadzieję, że troszeczkę odczarowałem autoenkodery! A w przyszłości postaram się pokazać, jak wykorzystać jakiś w praktyce i zgłębić bardziej niektóre z nich.
Pozdrawiam serdecznie,

