
-Tato, a jak to jest, że ten telefon wykrywa uśmiechy? – zapytała mnie Jagódka.
-To zasługa mądrych głów, które rozwijają dziedzinę zwaną Computer Vision.
Jak tylko to powiedziałem już widziałem w jej wzroku, że nie ma pojęcia o czym mówię.
– Czyli Ci naukowcy tak naprawdę wymyślają coraz to lepsze sposoby, aby maszyny nas widziały i rozumiały przez swoje oczka.
– Aaa, czyli kamerki? – zapytała z uśmiechem znając już odpowiedź na to pytanie.
– Dokładnie Skarbie.
– A czy widzą lepiej niż ja? – zapytała zaniepokojona.
– Hmm… wydaje mi się, że widzą o wiele lepiej pojedyncze rzeczy. Natomiast jeszcze sporo przed nimi, aby widzieć i rozumieć świat tak jak Ty go widzisz Księżniczko.
W dzisiejszych czasach jesteśmy przytłoczeni ogromną ilością zdjęć i filmów. Na każdym kroku znajdują się reklamy, które atakują przede wszystkim nasz zmysł wzroku.
Większość z nas ma w kieszeni smartfony ze świetnymi aparatami fotograficznymi, które są ciągle pod ręką, kiedy chcemy zrobić zdjęcie lub nagrać film. Tak prosty dostęp do nowoczesnych technologii wpłynął na rozwój mediów społecznościowych (facebook, instagram, tic-tok itp.), gdzie mnóstwo ludzi dzieli się swoim życiem.
W zaledwie jedną minutę oglądanych jest 4.5 mln filmów na YouTube i wysyłanych jest 4.8 mln gifów!

Obecnie nie ma najmniejszego problemu, aby wyszukać obraz podobny do innego obrazu. Natomiast kilka lat temu nie był to błachy problem. Całe wyszukiwanie filmów czy obrazów opierało się jedynie o dane z opisu wpisanego przez osobę udostępniającą zdjęcie lub film.
Zatem, aby jak najlepiej wykorzystać potencjał drzemiący w danych zapisanych w obrazach, należało nauczyć komputery widzenia i rozumienia obrazów.
Natomiast to, co dla nas ludzi jest banalnie proste, dla komputerów już takie nie było. Każdy dwulatek jest w stanie rozpoznać, że dany przedmiot to „autko” lub „kotek”, mimo że takiego samego nie widział wcześniej. Fajnie wpisuje się w to paradoks Moraveca, który mówi mniej więcej tyle, że:
Wbrew tradycyjnym przeświadczeniom, wysokopoziomowe rozumowanie wymaga niewielkiej mocy obliczeniowej, natomiast niskopoziomowa percepcja i zdolności motoryczne wymagają olbrzymiej mocy obliczeniowej.
I rzeczywiście komputery wcześniej nauczyły się wygrywać w szachy czy warcaby niż rozpoznawać przedmioty na zdjęciach.

Czym jest computer vision (wizja komputerowa)?
Aby rozwinąć temat wizji komputerowej przeanalizujmy najpierw składowe tego terminu 🙂
„Komputer” można prosto zdefiniować jako maszynę elektryczną, która jest zdolna do wykonywania obliczeń, procesów i operacji zgodnie z instrukcją dostarczoną przez program lub sprzęt.
„Widzenie” możemy zdefiniować jako zrozumienie środowiska poprzez zobaczenie w tym środowisku obiektów.

Zatem łącząc te dwa terminy można powiedzieć, że widzenie komputerowe (computer vision) to proces, w którym maszyna lub system generuje zrozumienie informacji wizualnych.
A więc przez computer vision (w skrócie CV) rozumiemy nie tylko zdolność widzenia obrazów (wzroku), ale również naśladowanie percepcji – zdolności ludzi do zrozumienia tego, co widzą.
Zatem „systemy wizyjne” będą składać się z dwóch elementów: czujnika obrazu oraz tłumacza. Pierwszą myślą odnośnie „oczu” dla komputerów są kamery. Natomiast w rzeczywistości jest mnóstwo sprzętu, który służy do rejestrowania informacji o prawdziwym świecie: kamery, kamery termowizyjne, zdjęcia satelitarne, mapy, rentgeny, skanery, radary…
Kiedy nastąpił rozkwit computer vision?
Algorytmy związane z przetwarzaniem obrazów są znane od lat 60. ubiegłego wieku. Oczywiście były to proste zadania polegające na rozpoznaniu podstawowych figur geometrycznych na obrazach, np. czy to stożek czy sześcian.
Natomiast aktualny rozkwit CV można zawdzięczać przede wszystkim dwóm zdarzeniom:
- wygrana metody bazującej na konwulcyjnych sieciach neuronowych (convolutional networks) w 2012 roku podczas konkursu ImageNet na najlepszy system rozpoznający obiekty na obrazach,
- rozwój sprzętu do gier komputerowych czyli karty graficzne – coraz lepsze maszyny umożliwiły trenowanie głębokich sieci neuronowych na coraz większych zbiorach treningowych.
Poniżej możecie zobaczyć, jak algorytmy i modele stają się z roku na rok coraz lepsze analizując obrazy już lepiej niż człowiek.
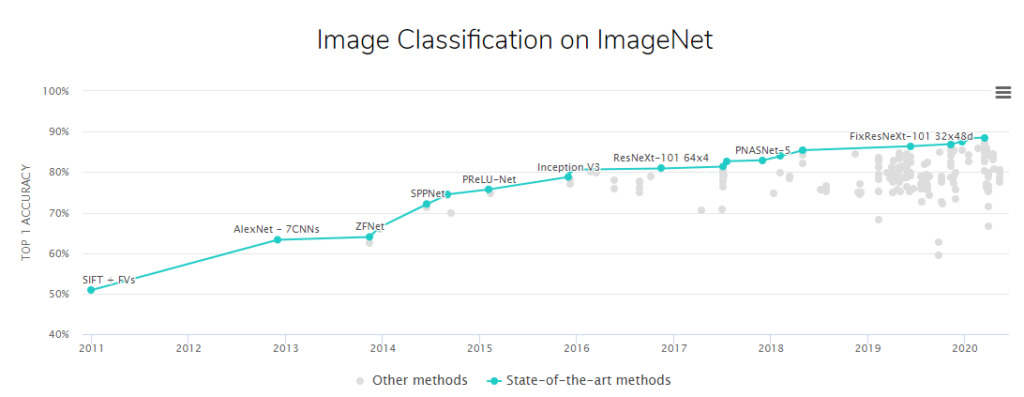

Jak maszyny interpretują obraz?
Maszyny interpretują obrazy w bardzo prosty sposób – jako serię pikseli, każdy z własnym zestawem wartości kolorów. Zobaczcie uproszczone zdjęcie Lincolna, gdzie przypisano kolorowi piksela cyfry a następnie zamieniono je na tablicę (podobną ilustrację pokazałem na przykładzie buta w TYM artykule)
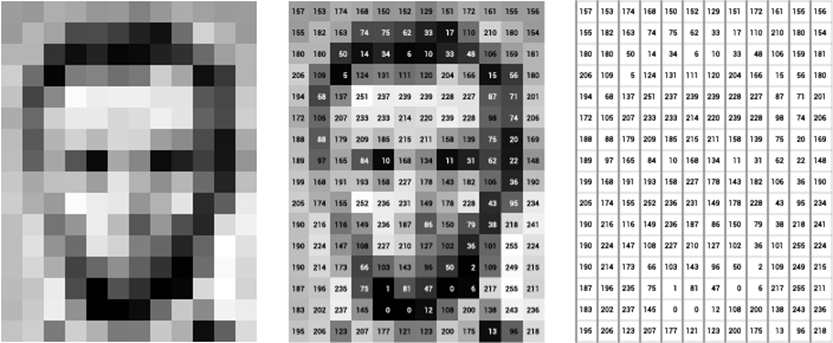
Wystarczy wyobrazić sobie, że obraz to olbrzymia siatka pikseli, którym przyporządkowane są liczby. W tym przypadku otrzymujemy macierz 12 x 16 = 192 wartości.
Komputery najczęściej rozumieją kolory jako serię 3 wartości – RGB (Red Green Blue). Zatem jeśli chcemy mieć kolorowy obraz, to zamiast jednej powyższej macierzy musimy mieć takie 3 x 192, z których każda odpowiada za jeden kanał.

Warto zwrócić uwagę, że przetwarzanie wielu zdjęć dobrej jakości może trwać bardzo długo. Większość smartfonów ma obecnie możliwość robienia zdjęć w maksymalnej jakości 12 mln pikseli. Każdy piksel to 8 bitów razy 3 kanały, co daje około 384 mln bitów, czyli około 45 MB!
Główne zastosowania computer vision
Wizja komputerowa to szeroka nazwa dla wszelkich obliczeń i algorytmów związanych z obrazem. Ale w ramach tego zagadnienia istnieje kilka konkretnych zadań, które są podstawowymi elementami składowymi.
Klasyfikacja obrazu (image classification)
Odpowiada na pytanie: do jakiej kategorii możemy przypisać przedmiot na zdjęciu. Poniżej przykład, gdzie wyświetlone jest top 5 klas o najwyższych prawdopodobieństwach.

Identyfikacja (identification)
Odpowiada na pytanie: jaki typ danego obiektu znajduje się na obrazie? Jest to znacznie dokładniejsza klasyfikacja dla pojedynczego obiektu. Najlepszym przykładem może być identyfikacja twarzy lub odcisku palca konkretnej osoby czy też odczytanie tablic rejestracyjnych pojazdu.

Detekcja obrazu (object detection)
Odpowiada na pytanie, gdzie jest dany obiekt na zdjęciu / video. Jest to technika wizyjna do wykrywania i klasyfikowania obiektów na obrazach lub filmach. Wykorzystywana jest często do znajdowania interesujących nas fragmentów na obrazach, które mogą być dalej analizowane za pomocą bardziej wymagających obliczeniowo technik w celu uzyskania poprawnej interpretacji.

Segmentacja semantyczna (sematic segmentation)
Segmentacja semantyczna lub segmentacja obrazu to zadanie grupowania części obrazu, które należą do tej samej klasy obiektów. Jest to forma przewidywania na poziomie pikseli, ponieważ każdy piksel na obrazie jest klasyfikowany zgodnie z kategorią. Odpowiada na pytanie, który piksel należy do którego obiektu na obrazku.

Tworzenie obrazów (Image generation)
Generowanie obrazu polega (jak sama nazwa wskazuje :D) na generowaniu nowych obrazów z istniejącego zestawu danych. W ostatnim roku bardzo na topie w związku z rosnącą skalą „deep fake”.

Transfer stylów (style transfer)
Transfer stylu to zadanie zmiany stylu obrazu w jednej domenie na styl obrazu w innej domenie. Mnie osobiście bardzo interesuje zagadnienie prawne, czy po wykorzystaniu zmiany stylu znanego malarza mogę prawnie sprzedawać nowe dzieła sztuki :). Jeśli znacie odpowiedź to dajcie znać w komentarzu.

Oszacowanie pozy (pose estimation)
Oszacowanie pozy jest ogólnym problemem w Computer Vision, w którym wykrywamy pozycję i orientację obiektu względem kamery. Przykładem zastosowania może być wykrywanie czy klient w sklepie bierze produkt z półki i wkłada go do koszyka albo czy prawidłowo wykonujemy jakeś ćwiczenie np. brzuszki.

i wiele innych…

Computer Vision vs Image Processing
Wizja komputerowa i przetwarzanie obrazu są powiązane, ale różnią się od siebie. Przetwarzanie obrazu jest procesem tworzenia nowego obrazu z już istniejącego ze zmianą jego zawartości. Jest to tak naprawdę sposób przetwarzania sygnału bez potrzeby rozumienia treści obrazu.
Przykładem przetwarzania może być:
- rozmazanie,
- zmiana kolorów (np. normalizacja),
- wyostrzanie krawędzi,
- kadrowanie,
- usuwanie szumów cyfrowych itp.
Oczywiście przy projektach computer vision bardzo często będziemy korzystać z przetwarzania obrazów np. do poprawiania jakości zdjęć lub zmniejszenia rozmiarów, aby algorytmy szybciej się uczyły.
Podsumowanie
Działka computer vision jest bardzo interesująca i z roku na rok powstają nowe lepsze metody na rozwiązanie problemów. Mam nadzieję, że będziemy mieli wszyscy okazję przygotowania ciekawych projektów w tych tematach.
Pozdrawiam serdecznie,




Pingback: Dale-E2 vs MidJorney vs Stable Diffusion - Mirosław Mamczur
Pingback: Wykrywanie kolorów w OpenCV. Stwórz samemu "płaszcz niewidkę"! - Mirosław Mamczur
Pingback: Wykrywanie twarzy real-time w 15 liniach kodu w Python - Mirosław Mamczur